Learn how to scrape Amazon using User-Agent headers to avoid detection and BeautifulSoup to parse HTML content. This comprehensive guide also includes a complete use case example that demonstrates the process of extracting product information, such as titles, prices, and ratings, using Python.
Skip the maintenance: use the Amazon Scraping API or Amazon Product API for structured JSON output.
Introduction to web scraping
What is Web Scraping?
Web scraping is a method used to automatically extract large amounts of content from websites. The primary goal of web scraping is to collect and structure information from the web, which can then be used for various applications. This content can include text, images, videos, and other forms of media available on web pages. By automating the extraction process, web scraping allows users to quickly read, search, and analyze web content, saving significant time and effort compared to manual data collection.
Tools and techniques
Several tools and techniques are employed in web scraping to ensure efficient data collection:
- HTML Parsing: This technique involves analyzing the structure of a web page to gather information. Tools such as a Python scraper and Cheerio (JavaScript) are commonly used for this purpose. They enable the navigation of the page structure and the retrieval of relevant details based on tags, attributes, and other elements.
- DOM Parsing: Document Object Model (DOM) parsing involves interacting with the web page's DOM structure to gather data. JavaScript libraries like jQuery facilitate this process by allowing manipulation and querying of the DOM to retrieve specific information.
- Proxy Use: Many websites implement measures to limit access based on IP addresses. By utilizing proxies, one can bypass these restrictions and access the necessary URLs without being blocked. This method is often more reliable and efficient.
- Headless Browsers: Tools like Puppeteer and Selenium simulate interactions with web pages by rendering them in a headless browser. This approach allows navigation through complex web pages, handling JavaScript execution, and gathering data as if browsing manually.
- Regular Expressions: Regular expressions (regex) can be used to identify patterns in the web page content and gather information accordingly. This technique is useful for specific tasks where the content follows a predictable pattern.
Legal disclaimer and precautions
This tutorial covers popular web scraping techniques for educational purposes. Interacting with public servers requires diligence and respect, and here's a good summary of what not to do:
- Do not scrape at rates that could damage the website.
- Do not scrape reviews or text that's not publicly available.
- Do not store personally identifiable information (PII) of EU citizens who are protected by GDPR.
- Do not repurpose entire public datasets, as this can be illegal in some countries.
When you search or read content, make sure to follow ethical guidelines and legal considerations. For more detailed guidance, you should consult a lawyer.
Why scrape Amazon products?
Scraping Amazon offers several significant benefits for businesses, researchers, and individuals:
- Competitive Analysis: By using a scraper to gather information from Amazon, businesses can read competitor descriptions, customer reviews, and track item availability. This will help in developing competitive strategies and adjusting their own offerings to stay ahead in the market.
- Market Research: Scraping Amazon allows companies to search for consumer trends, preferences, and buying behaviors. This information helps in identifying popular items, understanding customer needs, and making informed decisions about development and marketing strategies.
- Price Monitoring: Retailers and consumers can use scraping to track changes over time. This is particularly useful for dynamic strategies, where businesses will adjust values based on competitor activity and market demand.
- Data Aggregation: Businesses that sell on multiple platforms can use a scraper to aggregate their content, ensuring consistency across all channels. This helps in maintaining accurate listings, managing inventory, and streamlining operations.
- Customer Sentiment Analysis: By analyzing customer reviews and ratings, businesses can gain insights into satisfaction and product performance. This information can be used to improve offerings, address common issues, and enhance customer service.
- Lead Generation: Scraping Amazon can help in identifying potential leads and opportunities for partnerships or sales. For example, businesses can search for resellers, suppliers, or influencers who are active in their industry.
Overall, the ability to read and scrape data from Amazon is a valuable resource that will aid in strategic decision-making and improve operational efficiency
Building a basic Amazon scraper
Using requests to fetch Amazon URLs
Setting up user-agent
When scraping websites, it is important to set up a User-Agent to mimic a real browser request. This helps in avoiding blocks and getting the correct response from the server. In Python, you can use the requests library to set up a User-Agent. Here’s an example:
import requests
import random
# List of user-agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 10; SM-G960F)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Mobile Safari/537.36'
]
# Choose a random user-agent
headers = {
'User-Agent': random.choice(user_agents)
}
url = 'https://www.amazon.com/dp/B0B72B7GM2' # Example product URL
# Make a GET request to the specified URL with the chosen headers
response = requests.get(url, headers=headers)
# Print the status code of the response
print(response.status_code)
In this example, the User-Agent string is set to mimic a common web browser, making it less likely that the request will be blocked by Amazon’s servers.
