Découvrez comment scraper Amazon en utilisant des en-têtes User-Agent pour éviter la détection et BeautifulSoup pour analyser le contenu HTML. Ce guide complet inclut également un exemple d'utilisation détaillé qui démontre l'extraction d'informations produit, telles que les titres, les prix et les notes, avec Python.
Évitez la maintenance: utilisez l'API de scraping Amazon ou l'API Produit Amazon pour obtenir des données JSON structurées.
Introduction au web scraping
Qu'est-ce que le web scraping ?
Le web scraping est une méthode utilisée pour extraire automatiquement de grandes quantités de contenu depuis des sites web. L'objectif principal du web scraping est de collecter et structurer des informations disponibles sur le web, qui peuvent ensuite être utilisées pour diverses applications. Ce contenu peut inclure du texte, des images, des vidéos et d'autres formes de médias disponibles sur les pages web. En automatisant le processus d'extraction, le web scraping permet de lire, rechercher et analyser rapidement le contenu web, ce qui représente un gain de temps et d'effort considérable par rapport à la collecte manuelle de données.
Outils et techniques
Plusieurs outils et techniques sont employés en web scraping pour garantir une collecte de données efficace :
- Parsing HTML : Cette technique consiste à analyser la structure d'une page web pour en extraire les informations. Des outils tels qu'un scraper Python et Cheerio (JavaScript) sont couramment utilisés à cet effet. Ils permettent de naviguer dans la structure de la page et de récupérer les détails pertinents en fonction des balises, attributs et autres éléments.
- Parsing DOM : Le parsing du Document Object Model (DOM) consiste à interagir avec la structure DOM de la page web pour collecter des données. Des bibliothèques JavaScript comme jQuery facilitent ce processus en permettant de manipuler et d'interroger le DOM pour récupérer des informations spécifiques.
- Utilisation de proxies : De nombreux sites web mettent en place des mesures pour limiter l'accès en fonction des adresses IP. En utilisant des proxies, vous pouvez contourner ces restrictions et accéder aux URL nécessaires sans être bloqué. Cette méthode est souvent plus fiable et plus efficace.
- Navigateurs headless : Des outils comme Puppeteer et Selenium simulent les interactions avec les pages web en les rendant dans un navigateur headless. Cette approche permet de naviguer sur des pages web complexes, de gérer l'exécution JavaScript et de collecter des données comme lors d'une navigation manuelle.
- Expressions régulières : Les expressions régulières (regex) peuvent être utilisées pour identifier des motifs dans le contenu de la page web et en extraire les informations correspondantes. Cette technique est utile pour des tâches spécifiques où le contenu suit un motif prévisible.
Avertissement juridique et précautions
Ce tutoriel couvre des techniques populaires de web scraping à des fins éducatives. Interagir avec des serveurs publics exige diligence et respect. Voici un résumé de ce qu'il ne faut pas faire :
- Ne scrapez pas à des fréquences susceptibles d'endommager le site web.
- Ne scrapez pas d'avis ou de textes qui ne sont pas accessibles publiquement.
- Ne stockez pas d'informations personnelles identifiables (PII) de citoyens de l'UE protégés par le RGPD.
- Ne réutilisez pas intégralement des jeux de données publics, car cela peut être illégal dans certains pays.
Lorsque vous effectuez des recherches ou consultez du contenu, assurez-vous de respecter les principes éthiques et les considérations juridiques. Pour des conseils plus détaillés, consultez un avocat.
Pourquoi scraper les produits Amazon ?
Le scraping d'Amazon offre plusieurs avantages significatifs pour les entreprises, les chercheurs et les particuliers :
- Analyse concurrentielle : En utilisant un scraper pour collecter des informations sur Amazon, les entreprises peuvent consulter les descriptions des concurrents, les avis clients et suivre la disponibilité des articles. Cela contribue à élaborer des stratégies concurrentielles et à ajuster leurs propres offres pour rester en avance sur le marché.
