Approximately 20% of the websites you need to scrape use Cloudflare, a robust anti-bot protection system that can easily block you. Indeed is among the sites protected by Cloudflare's anti-bot system, featuring its well-known "Verify you are human" or "Additional Verification Required" challenge backed by CAPTCHA solving flows. Sites at this scale often sit behind Akamai or similar CDNs as well. In this article, we will explore possible solutions to bypass their anti-bot measures and successfully scrape jobs and company pages. For the legal side, see Is Web Scraping Legal or Illegal? before running production scrapers.
Overview of Indeed scraping
Indeed is structured into several sections :
- Search results pages
- Job listing pages
- Company profile pages
What is data scraping?
Data scraping, or "web scraping," refers to the automated extraction of data from a website through software or scripts. This process enables companies to collect large amounts of information quickly, which may include job listings, company details, and even user profiles. For example, data scraped from Indeed can be valuable for analytics, recruitment, and competitive research but must adhere to strict legal frameworks.
Understanding the importance of data scraping on Indeed
Data scraping allows businesses and researchers to gather valuable information from Indeed’s platform, such as job trends, salaries, skill requirements, and employer data. This data helps in making informed decisions, driving market research, and creating innovative services.
How do companies use the data they recover?
Companies use scraped data to track industry trends, analyze competitors, enhance recruitment strategies, and create job market insights. This data empowers organizations to optimize hiring practices, build data-driven products, and understand market demands more effectively. Scraping data from Indeed requires a strategic approach due to the platform’s structure and the protections it has in place, such as Cloudflare’s anti-bot measures. Understanding how Indeed is organized and how to bypass these security protocols will help you collect the data you need efficiently.
Method 1 : Exploring the process of web scraping
Main steps in creating a web scraper for Indeed
- Determine your objectives
Clearly define the data you wish to extract from Indeed. This could include job titles, location / locations, salaries, or company names. Providing specific details will facilitate the development of an efficient web scraper and prevent unnecessary data collection. - Analyze job page elements : Utilize browser developer tools to examine the structure of the job or company page. By identifying the relevant HTML elements, you can locate and extract the required text from the search results.
- Deal with Cloudflare Protection : Indeed employs Cloudflare's anti-bot protection, which can hinder scraping attempts. To overcome these protections, tools like
Cloudscraper,FlareSolverr,Cfscrape, or other Cloudflare solvers can be advantageous. These tools emulate human browsing behaviors and assist the web scraper in overcoming CAPTCHA challenges and other bot detection mechanisms. - Dev your web scraper : Utilize Python libraries such as
Beautiful Soup,Scrapy, orCheerio,lxmlto develop your web scraper. These libraries assist in navigating Indeed's webpages, parsing the HTML, and extracting the desired data/text/images. - Manage rate limits : Scraping websites too rapidly can trigger anti-bot protections. To avoid being blocked, incorporate rotating proxies and implement request delays to mimic human browsing patterns. This will help you collect large amounts of data while remaining undetected.
- Parse and clean data : After extracting the data, cleanse and structure it for further analysis. Eliminate any unnecessary characters, format the job data.
- Data storage : Once the data has been cleansed, store it in an efficient format, such as a database with Postgres (Supabase, Airtable...) or a CSV file. This will facilitate analysis, visualization, or further processing according to your requirements. Regular Maintenance : Scraping necessitates ongoing maintenance. Regularly monitor and update your web scraper to adapt to changes in Indeed's webpage structure, content updates, and evolving security protocols, including Cloudflare's defenses.
Understanding Cloudflare Bot Management
Cloudflare provides content delivery and web security services, including its Web Application Firewall (WAF), which safeguards websites against threats like cross-site scripting (XSS), credential stuffing, and Distributed Denial of Service (DDoS) attacks.
A vital component of Cloudflare is the Bot Manager, designed to protect websites from malicious bot traffic. The Bot Manager identifies and mitigates bot attacks without disrupting legitimate users. However, Cloudflare considers any unknown or non-whitelisted bot traffic, such as web scrapers, to be malicious. Therefore, even legitimate scraping attempts may be blocked, leading to the denial of access to Cloudflare-protected websites.
These errors are often accompanied by a Cloudflare 403 Forbidden HTTP response status code, indicating that the request was blocked due to suspected bot activity. To bypass these protections, specific Cloudflare solvers or techniques such as rotating proxies, mimicking human behavior, or using headless browsers may be required.