Retrieving HTML content
Once the request is made, the next step is to retrieve the content of the webpage. This can be done using the response object obtained from the requests.get call. Here’s how you can retrieve and print the content:
if response.status_code == 200:
html_content = response.text
print(html_content)
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
This code checks if the request was successful (status code 200) and then retrieves the HTML content as a text string.
Parsing HTML with BeautifulSoup
What is BeautifulSoup?
BeautifulSoup is a popular Python library designed for web scraping and parsing XML documents. It allows a scraper to easily navigate and manipulate the structure of a webpage, simplifying the extraction of content. BeautifulSoup will take the page source and build a parse tree, which can then be searched and modified to extract relevant text or information. It's especially useful for scraping poorly formatted or inconsistent markup. By using BeautifulSoup in Python, developers can efficiently scrape content from websites, automating the process of gathering and organizing information from the web, making it a powerful tool for any scraper.
Why use BeautifulSoup?
BeautifulSoup is made up of different parsing tools such as soup, lxml, and HTML5lib. This flexibility allows you to try various parsing methods and benefit from their advantages depending on the situation. One of the main reasons to use BeautifulSoup is its ease of use. It will only take a few lines in Python to create a scraper that can efficiently scrape content from web pages. Despite its simplicity, it is robust and reliable, making it a popular choice not only for developers but also for those working with web scraping in general.
With its clear and comprehensive documentation, BeautifulSoup will help scrapers learn quickly and solve problems effectively. Additionally, an active online community offers various solutions to challenges you may face while scraping, making it a great tool for beginners and experts alike.
Finding product title and price
To parse the HTML content and extract specific information such as the product title and value, you can use the Beautiful Soup library.
BeautifulSoup is a powerful and easy-to-use Python library for extracting data from HTML and XML files, enabling users to navigate, search, and modify web page content efficiently, all while enjoying the simplicity of this 'soup' of parsing tools.
Here’s an example of how to extract these details:
Let's examine the structure of the product details page.
Open a product URL, such as https://www.amazon.com/dp/B0B72B7GM2, in Chrome or any other modern browser, right-click the product title, and select Inspect.
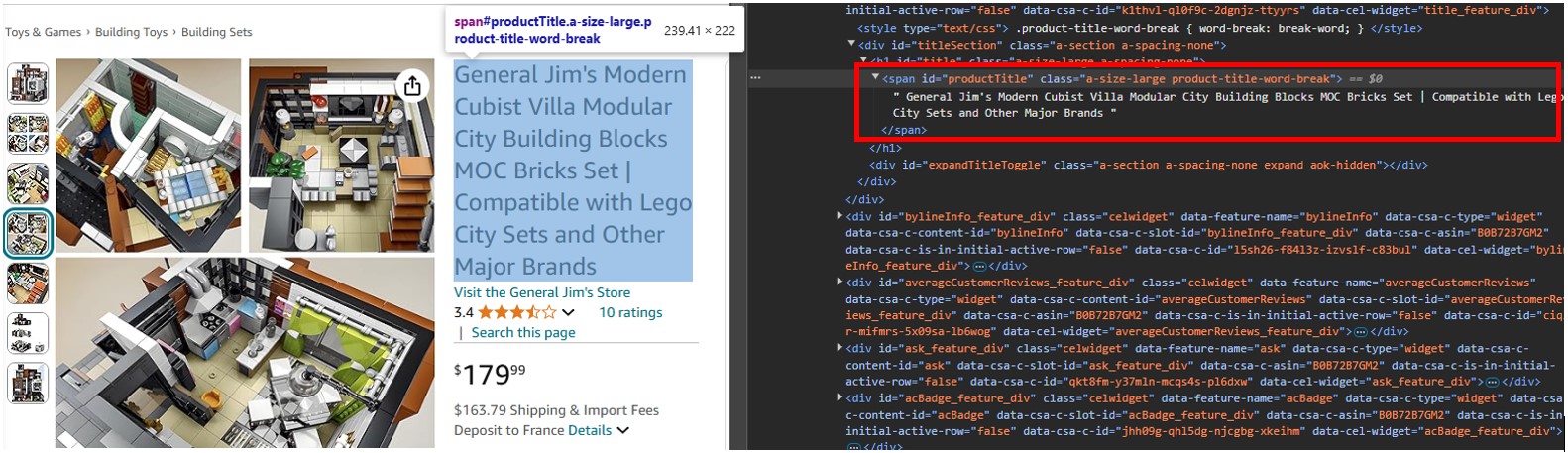
You will see that it is a span tag with its id attribute set to "productTitle".