- Études de marché : Le scraping d'Amazon permet aux entreprises d'identifier les tendances de consommation, les préférences et les comportements d'achat. Ces informations aident à repérer les articles populaires, à comprendre les besoins des clients et à prendre des décisions éclairées en matière de développement et de stratégie marketing.
- Suivi des prix : Les retailers et les consommateurs peuvent utiliser le scraping pour suivre l'évolution des prix dans le temps. Cela est particulièrement utile pour les stratégies dynamiques, où les entreprises ajustent leurs tarifs en fonction de l'activité concurrentielle et de la demande du marché.
- Agrégation de données : Les entreprises qui vendent sur plusieurs plateformes peuvent utiliser un scraper pour agréger leur contenu et garantir la cohérence sur l'ensemble de leurs canaux. Cela contribue à maintenir des fiches produit exactes, à gérer les stocks et à rationaliser les opérations.
- Analyse du sentiment client : En analysant les avis et les notes clients, les entreprises obtiennent des informations sur la satisfaction et la performance produit. Ces informations peuvent être utilisées pour améliorer les offres, traiter les problèmes récurrents et renforcer le service client.
- Génération de leads : Le scraping d'Amazon peut aider à identifier des prospects et des opportunités de partenariat ou de vente. Par exemple, les entreprises peuvent rechercher des revendeurs, des fournisseurs ou des influenceurs actifs dans leur secteur.
Dans l'ensemble, la capacité à lire et scraper des données depuis Amazon constitue une ressource précieuse qui contribue à la prise de décision stratégique et à l'amélioration de l'efficacité opérationnelle.
Construire un scraper Amazon basique
Utiliser requests pour récupérer les URL Amazon
Configurer le User-Agent
Lors du scraping de sites web, il est important de configurer un User-Agent pour imiter une requête de navigateur réel. Cela permet d'éviter les blocages et d'obtenir la réponse correcte du serveur. En Python, vous pouvez utiliser la bibliothèque requests pour configurer un User-Agent. Voici un exemple :
import requests
import random
# List of user-agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 10; SM-G960F)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Mobile Safari/537.36'
]
# Choose a random user-agent
headers = {
'User-Agent': random.choice(user_agents)
}
url = 'https://www.amazon.com/dp/B0B72B7GM2' # Example product URL
# Make a GET request to the specified URL with the chosen headers
response = requests.get(url, headers=headers)
# Print the status code of the response
print(response.status_code)
Dans cet exemple, la chaîne User-Agent est configurée pour imiter un navigateur web courant, ce qui réduit la probabilité que la requête soit bloquée par les serveurs d'Amazon.
Récupérer le contenu HTML
Une fois la requête effectuée, l'étape suivante consiste à récupérer le contenu de la page web. Cela peut se faire à l'aide de l'objet response obtenu via l'appel requests.get. Voici comment récupérer et afficher le contenu :
if response.status_code == 200:
html_content = response.text
print(html_content)
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
Ce code vérifie si la requête a réussi (code de statut 200), puis récupère le contenu HTML sous forme de chaîne de caractères.
Parser le HTML avec BeautifulSoup
Qu'est-ce que BeautifulSoup ?
BeautifulSoup est une bibliothèque Python populaire conçue pour le web scraping et le parsing de documents XML. Elle permet à un scraper de naviguer et de manipuler facilement la structure d'une page web, simplifiant ainsi l'extraction de contenu. BeautifulSoup prend le code source de la page et construit un arbre de parsing, qui peut ensuite être parcouru et modifié pour extraire le texte ou les informations pertinentes. Elle est particulièrement utile pour scraper du balisage mal formaté ou incohérent. En utilisant BeautifulSoup en Python, les développeurs peuvent scraper efficacement le contenu de sites web, en automatisant le processus de collecte et d'organisation d'informations depuis le web, ce qui en fait un outil puissant pour tout scraper.
Pourquoi utiliser BeautifulSoup ?
