Dans la concurrence intense d'aujourd'hui, chacun cherche à développer et utiliser de nouvelles technologies. Le web scraping désigne l'action de télécharger automatiquement des données depuis des sites web vers votre ordinateur ou votre base de données. Le web scraping est aussi appelé extraction de données ou extraction de données web. Le web scraping est une technique informatisée permettant de collecter d'importantes quantités de données sur des sites web. La plupart de ces informations sont non structurées au format HTML et sont transformées en données structurées dans une base de données ou un tableur afin d'être exploitées dans diverses applications. Le web scraping peut être réalisé selon plusieurs méthodes pour collecter des données sur des sites web. Il est possible d'utiliser des API dédiées, des services en ligne, ou même d'écrire votre propre code de scraping de zéro. Vous pouvez accéder aux données structurées de nombreux grands sites, notamment Google, Twitter, Facebook, StackOverflow et d'autres, via leurs API. Bien qu'il s'agisse de la meilleure option, certains sites ne disposent pas du même niveau de sophistication technique ou n'autorisent pas l'accès à de grandes quantités de données structurées. Dans ce cas, il vaut mieux recourir au web scraping pour collecter les données du site.
Deux outils sont nécessaires au web scraping : le scraper et le crawler. Le crawler est un système doté d'intelligence artificielle qui clique sur des liens pour parcourir le web à la recherche des informations requises. Un scraper, en revanche, est un outil spécialisé conçu pour extraire des données d'un site web. Selon l'échelle et la complexité du projet, l'architecture du scraper peut varier considérablement afin de récupérer les données de manière efficace et précise.
Usages du web scraping
Les usages les plus courants du web scraping sont les suivants :
- Génération de leads marketing : Des leads peuvent être générés à des fins marketing à l'aide d'un outil de web scraping. En extrayant les informations de sites pertinents, des listes d'e-mails et de numéros de téléphone pour la prospection directe peuvent être créées. Par exemple, des données provenant de sites proposant des annuaires ou de fiches entreprises Google Maps peuvent servir à extraire le numéro de téléphone et l'adresse e-mail d'une entreprise.
- Évaluation des prix et veille concurrentielle : Les entreprises proposant des biens ou services doivent disposer d'informations détaillées sur les produits et services concurrents constamment lancés sur le marché. Un outil de web scraping permet de surveiller régulièrement ces données.
- E-commerce : L'extraction fréquente de données produits depuis différents sites e-commerce comme Amazon, eBay, Google Shopping, etc. est possible grâce au web scraping. Un outil de web scraping permet de récupérer facilement les détails produits, notamment les prix, descriptions, images, avis et notes.
- Immobilier : Un outil de web scraping peut servir à récupérer les détails de biens publiés sur des sites immobiliers comme Zillow, Realtor et d'autres. Le web scraping permet de collecter les coordonnées des propriétaires et des agents en plus des données sur les biens.
- Analyse de données : Un particulier peut souhaiter collecter et analyser des informations sur une catégorie donnée à partir de différents sites web. Cette catégorie inclut l'immobilier, les véhicules, les gadgets, les contacts professionnels, ainsi que le marketing. Les différents sites d'une catégorie donnée présentent les informations de manières variées. Même sur un seul site, vous pourriez ne pas pouvoir consulter toutes les informations en une fois. Les données peuvent être réparties sur plusieurs pages (comme les listes paginées des résultats de recherche Google) et organisées en sections distinctes.
- Recherche académique : Toute recherche, qu'elle soit académique, marketing ou scientifique, nécessite des données. Un web scraper vous permet de collecter facilement des données structurées provenant de multiples sources sur internet.
- Données pour l'entraînement et les tests de projets de machine learning : Le web scraping vous permet de collecter des données pour tester et entraîner des modèles de machine learning. La performance de vos modèles de machine learning dépend de la qualité des données d'entraînement. Si ces données ne sont pas facilement disponibles, vous pouvez utiliser le web scraping pour les collecter auprès de plusieurs sources.
- Analyse des cotes de paris sportifs : Divers bookmakers utilisent le web scraping pour collecter les valeurs de cotes sur des sites de paris sportifs comme OddsPortal, BetExplorer, FlashScore, etc.