A bad example of python scraper job
The following code snippet shows an example of an HTTP request and parsing method intended to extract job data from Indeed using Python libraries such as httpx and re:
import httpx
import re
import json
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
}
def parse_search_page(html: str):
data = re.findall(r'window.mosaic.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});', html)
if data is not None and data != 'null':
return json.loads(data[0])
response = httpx.get("https://www.indeed.com/viewjob?jk=cbce6eaf017aa47b", headers=headers)
print(parse_search_page(response.text))
This request fails, as Indeed’s website employs anti-bot protections, notably through Cloudflare, which blocks HTTP requests that don’t simulate human behavior. Libraries like httpx or requests are generally ineffective against these protections. To bypass Cloudflare, you need tools such as headless browsers or dedicated web scraper APIs that can mimic human interactions more reliably.
Method 3 : Web scraping API to bypass Cloudflare
While the techniques mentioned in this article can be helpful, they cannot guarantee success at all times due to Cloudflare frequently updating its security measures. The most reliable way to deal with Cloudflare is to use a web scraping API, like Piloterr. It handles all of Cloudflare's detection methods behind the scenes, allowing you to focus on your scraping logic without worrying about bypassing bot protection.
Piloterr works with all programming languages. You only need a single API call to bypass Cloudflare and retrieve the data you need.
To see how Piloterr works, let’s use it to access Indeed Jobs, a website heavily protected by Cloudflare.
Python code :
# Install the requests module if needed
import requests
# Indeed URL
url = 'https://www.indeed.com/jobs?q=senior+java+developer&l=berlin'
api_key = ''
# Request parameters for the Piloterr API
params = {
'query': url,
'wait_in_seconds': 10
}
# Sending a GET request to the Piloterr API
response = requests.get(
'https://piloterr.com/api/v2/website/rendering',
params=params,
headers={'x-api-key': api_key}
)
# Printing the raw HTML of the Indeed page
print(response.text)
With this request, you can get all the jobs that have the keyword “Senior Java Developer” in the location “Berlin”.
Check out the documentation to see how to configure the scraping request. Simply paste the target URL, add a wait_in_seconds between 5-20 seconds. you'll be able to use a simple request HTTP to search for jobs (and bypass the Cloudflare anti-bot), scrape URLs and text without any headaches.
Method 4 : Scrape URL Company on Indeed with Python
If you're interested in scraping company data on Indeed, Piloterr offers a dedicated web scraping API to make the process straightforward and efficient. By using this API, you can bypass Cloudflare’s protection seamlessly and obtain structured JSON data about companies on Indeed.
Use-case : scrape company information with python
To retrieve company information for a specific company on Indeed, follow these steps:
- Choose the Company: Find the company URL on Indeed (e.g., https://indeed.com/cmp/Microsoft).
- API Call: Use a GET request to Piloterr’s dedicated endpoint for Indeed company info.
Python code :
import requests
# Define the API URL for company information
url = 'https://indeed.com/cmp/Microsoft'
api_key = ''
# Set the API endpoint and parameters
api_endpoint = 'https://piloterr.com/api/v2/indeed/company/info'
params = {'query': url}
# Send the GET request with the API key
response = requests.get(api_endpoint, params=params, headers={'x-api-key': api_key})
# Print the JSON response containing the company data
print(response.json())
Response :
{
"founded": 1975,
"revenue": "over-$10B (USD)",
"website": "http://www.microsoft.com/",
"industry": "Information Technology",
"logo_url": "https://d2q79iu7y748jz.cloudfront.net/s/_squarelogo/96x96/88813b3f866a5b58c9685073e3b87e05",
"company_url": "https://indeed.com/cmp/Microsoft",
"description": "There’s work, and then there’s your life’s work...",
"headquarter": "One Microsoft Way Redmond, Washington 98052-6399",
"staff_range": "over-10000",
"company_name": "Microsoft",
"dynamic_sections": {...},
"similar_companies": {...}
}
- Process the JSON: The response will include the company's information in JSON format, making it easy to analyze text and incorporate into your applications.
By using this endpoint, you save time, as the response is already structured in JSON, allowing for smooth integration with your scraping logic without needing to parse raw HTML.
Note: It doesn't contain URLs and Jobs, this API endpoint focuses on company information. Some fields in the JSON response may be null if the information is not available or if Indeed has restricted access to certain data. Ensure your python code handles these cases to avoid potential errors in data processing.
Using this endpoint saves time, as the response is already structured in JSON, allowing smooth integration with your scraping logic without needing to parse raw HTML text. Refer to Piloterr’s documentation for additional options to optimize your requests, such as specifying the wait time in seconds, search parameters, or adjusting user-agent headers to improve response quality.
With Piloterr, you can also scrape job listings directly from company profiles on Indeed, such as this URL: indeed.com/cmp/Google/jobs. Indeed Job Scraper allows you to extract valuable job data, including job title, description text, company name, location, salary, ratings, employment type, and more.
Scrape Indeed's company data
Here are some valuable use cases:
1. Salary Analysis & Benchmarking / using the salary data from job listings, you can:
- Compare compensation across different roles and locations
- Track salary trends for specific positions
- Help job seekers negotiate better packages
For example, from the data we can see Microsoft's Software Engineer salaries range significantly based on location and experience level.