BeautifulSoup regroupe différents outils de parsing tels que soup, lxml et HTML5lib. Cette flexibilité vous permet d'essayer diverses méthodes de parsing et de bénéficier de leurs avantages selon la situation. L'une des principales raisons d'utiliser BeautifulSoup est sa simplicité d'utilisation. Il ne faut que quelques lignes en Python pour créer un scraper capable d'extraire efficacement le contenu des pages web. Malgré sa simplicité, elle est robuste et fiable, ce qui en fait un choix populaire non seulement pour les développeurs, mais aussi pour tous ceux qui travaillent sur le web scraping.
Grâce à sa documentation claire et complète, BeautifulSoup aide les scrapers à apprendre rapidement et à résoudre efficacement les problèmes. De plus, une communauté en ligne active propose diverses solutions aux défis que vous pourriez rencontrer lors du scraping, ce qui en fait un excellent outil pour les débutants comme pour les experts.
Trouver le titre et le prix du produit
Pour parser le contenu HTML et extraire des informations spécifiques telles que le titre et le prix du produit, vous pouvez utiliser la bibliothèque Beautiful Soup.
BeautifulSoup est une bibliothèque Python puissante et facile à utiliser pour extraire des données de fichiers HTML et XML, permettant de naviguer, rechercher et modifier le contenu des pages web efficacement, tout en profitant de la simplicité de cette « soupe » d'outils de parsing.
Voici un exemple d'extraction de ces détails :
Examinons la structure de la page de détails produit.
Ouvrez une URL produit, telle que https://www.amazon.com/dp/B0B72B7GM2, dans Chrome ou tout autre navigateur moderne, cliquez avec le bouton droit sur le titre du produit et sélectionnez Inspecter.
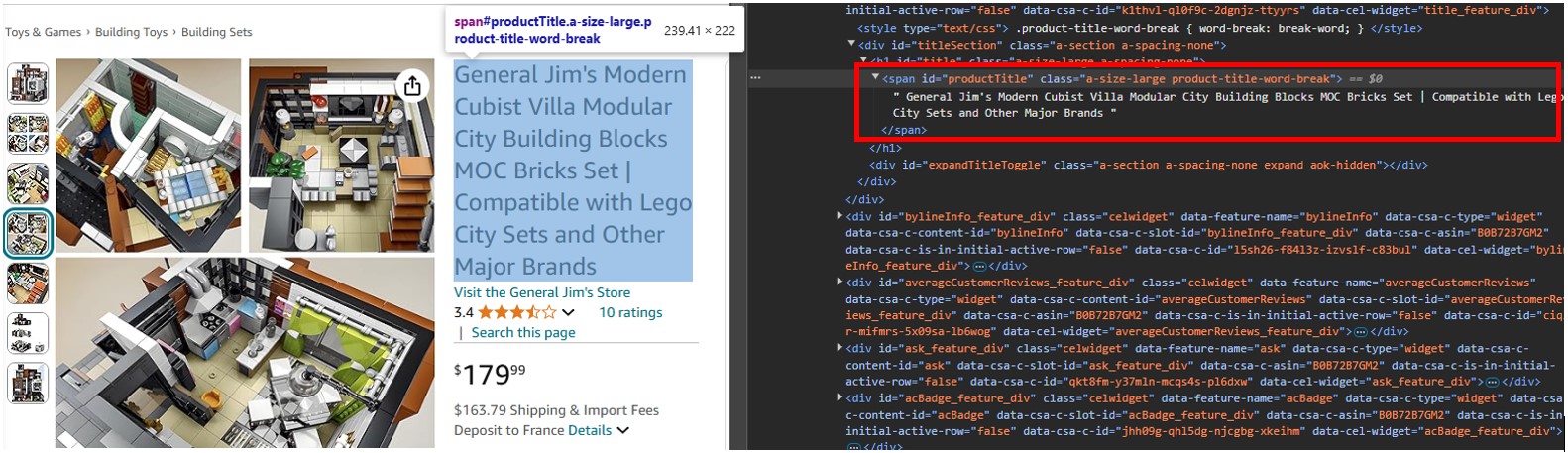
Vous verrez qu'il s'agit d'une balise span dont l'attribut id est défini sur « productTitle ».