- Analyse de sentiment : L'analyse de sentiment est essentielle si les entreprises souhaitent comprendre comment les clients perçoivent globalement leurs produits. Le web scraping est une méthode que les entreprises utilisent pour acquérir des données sur les réseaux sociaux comme Facebook et Twitter concernant la perception générale de leurs produits. Elles pourront ainsi devancer leurs concurrents et créer des produits que les consommateurs souhaiteront.
Comment fonctionnent les web scrapers ?
Les web scrapers sont capables de collecter l'ensemble des informations de certains sites web ou les informations spécifiques demandées par un utilisateur. C'est la situation idéale pour garantir que seules les données dont vous avez besoin sont extraites rapidement par le web scraper. Par exemple, vous pourriez vouloir scraper un site Amazon pour connaître les types de centrifugeuses proposées, mais n'avoir besoin que des modèles des différentes centrifugeuses, et non des avis clients.
Les URL sont donc d'abord fournies lorsqu'un web scraper doit scraper un site web. Ensuite, l'ensemble du code HTML des sites est chargé. Un scraper plus avancé peut également extraire toutes les parties CSS et Javascript. Après extraction des données nécessaires du code HTML, le scraper les produit dans le format choisi par l'utilisateur. Le plus souvent, il s'agit d'un tableur Excel ou d'un fichier CSV, bien que les informations puissent aussi être enregistrées dans d'autres formats, comme un fichier JSON.
Quel est le processus du web scraping manuel ?
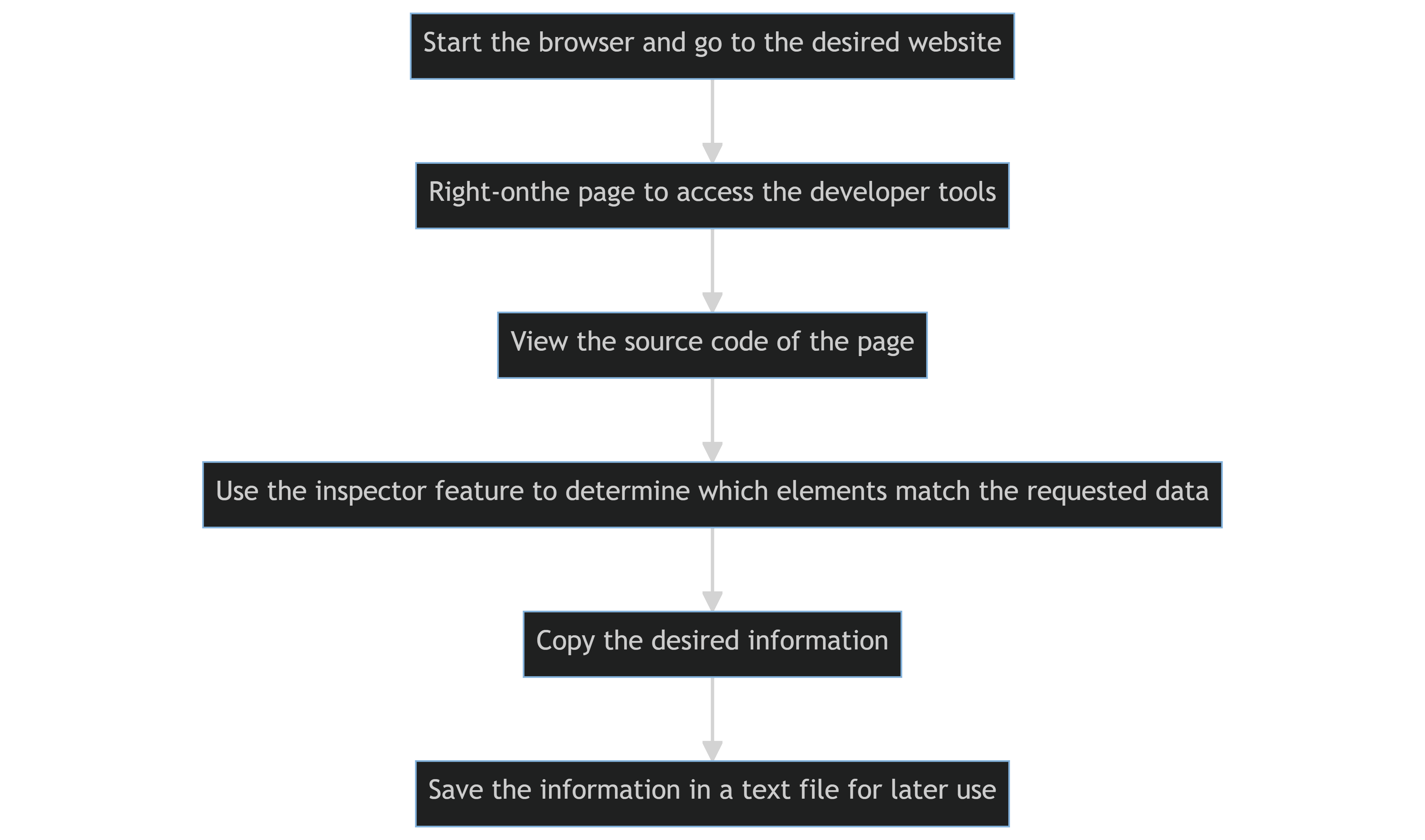
Le code source d'une page web est consulté et extrait manuellement à l'aide des outils de développement d'un navigateur web.