2. Job Market Intelligence / the data provides insights into:
- Hot job titles and their demand (e.g., Microsoft has 339 Software Development positions)
- Geographic or location distribution of opportunities (e.g., Redmond, WA has 438 openings)
- Company hiring trends and focus areas
3. Career Path Planning / the structured job title data can be used to:
- Map career progression paths
- Identify required skills for advancement
- Compare roles across companies (e.g., Senior Program Manager vs Project Manager positions)
4. Company Culture Analysis / using the review and rating data :
- Analyze workplace satisfaction (Microsoft's 4.2 overall rating)
- Compare work-life balance across companies
- Assess company values and employee experience
5. Interview Preparation / the interview data provides:
- Process duration insights ("about two weeks")
- Difficulty levels (rated as "MEDIUM")
- Common interview questions and experiences for a job
- Location-specific interview feedback
6. Competitive Intelligence / companies can:
- Monitor competitor hiring patterns
- Compare benefits and compensation for a job
- Track expansion into new markets or technologies
- Analyze similar companies in their sector
This data can be particularly valuable for HR professionals, job seekers, and business analysts looking to make data-driven decisions about employment and workforce trends.
Method 5 : Using Google cache alternatives
While Google no longer offers access to cached pages, you can still view archived versions of many websites through services like WebCite and the Internet Archive. These sites provide snapshots of web pages, allowing you to access content from protected sites without directly visiting their domain or passing through Cloudflare’s CDN.
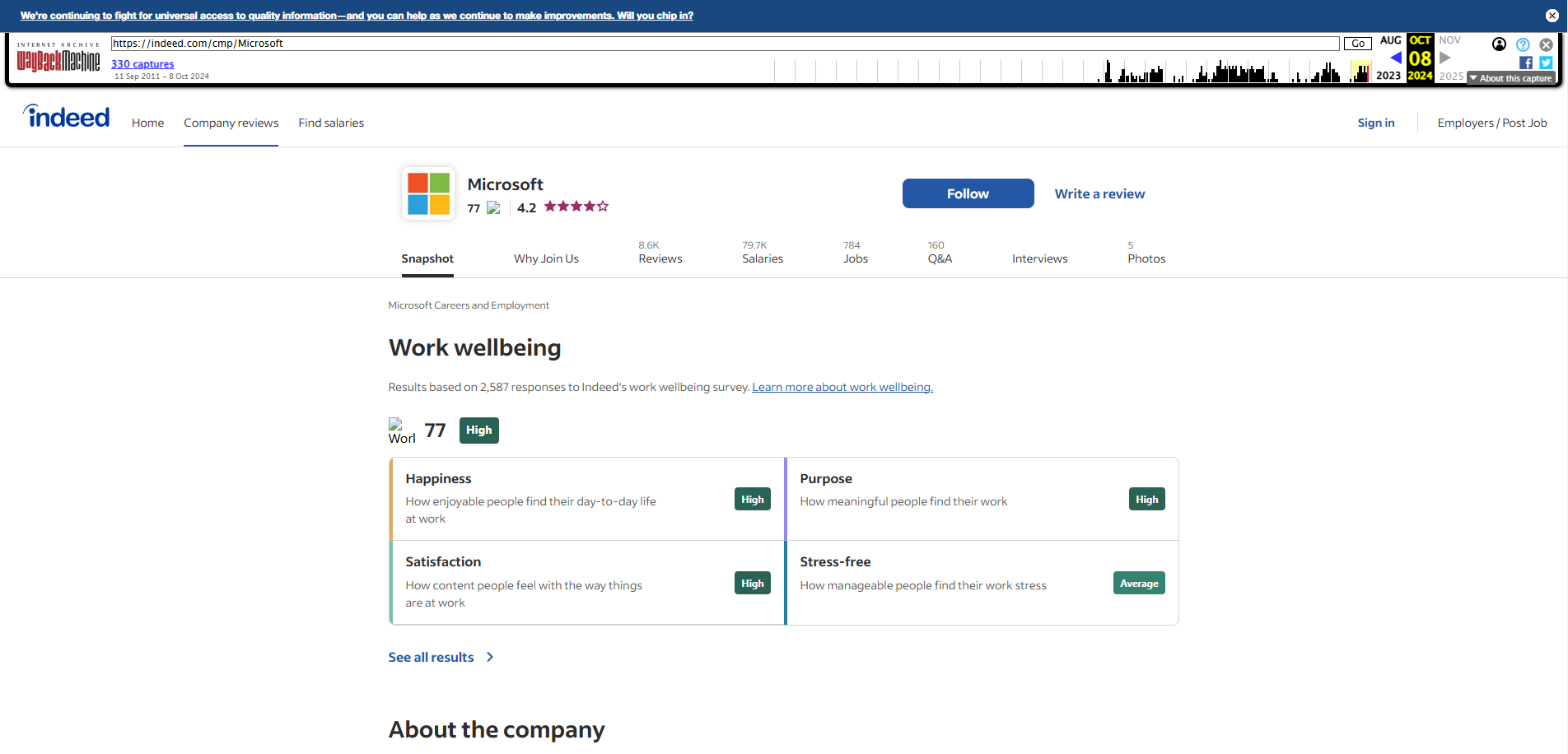
To use archives when other methods fail, here are a few steps to follow :
- Check data availability and freshness : Ensure that archived data is present and recent enough to meet your needs. Assessing relevance is crucial.**
- Assess the level of security : Consider whether the security of the archive is inferior to that of the original site. This could influence the security and integrity of the extracted data.