De même, si vous cliquez avec le bouton droit sur l'élément et sélectionnez Inspecter, vous verrez le balisage du contenu, que le scraper lira et vous permettra d'interroger pour extraire des détails spécifiques.
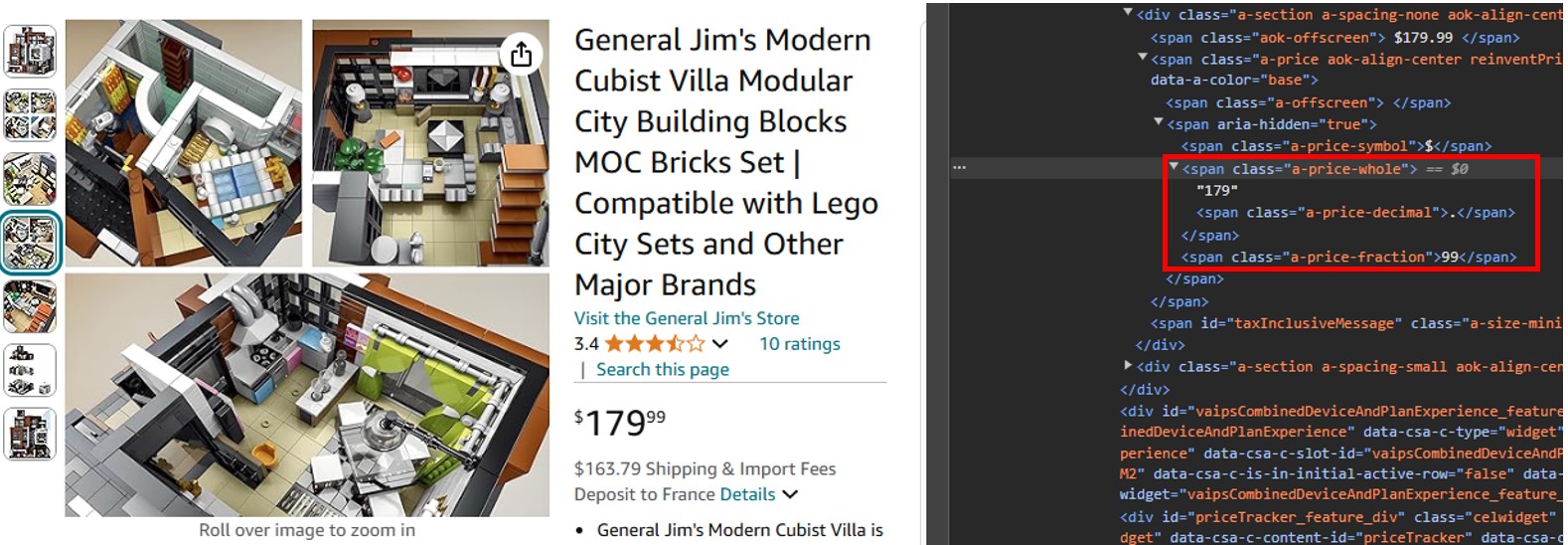
Vous pouvez constater que la composante en dollars du prix se trouve dans une balise span avec la classe « a-price-whole », et la composante en centimes dans une autre balise span dont la classe est « a-price-fraction ».
De même, vous pouvez localiser la note, l'image et la description.
Une fois ces informations identifiées, nous pouvons configurer notre code avec Beautiful Soup :
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Finding the title
title_tag = soup.find('span', {'id': 'productTitle'})
product_title = title_tag.get_text(strip=True) if title_tag else 'Title not found'
price_tag = soup.find('span', {'class': 'a-offscreen'})
product_price = price_tag.get_text(strip=True) if price_tag else 'Price not found'
print(f"Title: {product_title}")
print(f"Price: {product_price}")
Dans cet exemple, BeautifulSoup est utilisé pour parser le contenu HTML et trouver les balises contenant le titre et le prix du produit. La méthode get_text(strip=true) est utilisée pour extraire le contenu textuel et supprimer les espaces en début et en fin de chaîne.