Les étapes fondamentales sont les suivantes :
- Ouvrez le navigateur et accédez au site souhaité.
- Cliquez avec le bouton droit sur la page pour accéder aux outils de développement du navigateur.
- Consultez le code source de la page.
- Utilisez la fonction inspecteur de votre navigateur pour déterminer quels éléments de la page web correspondent aux données demandées.
- Copiez les informations souhaitées.
- Copiez les informations, puis enregistrez-les dans un fichier texte pour une utilisation ultérieure.
Quel est le processus du web scraping automatisé ?
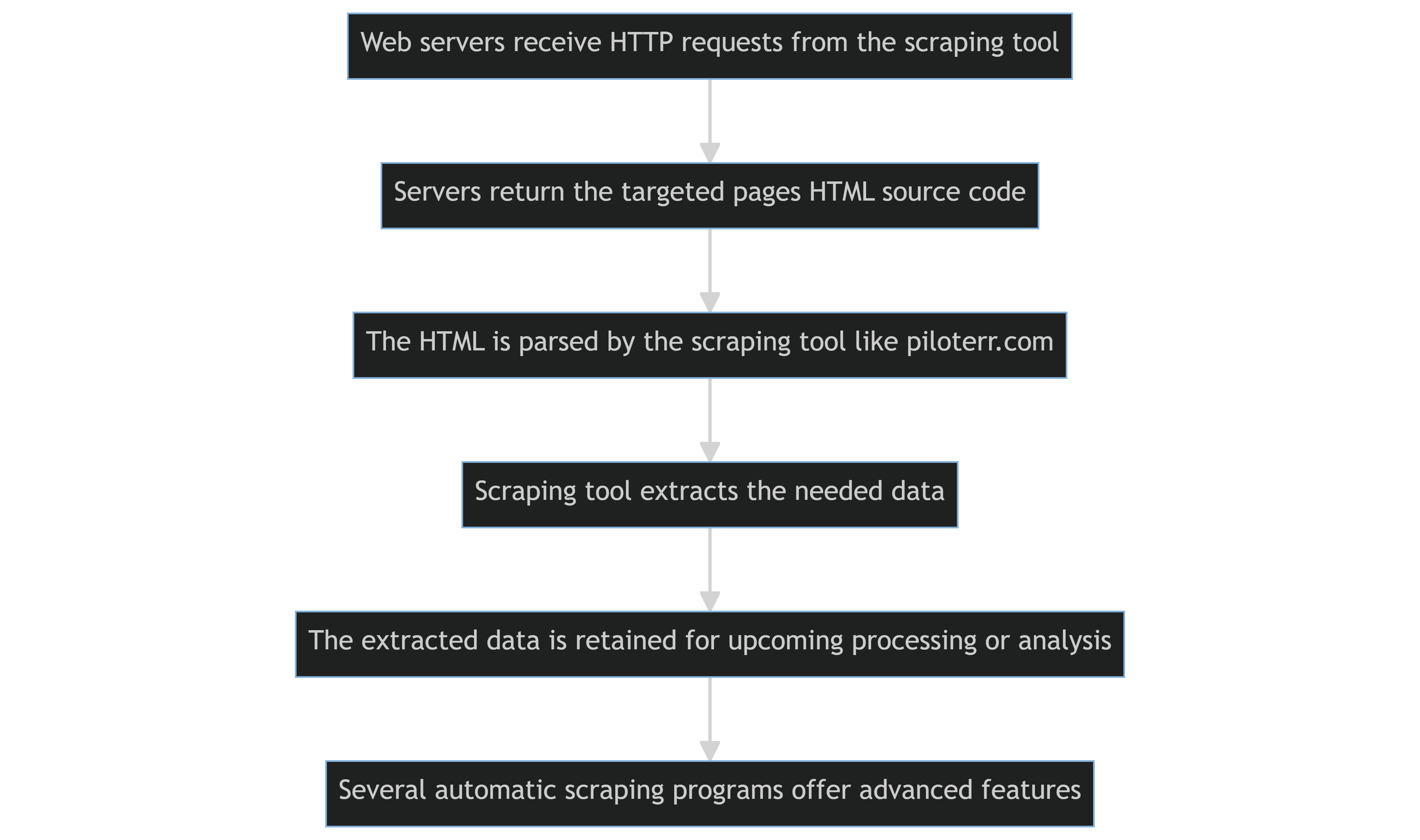
Le web scraping automatisé consiste à utiliser des technologies de scraping, comme des scripts Python ou des bibliothèques Scrapy, pour extraire du contenu depuis de nombreux sites web.
Les étapes fondamentales sont les suivantes :
- L'outil de scraping envoie programmatiquement des requêtes HTTP aux serveurs web hébergeant les sites ciblés.
- Les serveurs renvoient le code source HTML des pages ciblées.
- L'outil de scraping analyse le HTML, puis extrait les données nécessaires.
- Les données extraites sont conservées pour un traitement ou une analyse ultérieure.
- Plusieurs programmes de web scraping automatique peuvent offrir des fonctionnalités plus avancées, comme la gestion des cookies ou le contournement des conditions d'utilisation d'un site qui interdisent ou limitent le scraping de contenu.
Types de web scraping
Le web scraping peut être classé selon de nombreux critères, notamment auto-construit ou pré-construit, logiciel ou extension de navigateur, cloud ou local.
Web scraping auto-construit : Il est possible de créer ses propres web scrapers, mais cela exige un haut niveau de compétences en programmation. De plus, encore plus de connaissances sont nécessaires si vous souhaitez que votre web scraper dispose de fonctionnalités avancées. Les web scrapers pré-construits, en revanche, sont des scrapers déjà créés, simples à télécharger et à utiliser. Vous pouvez les personnaliser et y ajouter des options plus avancées.