If these conditions are met, explore the archive of the target site to see if a cached version is accessible.
Method 6: Scrape job titles for developer positions with Python
If you need to automate the process of retrieving job title suggestions related to "developer," you can use a simple script to interact with the Indeed endpoint for autocomplete suggestions. This can help you gather a list of relevant titles that are frequently associated with developer roles, providing insights into similar or related positions.
You can use the following Python script to scrape and parse the text, extracting only the relevant job title suggestions:
import httpx
def get_job_title_suggestions(query="cto"):
url = "https://autocomplete.indeed.com/api/v0/suggestions/cmp-what-with-top-companies"
params = {
"country": "US",
"language": "en",
"count": 10,
"counts": 10,
"formatted": 1,
"query": query
}
response = httpx.get(url, params=params)
if response.status_code == 200:
suggestions = [item['suggestion'] for item in response.json() if item['suggestion'] != 'null']
return suggestions
else:
return []
# Retrieve CTO-related job titles
cto_suggestions = get_job_title_suggestions("cto")
print(cto_suggestions)
This script sends an HTTP request to the Indeed API and prints a list of suggested job titles related to "developer." This Indeed endpoint is not currently protected by Cloudflare, but it may become so.
Note: It is also possible to use the same approach to retrieve location suggestions from Indeed, providing a list of relevant cities. This can be particularly useful when developing a web application to help prevent null results for the client by populating search fields with valid options.
Does Indeed allow job scraping ?
The legality of data scraping is governed by legal and regulatory frameworks covering intellectual property and data protection. The Code of Intellectual Property regulates data extraction in terms of usage, quantity, and intent. Our full compliance guide is at Is Web Scraping Legal or Illegal?. Here's a summary of what is generally permitted:
- Non-Substantial Data Extraction: Extracting a small, non-substantial portion of publicly available data for private use is typically allowed. This approach ensures that users only collect minimal data, which does not compromise the database's value.
- Private, Non-Commercial Use: Extracting data on a larger scale might be acceptable if it’s for personal, non-commercial purposes. However, all intellectual property and privacy rights must be respected.
- Academic and Research Use: For educational or research purposes, a more substantial amount of data may be extracted. This use is typically non-commercial and directed at a limited audience, such as students or researchers, which minimizes the risk of infringing the platform’s terms.
Compliance with Indeed’s terms
Indeed's Terms of Service explicitly prohibit scraping activities for commercial use without authorization. They restrict the use of “bots, scripts, or APIs” to scrape data from their website, especially when the data is used for competitive purposes, profiling, or mass data collection.
Example clause: "You agree not to use any robot, spider, scraper, or other automated means to access the Indeed site for any purpose without Indeed's express written permission."
Violating these terms could result in legal action and hefty fines. Indeed retains the right to seek compensation for damages caused by unauthorized scraping, which can amount to significant financial and reputational losses for the offending company.
Can I use the Indeed API to scrape job postings?
As of June 2023, Indeed offers a range of APIs for developers free of charge. However, these APIs are primarily intended for the hiring side of the platform. They are useful for integrating Indeed with applicant tracking systems, tracking applicant conversions, or scheduling interviews, but they are not designed for job search purposes.
Previously, the Publisher Jobs API (including the Get Job and Job Search functions) was available specifically for job searches, allowing users to gather data such as job titles, company names, description text, locations and posting times. Since these APIs were deprecated, users have turned to alternatives, like an Indeed scraper, to access similar job search data.
Conclusion
In conclusion, data scraper on Indeed enables access to a wealth of valuable information, including jobs, companies, locations, and other useful details. Through the methods outlined, including using scraping APIs like Piloterr, it’s possible to extract text data from a simple URL while bypassing protections like Cloudflare. This approach provides businesses with critical insights to enhance recruitment strategies, competitive analysis, and market trend studies. However, it's crucial to comply with Indeed's terms of service to ensure a lawful use of this data.