Extraire les avis et notes clients
Pour extraire les avis et notes clients, vous devez identifier les balises et classes HTML pertinentes. Voici un exemple :
# Finding customer reviews
reviews = []
review_tags = soup.find_all('span', {'data-hook': 'review-body'})
for tag in review_tags:
review_text = tag.get_text(strip=True)
reviews.append(review_text)
# Finding customer ratings
ratings = []
rating_tags = soup.find_all('i', {'data-hook': 'review-star-rating'})
for tag in rating_tags:
rating_text = tag.get_text(strip=True)
ratings.append(rating_text)
print(f"Customer Reviews: {reviews}")
print(f"Customer Ratings: {ratings}")
Dans ce code, find_all est utilisé pour localiser toutes les instances de corps d'avis et de notes. Le contenu textuel de chaque avis et de chaque note est extrait et stocké dans des listes.
En combinant ces étapes, vous pouvez construire un scraper Amazon basique qui récupère les détails produit, les avis clients et les notes. N'oubliez pas de gérer les erreurs et de respecter les conditions d'utilisation d'Amazon pour éviter d'éventuels problèmes juridiques.
Révision du script final
Pour scraper les pages produit Amazon, nous utiliserons la bibliothèque requests de Python pour récupérer les URL et BeautifulSoup pour parser le contenu HTML. Voici le script final consolidé qui démontre ces processus :
import requests
import random
from bs4 import BeautifulSoup
# List of user-agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 10; SM-G960F)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Mobile Safari/537.36'
]
# Choose a random user-agent
headers = {
'User-Agent': random.choice(user_agents)
}
# Example product URL
url = 'https://www.amazon.com/dp/B0B72B7GM2'
# Make a GET request to the specified URL with the chosen headers
response = requests.get(url, headers=headers)
# Check if the request was successful
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
# Finding the title
title_tag = soup.find('span', {'id': 'productTitle'})
product_title = title_tag.get_text(strip=True) if title_tag else 'Title not found'
# Finding the price
price_tag = soup.find('span', {'class': 'a-offscreen'})
product_price = price_tag.get_text(strip=True) if price_tag else 'Price not found'
# Finding customer reviews
reviews = []
review_tags = soup.find_all('span', {'data-hook': 'review-body'})
for tag in review_tags:
review_text = tag.get_text(strip=True)
reviews.append(review_text)
# Finding customer ratings
ratings = []
rating_tags = soup.find_all('i', {'data-hook': 'review-star-rating'})
for tag in rating_tags:
rating_text = tag.get_text(strip=True)
ratings.append(rating_text)
print(f"Title: {product_title}")
print(f"Price: {product_price}")
print(f"Customer Reviews: {reviews}")
print(f"Customer Ratings: {ratings}")
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")

Techniques avancées pour le scraping Amazon
Dans ce chapitre, nous explorerons des techniques avancées pour scraper Amazon. Ces outils puissants, utilisant Python, se spécialisent dans la récupération de données depuis des URL, ce qui permet de gagner du temps et de l'argent tout en rendant le web scraping accessible à tous.
Pourquoi utiliser un logiciel de web scraping ?
La capacité à scraper, collecter et analyser du contenu depuis Internet à l'aide d'un scraper est devenue une compétence essentielle pour les entreprises comme pour les chercheurs. C'est là qu'un logiciel de web scraping, notamment avec Python, fera une différence significative dans votre capacité à rechercher et récupérer des informations pertinentes.
Risque réduit de détection et de blocage
L'un des défis lors de la construction d'un scraper personnalisé est le risque d'être détecté et bloqué par les sites web. Les sites mettent souvent en place des mesures de sécurité, telles que la limitation du débit ou le blocage d'IP, pour empêcher le scraping. Cependant, l'utilisation d'un logiciel de web scraping expert avec Python réduit considérablement ce risque. Ces outils sont conçus pour gérer des mécanismes anti-scraping sophistiqués, tels que la rotation de proxies, l'imitation d'un comportement humain et la gestion des intervalles entre requêtes pour éviter de déclencher les systèmes de sécurité.