Web scrapers en extension de navigateur : Des extensions pour votre navigateur, incluant des web scrapers, sont disponibles. Comme elles sont intégrées à votre navigateur, elles sont simples à utiliser, mais cela implique aussi certaines limitations. Les web scrapers en extension de navigateur ne peuvent pas utiliser de fonctions avancées dépassant les capacités de votre navigateur. En revanche, les web scrapers logiciels peuvent être téléchargés et installés sur votre machine, sans cette contrainte. Bien que plus avancés que les scrapers navigateur, ils offrent des fonctionnalités innovantes non limitées par les capacités de votre navigateur.
Web scrapers cloud : Les web scrapers cloud s'exécutent sur un serveur distant, généralement fourni par l'organisation auprès de laquelle vous achetez le scraper. Comme ils n'impliquent pas de scraper des données depuis des sites web sur votre machine, celle-ci peut se concentrer sur d'autres activités. Les web scrapers locaux, en revanche, utilisent les ressources locales de votre ordinateur pour fonctionner. Si les web scrapers nécessitent davantage de CPU ou de RAM, votre ordinateur ralentira et deviendra incapable de gérer d'autres opérations.
Le web scraping est-il légal ?
Le web scraping est généralement acceptable tant qu'il est réalisé à des fins raisonnables et ne contrevient pas aux réglementations sur le droit d'auteur, aux accords de licence ou aux conditions générales d'un site web.
La légitimité du web scraping dépend principalement de son usage prévu, des données consultées, des conditions d'utilisation du site et des lois sur la protection de la vie privée du pays où il est pratiqué.