Similarly, if you right-click the element and select Inspect, you will see the markup of the content, which the scraper will read and allow you to search for specific details.
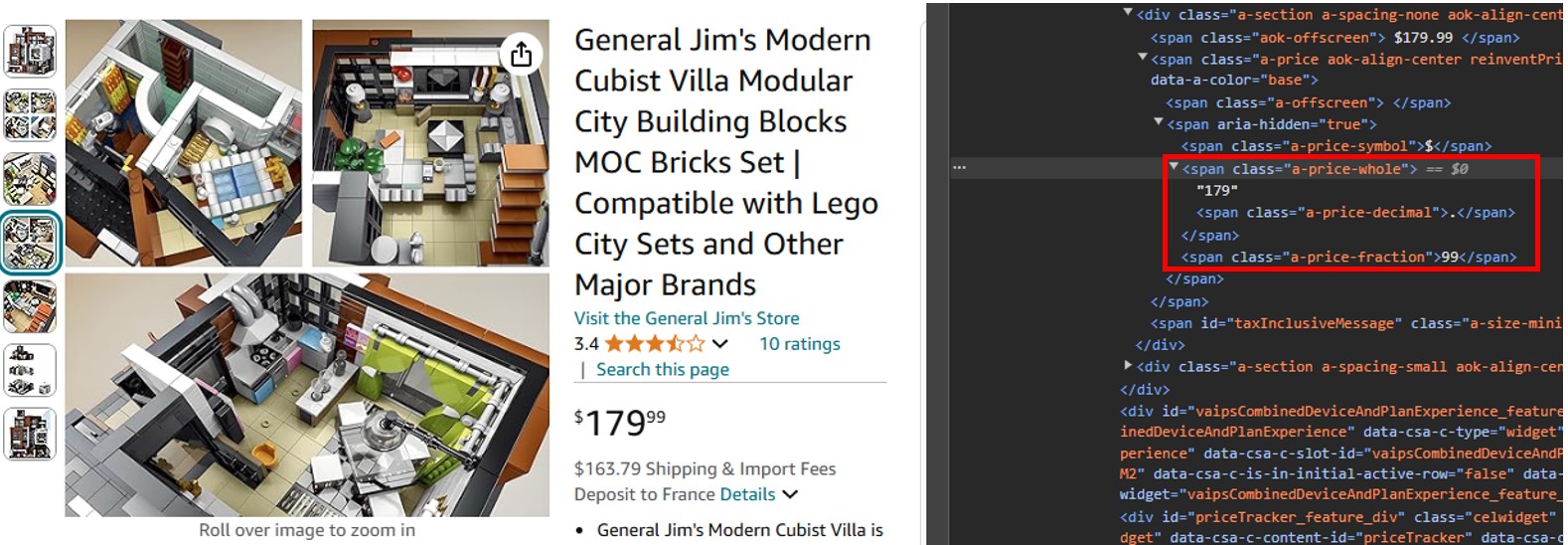
You can see that the dollar component of the price is in a span tag with the class "a-price-whole", and the cents component is in another span tag with the class set to "a-price-fraction".
Similarly, you can locate the rating, image, and description.
Once you have this information, we can set up our code with beautiful soup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Finding the title
title_tag = soup.find('span', {'id': 'productTitle'})
product_title = title_tag.get_text(strip=True) if title_tag else 'Title not found'
price_tag = soup.find('span', {'class': 'a-offscreen'})
product_price = price_tag.get_text(strip=True) if price_tag else 'Price not found'
print(f"Title: {product_title}")
print(f"Price: {product_price}")
In this example, BeautifulSoup is used to parse the HTML content and find the tags containing the product title and price. The get_text(strip=true) method is used to extract the text content and remove any leading or trailing whitespace.
Extracting customer reviews and ratings
To extract customer reviews and ratings, you need to find the relevant HTML tags and classes. Here’s an example:
# Finding customer reviews
reviews = []
review_tags = soup.find_all('span', {'data-hook': 'review-body'})
for tag in review_tags:
review_text = tag.get_text(strip=True)
reviews.append(review_text)
# Finding customer ratings
ratings = []
rating_tags = soup.find_all('i', {'data-hook': 'review-star-rating'})
for tag in rating_tags:
rating_text = tag.get_text(strip=True)
ratings.append(rating_text)
print(f"Customer Reviews: {reviews}")
print(f"Customer Ratings: {ratings}")
In this code, find_all is used to locate all instances of review bodies and ratings. The text content of each review and rating is extracted and stored in lists.