Accès à de grands volumes de données
Internet regorge d'informations, mais scraper manuellement des sites web est chronophage et peu pratique. Un scraper utilisant Python automatise ce processus, permettant de scraper de grands volumes de contenu rapidement et efficacement. Qu'il s'agisse d'études de marché, d'analyse concurrentielle ou de recherches académiques, le web scraping permet de collecter des informations qui prendraient autrement des jours ou des semaines à compiler manuellement.
Scalabilité
À mesure que les entreprises se développent, leur besoin de scraper davantage d'informations augmente également. Un scraper utilisant Python est hautement évolutif, capable de traiter des volumes croissants de contenu sans perte de performance. Cette scalabilité fait du web scraping une solution idéale pour les entreprises de toutes tailles, des startups aux grandes organisations.
Pourquoi utiliser l'API Piloterr pour le scraping Amazon ?
Le scraper Piloterr se distingue comme un outil puissant pour scraper les données produit Amazon. Voici plusieurs raisons d'envisager la solution Piloterr pour vos besoins de scraping Amazon :
- Proxy privé : Piloterr utilise ses propres proxies privés, garantissant que vos requêtes sont distribuées sur plusieurs adresses IP (rotation de proxies). Cela réduit considérablement la probabilité d'être bloqué par Amazon et vous permet de scraper des données efficacement. Notre infrastructure robuste est construite avec Python et conçue pour gérer de grands volumes de requêtes tout en maintenant un taux de succès élevé.
- Accès complet à la bibliothèque avec un seul abonnement : L'une des raisons les plus convaincantes de choisir Piloterr est la valeur offerte par notre modèle d'abonnement. Avec un seul abonnement, vous accédez à notre bibliothèque de endpoints API et de ressources de scraping. Cela inclut non seulement le scraper Amazon, mais aussi d'autres solutions de scraping pour divers sites web et sources de données. Cet accès tout-en-un garantit que vous disposez des outils nécessaires pour tout projet de scraping, au même endroit.
Avec Piloterr, vous pouvez facilement rechercher, consulter et récupérer les informations nécessaires depuis Amazon et d'autres plateformes, ce qui vous confère un avantage significatif dans vos efforts de collecte de données.
Créer votre compte
- Inscrivez-vous sur piloterr.com
- Créez votre abonnement (50 crédits gratuits à l'inscription)
- Créez et copiez votre clé API
Étude de cas : scraper Amazon
Voici un exemple pratique d'utilisation de Python pour scraper le titre et d'autres détails pertinents d'un article Amazon à partir de son URL. Un scraper sera utilisé pour récupérer efficacement les informations nécessaires.
Code Python de base
N'oubliez pas de remplacer PILOTERR_API_KEY par votre véritable clé API. Le script suppose que les réponses de l'API Piloterr sont au format spécifique à notre API ; des ajustements peuvent être nécessaires selon le fournisseur choisi.