Le web scraping n'est pas forcément complexe
Plusieurs programmes de web scraping généralistes présentent l'inconvénient d'être difficiles à apprendre et à utiliser. La courbe d'apprentissage est importante. WebHarvy a été créé pour résoudre ce problème. Grâce à son interface point-and-click très simple, WebHarvy vous permet de commencer à scraper des données depuis n'importe quel site web en quelques minutes seulement.
Quels outils peuvent être utilisés pour le web scraping ?
Des compétences en programmation sont nécessaires pour le web scraping, Python étant le langage le plus couramment utilisé pour cette tâche. Heureusement, Python propose de nombreux modules open source qui simplifient considérablement le web scraping. En voici quelques-uns :
BeautifulSoup est une autre bibliothèque Python fréquemment utilisée pour extraire des données de documents XML et HTML. L'organisation de ce contenu traité en arborescences plus conviviales par BeautifulSoup facilite grandement la navigation et la recherche dans de vastes volumes de données. C'est souvent l'outil préféré des analystes de données.
Scrapy est un framework applicatif basé sur Python qui parcourt le web et en extrait des données structurées. Il est fréquemment employé pour le traitement d'informations, la data mining et la préservation de contenu historique. Il peut servir de web crawler généraliste ou extraire des données via des API, en plus du web scraping pour lequel il a été spécialement conçu.
Pandas
Pandas est une autre bibliothèque Python généraliste pour la manipulation et l'indexation de données. Elle peut être utilisée conjointement avec BeautifulSoup pour le web scraping. L'avantage principal de pandas est que les analystes n'ont pas besoin de basculer vers d'autres langages, comme R, pour mener à bien le processus d'analyse de données.
D'autres outils sont disponibles, allant de ceux destinés au scraping généraliste à ceux conçus pour des tâches plus complexes et spécialisées. La meilleure approche consiste à identifier quelles technologies correspondent le mieux à vos intérêts et à votre niveau de compétence, puis à les intégrer à votre boîte à outils d'analyse de données.
Comment empêcher le scraping du contenu de votre site web ?
Le fait que le scraping de contenu de sites web soit si fréquemment utilisé à des fins légitimes, comme le référencement (SEO), rend difficile sa prévention. Les éditeurs peuvent employer les techniques suivantes pour réduire le risque que leur contenu soit scrapé de manière illégale ou non autorisée :
- Fichiers Robots.txt : Les fichiers robots.txt peuvent être lus par les web crawlers et scrapers pour déterminer quels sites sont autorisés à être consultés et scrapés.
- CAPTCHAs : En imposant des tests simples pour les humains mais difficiles pour les programmes informatiques, les CAPTCHAs peuvent bloquer les outils de scraping indésirables.
- Limites de requêtes : Utilisez des règles de « limites de requêtes » pour restreindre la fréquence à laquelle un site web peut recevoir des requêtes HTTP de la part de scrapers.
- Obfuscation de code : Employez des techniques comme la minification (le terme « minification » désigne le processus de modification du code pour supprimer les caractères et éléments superflus), le renommage de variables et de fonctions, ou l'encodage pour rendre le JavaScript difficile à lire et à comprendre.
- Blocage IP : Surveillez les journaux serveur pour détecter l'activité de scrapers et bloquez les adresses IP suspectes.
- Action en justice : Engagez des poursuites pour stopper le scraping non autorisé en adressant une plainte à l'hébergeur ou en demandant une injonction judiciaire.
Méthodes pour scraper des données depuis des sites web
Définir les URL cibles : Établissez une liste des URL cibles (c'est-à-dire les pages web dont vous extrairez les données) une fois que vous avez déterminé quel site scraper. N'oubliez pas d'examiner les pages web pour identifier précisément les données que vous souhaitez extraire.
Accéder au site en envoyant une requête HTTP : HTTP est un protocole de couche application permettant d'organiser les requêtes et réponses sur internet. Les données doivent être transférées d'un point à un autre via le réseau selon le mécanisme client-serveur d'HTTP. Votre ordinateur ou smartphone peut jouer le rôle de client, tandis que l'hébergeur web est le serveur, prêt à fournir les données après une requête réussie. Lorsque le client demande des données au serveur, ce dernier requiert une réponse GET. Notez que les méthodes pour envoyer des requêtes HTTP varient selon les programmes et les langages informatiques. Le serveur fournit les données en réponse à la requête HTTP, vous permettant de consulter la page HTML ou XML.