By combining these steps, you can build a basic Amazon scraper that fetches product details, customer reviews, and ratings. Remember to handle errors and respect Amazon’s terms of service to avoid potential legal issues.
Final script revision
To scrape Amazon product pages, we will use Python's requests library to fetch URLs and BeautifulSoup to parse HTML content. Here's the final consolidated script that demonstrates these processes:
import requests
import random
from bs4 import BeautifulSoup
# List of user-agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 10; SM-G960F)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Mobile Safari/537.36'
]
# Choose a random user-agent
headers = {
'User-Agent': random.choice(user_agents)
}
# Example product URL
url = 'https://www.amazon.com/dp/B0B72B7GM2'
# Make a GET request to the specified URL with the chosen headers
response = requests.get(url, headers=headers)
# Check if the request was successful
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
# Finding the title
title_tag = soup.find('span', {'id': 'productTitle'})
product_title = title_tag.get_text(strip=True) if title_tag else 'Title not found'
# Finding the price
price_tag = soup.find('span', {'class': 'a-offscreen'})
product_price = price_tag.get_text(strip=True) if price_tag else 'Price not found'
# Finding customer reviews
reviews = []
review_tags = soup.find_all('span', {'data-hook': 'review-body'})
for tag in review_tags:
review_text = tag.get_text(strip=True)
reviews.append(review_text)
# Finding customer ratings
ratings = []
rating_tags = soup.find_all('i', {'data-hook': 'review-star-rating'})
for tag in rating_tags:
rating_text = tag.get_text(strip=True)
ratings.append(rating_text)
print(f"Title: {product_title}")
print(f"Price: {product_price}")
print(f"Customer Reviews: {reviews}")
print(f"Customer Ratings: {ratings}")
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")

Advanced techniques in Amazon scraping
In this chapter, we'll explore advanced techniques to scrape Amazon. These powerful tools, utilizing Python, specialize in data retrieval from URLs, saving time and money while making web scraping accessible to everyone.
Why use a web scraping software?
The ability to scrape, collect, and analyze content from the internet using a scraper has become a crucial skill for businesses and researchers alike. This is where web scraping software, particularly with Python, will make a significant difference in your ability to search and retrieve relevant information.
Reduced risk of detection and blocking
One of the challenges when building a custom scraper is the risk of being detected and blocked by websites. Websites often have security measures in place, such as rate limiting or IP blocking, to prevent scraping. However, using expert web scraping software with Python significantly reduces the risk of detection. These tools are designed to handle sophisticated anti-scraping mechanisms, such as rotating IP addresses, mimicking human-like behavior, and managing request intervals to avoid triggering security systems.
Access to large volumes of data
The internet is a treasure trove of information, but manually scraping websites can be time-consuming and impractical. A scraper using Python automates this process, allowing users to scrape large volumes of content quickly and efficiently. Whether it's for market research, competitive analysis, or academic studies, web scraping will gather information that would otherwise take days or weeks to compile manually.
Scalability
As businesses grow, so does their need to scrape more information. A scraper using Python is highly scalable, capable of handling increasing amounts of content without a loss in performance. This scalability will make web scraping an ideal solution for businesses of all sizes, from startups to large enterprises.
Why use Piloterr API for Amazon scraping?
The Piloterr scraper stands out as a powerful tool for scraping Amazon product data. Here are several reasons why you should consider using the Piloterr solution for your Amazon scraping needs:
- Private Proxy: Piloterr uses its own private proxies, ensuring that your requests are distributed across multiple IP addresses (IP rotation). This will significantly reduce the likelihood of being blocked by Amazon and allows you to scrape data efficiently and effectively. Our robust infrastructure is built with Python and designed to handle high volumes of requests while maintaining a high success rate.
- Comprehensive Library Access with a Single Subscription: One of the most compelling reasons to choose Piloterr is the value offered by our subscription model. With a single subscription, you'll get access to our API endpoints library and scraping resources. This includes not only the Amazon scraper but also other scraping solutions for various websites and data sources. This all-inclusive access ensures you have the tools you need for any scraping project, all in one place.
With Piloterr, you can easily search, read, and retrieve the necessary information from Amazon and other platforms, giving you a powerful edge in your data collection efforts.