- Copiez le code
- Créez un nouveau fichier
get_amazon_product.py - Remplacez le token API par le vôtre
- Remplacez les variables
JOB_TITLEetLOCATIONselon vos besoins - Exécutez le script avec
python get_amazon_product.py
import requests
PILOTERR_API_KEY = 'YOUR-API-KEY-HERE'
LIST_ASIN_AMAZON_PRODUCT = [
"B0CN78FNTY",
"B09JGLMDLZ",
"B09VZ3ZQWQ",
"B0B72B7GM2"
]
def get_amazon_product_info(url: str):
amazon_api_url = "https://piloterr.com/api/v2/amazon/product"
headers = {
"x-api-key": PILOTERR_API_KEY
}
data = {
"query": url,
"domain": "com"
}
response = requests.get(
url=amazon_api_url,
headers=headers,
params=data # Using params instead of json for GET request
)
if response.status_code == 200:
return response.json()
else:
print(f"Error: Unable to perform search. Status code: {response.status_code}")
return None
def extract_product_data(json_data):
product_data = {
"url": json_data.get("url"),
"asin": json_data.get("asin"),
"price": json_data.get("price"),
"stock": json_data.get("stock"),
"title": json_data.get("title")
}
return product_data
def process_amazon_products(url_list):
all_product_data = []
for url in url_list:
product_info = get_amazon_product_info(url)
if product_info:
extracted_data = extract_product_data(product_info)
all_product_data.append(extracted_data)
return all_product_data
# Usage
if __name__ == "__main__":
products_data = process_amazon_products(LIST_ASIN_AMAZON_PRODUCT)
print(products_data)
Explication du code Python
- Imports : Le code importe la bibliothèque
requestspour effectuer des requêtes HTTP. - Clé API et liste de produits : Il définit une constante
PILOTERR_API_KEYpour l'authentification API et une listeLIST_ASIN_AMAZON_PRODUCTcontenant les ASIN (Amazon Standard Identification Numbers) des produits à interroger. - Fonction
get_amazon_product_info(url: str):- Construit une requête vers l'API Piloterr pour récupérer les informations produit.
- Configure les en-têtes de requête avec la clé API et les paramètres de recherche produit.
- Si le statut de la réponse est 200 (OK), elle retourne les données JSON ; sinon, elle affiche un message d'erreur.
- Fonction
extract_product_data(json_data):- Extrait des champs spécifiques (
url,asin,price,stockettitle) des données JSON retournées par l'API et les retourne dans un dictionnaire.
- Extrait des champs spécifiques (
- Fonction
process_amazon_products(url_list):- Itère sur une liste d'URL produit (ASIN), récupère les informations produit via
get_amazon_product_infoet extrait les données pertinentes viaextract_product_data. - Compile l'ensemble des données produit extraites dans une liste et la retourne.
- Itère sur une liste d'URL produit (ASIN), récupère les informations produit via
Autres cas d'utilisation
- Récupérer les articles best-sellers : Utilisez l'API pour collecter des données sur les produits les plus vendus dans une catégorie spécifique ou globalement. Cela peut aider à identifier les articles tendance en fonction des performances de vente.
- Analyser les notes : Scrapez les informations produit, y compris les notes en étoiles. Cela permet de filtrer les produits en fonction de la satisfaction client et de trouver les articles les mieux notés.
- Extraire les images produit : Récupérez des images haute qualité d'articles pour les utiliser sur des sites e-commerce ou des plateformes de comparaison. Cela améliore l'attrait visuel des fiches produit et aide les clients à prendre des décisions éclairées.
- Construire un agrégateur d'avis : Compilez les avis et notes clients pour les meilleurs articles d'une niche spécifique. Cela peut aider les consommateurs à prendre des décisions basées sur des retours complets d'autres acheteurs.
Précautions pour le scraping sur Amazon
Lors du scraping d'Amazon, il est crucial de garder à l'esprit que les sélecteurs CSS (elem.css()) peuvent évoluer au fil du temps, car les développeurs d'Amazon mettent fréquemment à jour le CSS du site. Ces mises à jour peuvent modifier la structure et faire échouer vos sélecteurs CSS existants. Pour réduire la maintenance, choisissez soigneusement les sélecteurs de vos éléments (elem), en privilégiant les balises <div> avec des attributs stables, tels que id. En ciblant des éléments avec des attributs id spécifiques, vous améliorez la résilience de votre script de scraping face aux changements CSS.
Conclusion
Piloterr est l'une des meilleures façons de scraper simplement et efficacement les articles Amazon grâce à notre scraper Python. En intégrant cette solution dans votre workflow, vous rationaliserez votre processus en éliminant le besoin de gérer des agents ou des adresses IP, car tout transite par nos proxies. Que vous scrapiez des données depuis des URL pour une analyse de marché, une veille concurrentielle ou d'autres finalités, Piloterr vous permet de rechercher, consulter et récupérer facilement les informations dont vous avez besoin. C'est un outil précieux à ajouter à votre boîte à outils de web scraping.