Télécharger le contenu des pages depuis les URL cibles (téléchargement de données) : Le téléchargement de données vous permet de télécharger une page web et d'en afficher le contenu à l'écran.
Extraire les informations de la page (parsing de données) : Après extraction des données depuis les URL cibles, vous devez les parser pour les rendre plus compréhensibles et adaptées à l'analyse de données. Le parsing de données est nécessaire car les données HTML brutes sont difficiles à interpréter. Les données doivent d'abord être présentées dans un format compréhensible pour l'analyste de données. Cela peut impliquer la production de rapports à partir de chaînes HTML ou la création de tableaux de données affichant les informations pertinentes.
Formater les données extraites : Les données parsées peuvent ensuite être exportées vers un tableur Excel, Google Sheets ou CSV. Vous pouvez utiliser des API, car de nombreuses solutions de web scraping automatisé acceptent des formats comme JSON.
Prévention du web crawling
Certaines mesures de sécurité standard ne sont plus efficaces face à l'intelligence des bots scrapers malveillants. Par exemple, les bots headless peuvent se faire passer pour des humains afin d'échapper à la détection par la plupart des techniques d'atténuation. Imperva emploie une analyse détaillée du trafic pour contrer les avancées des opérateurs de bots malveillants. Elle garantit que le trafic humain et automatisé vers votre site web est entièrement légitime.
Plusieurs critères sont recoupés pendant le processus, notamment :
- Empreinte TLS : Un examen approfondi des en-têtes HTML constitue la première étape du processus de filtrage. Ceux-ci peuvent indiquer si un visiteur est dangereux ou sûr, humain ou bot. Les signatures d'en-têtes sont comparées à une base de données de plus de 10 millions de variantes connues, mise à jour régulièrement.
- Réputation IP : Collecte d'informations IP issues de toutes les attaques contre nos clients. Les visites provenant d'adresses IP ayant un historique d'utilisation dans des attaques sont considérées avec suspicion et font l'objet d'un contrôle approfondi.
- Analyse comportementale : La surveillance de la manière dont les utilisateurs interagissent avec un site web peut révéler des schémas de comportement inhabituels, comme des taux de requêtes anormalement élevés et des habitudes de navigation irrationnelles. Cela facilite l'identification des visiteurs qui sont en réalité des bots.
- Défis progressifs : Des défis progressifs sont utilisés pour filtrer les bots et réduire les faux positifs. Ces défis incluent la prise en charge des cookies et l'exécution de JavaScript. Un défi CAPTCHA peut, en dernier recours, éliminer les bots tentant de se faire passer pour des humains.
Exemples de web scraping
Lorsque des données sont extraites de sites web sans le consentement des propriétaires, la pratique est connue sous le nom de web scraping et peut être préjudiciable. Le scraping de prix et le vol de contenu en sont les deux cas d'usage les plus typiques.
Scraping de prix : Pour analyser les jeux de données des concurrents, un auteur de scraping de prix lance généralement des bots scrapers depuis un botnet. L'objectif est d'accéder aux données de prix, de sous-coter les concurrents et d'augmenter les ventes. Les attaques surviennent généralement dans des secteurs où les produits sont facilement comparables et où le prix influence fortement les achats. Les fournisseurs de voyages, les vendeurs de billets et les revendeurs d'électronique en ligne peuvent tous être victimes du scraping de prix.
Scraping de contenu : Le vol de contenu à grande échelle sur un site spécifique est appelé scraping de contenu. Les annuaires produits en ligne et les sites qui reposent sur du contenu numérique pour générer du trafic en sont des cibles fréquentes. Une attaque de scraping de contenu pourrait être fatale pour ces entreprises.
Pourquoi Python est-il un langage si apprécié pour le web scraping ?
Python semble être partout ces jours-ci ! C'est le langage le plus utilisé pour le web scraping, car il gère facilement la plupart des tâches. Il propose également plusieurs bibliothèques conçues spécifiquement pour le web scraping. Scrapy, basé sur Python, est un framework open source de web crawling très connu. Il est idéal pour l'extraction de données via API comme pour le web scraping. Beautiful Soup est une autre bibliothèque Python excellente pour le web scraping. Elle produit un arbre de parsing pour extraire des données du HTML d'un site web. Beautiful Soup offre diverses fonctionnalités pour naviguer, rechercher et modifier ces arbres de parsing.