Create your account
- Register on piloterr.com
- Create your subscription (50 free credits on the registration)
- Create and copy your API key
Case study: scrape Amazon
Here is a practical example of how to use Python to scrape the title and other relevant details of an Amazon item from its URL. A scraper will be used to retrieve the necessary information efficiently.
Python basic code
Don't forget to replace PILOTERR_API_KEY with your real API key. The script assumes that the Piloterr API responses are in a format specific to our API, so it may need to be adjusted depending on the provider you choose.
- Copy the code
- Create a new file
get_amazon_product.py - Replace the API token with your own
- Replace variable
JOB_TITLE&LOCATIONby your need - Run the script with
python get_amazon_product.py
import requests
PILOTERR_API_KEY = 'YOUR-API-KEY-HERE'
LIST_ASIN_AMAZON_PRODUCT = [
"B0CN78FNTY",
"B09JGLMDLZ",
"B09VZ3ZQWQ",
"B0B72B7GM2"
]
def get_amazon_product_info(url: str):
amazon_api_url = "https://piloterr.com/api/v2/amazon/product"
headers = {
"x-api-key": PILOTERR_API_KEY
}
data = {
"query": url,
"domain": "com"
}
response = requests.get(
url=amazon_api_url,
headers=headers,
params=data # Using params instead of json for GET request
)
if response.status_code == 200:
return response.json()
else:
print(f"Error: Unable to perform search. Status code: {response.status_code}")
return None
def extract_product_data(json_data):
product_data = {
"url": json_data.get("url"),
"asin": json_data.get("asin"),
"price": json_data.get("price"),
"stock": json_data.get("stock"),
"title": json_data.get("title")
}
return product_data
def process_amazon_products(url_list):
all_product_data = []
for url in url_list:
product_info = get_amazon_product_info(url)
if product_info:
extracted_data = extract_product_data(product_info)
all_product_data.append(extracted_data)
return all_product_data
# Usage
if __name__ == "__main__":
products_data = process_amazon_products(LIST_ASIN_AMAZON_PRODUCT)
print(products_data)
Python explanation
- Imports: The code imports the
requestslibrary to make HTTP requests. - API Key and Product List: It defines a constant
PILOTERR_API_KEYfor the API authentication and a listLIST_ASIN_AMAZON_PRODUCTcontaining ASINs (Amazon Standard Identification Numbers) of products to query. - Function
get_amazon_product_info(url: str):- Constructs a request to the Piloterr API to retrieve product information.
- It sets the request headers with the API key and parameters for the product search.
- If the response status is 200 (OK), it returns the JSON data; otherwise, it prints an error message.
- Function
extract_product_data(json_data):- Extracts specific fields (
url,asin,price,stock, andtitle) from the JSON data returned by the API and returns them in a dictionary.
- Extracts specific fields (
- Function
process_amazon_products(url_list):- Iterates over a list of product URLs (ASINs), retrieves product information using
get_amazon_product_info, and extracts relevant data usingextract_product_data. - It compiles all extracted product data into a list and returns it.
- Iterates over a list of product URLs (ASINs), retrieves product information using
Other use cases
- Retrieve Best-Selling Articles: Use the API to gather data on the best-selling products in a specific category or overall. This could help identify trending items based on sales performance.
- Analyze Star: Scrape product information, including star ratings. This allows users to filter products based on customer satisfaction and find highly-rated items.
- Extract Product Images: Retrieve high-quality images of articles for use in e-commerce websites or comparison platforms. This enhances the visual appeal of listings and helps customers make informed decisions.
- Build a Review Aggregator: Compile customer reviews and ratings for the best articles in a specific niche. This can aid consumers in making decisions based on comprehensive feedback from other buyers.
Precautions for scraping on Amazon
When scraping Amazon, it’s crucial to remember that CSS selectors (elem.css()) may change over time as Amazon's developers frequently update the website's CSS. These updates can alter the structure, causing your existing CSS selectors to fail. To reduce maintenance, carefully choose selectors for your element (elem), prioritizing <div> elements with stable attributes, such as id. By targeting elements with specific id attributes, you improve the resilience of your scraping script against CSS changes.
Conclusion
Piloterr is one of the best ways to scrape Amazon items simply and efficiently using our Python scraper. By integrating this solution into your workflow, you will streamline your process, eliminating the need to manage agents or IP addresses, as everything goes through our proxies. Whether you're scraping data from URLs for market analysis, competitor research, or other purposes, Piloterr will enable you to easily search, read, and retrieve the information you need. It is a valuable tool to add to your web scraping toolbox.