Garantir une haute qualité de données dans les opérations de web scraping est un défi multidimensionnel, crucial pour des analyses et des prises de décision fiables. À mesure que les projets de scraping se développent, la complexité de valider l'exactitude et l'exhaustivité des données collectées augmente, pouvant dégrader la qualité. Cet article présente une vue d'ensemble des techniques pour renforcer l'intégrité des projets de web scraping.
Des données fiables commencent par une extraction fiable: explorez les API Scraper et notre glossaire qualité des données.
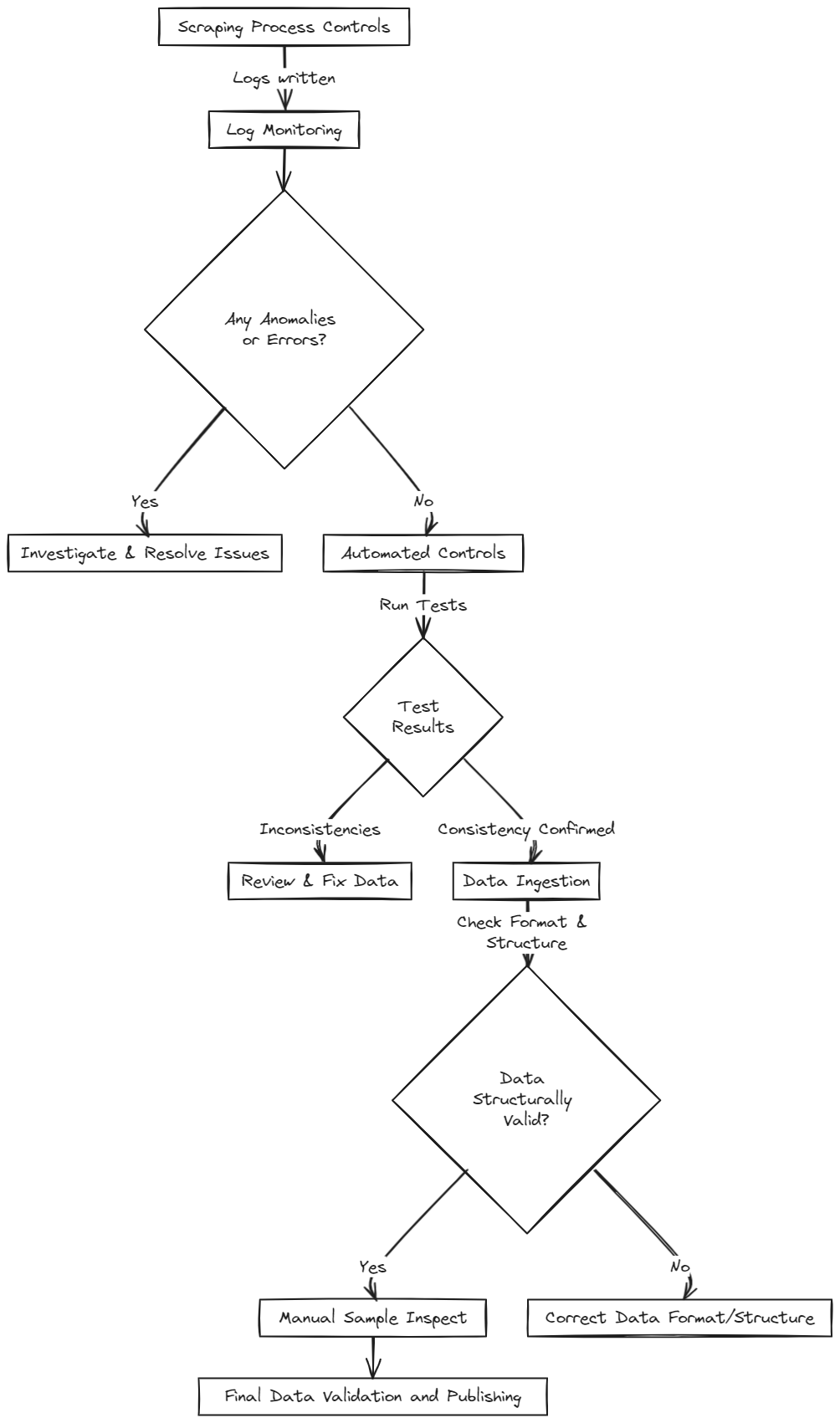
Monitoring du processus de scraping
**Une gestion efficace de la qualité des données commence par des scrapers bien conçus qui journalisent leur activité, mettant en évidence les problèmes potentiels via les codes de retour HTTP. Par exemple, une erreur 404 indique une page manquante, possiblement due à un lien cassé ou à une mesure anti-bot, entraînant des données partielles ou incomplètes. La collecte de ces logs, comme avec Scrapy, est essentielle pour le dépannage.
Ingestion des données
**Les changements de structure des pages web peuvent casser les sélecteurs, capturant des données dans des formats inattendus. Mettre en place des contrôles lors du chargement en base offre un point de contrôle centralisé pour maintenir la cohérence des données provenant de plusieurs sources de scraping.
Contrôles automatiques de qualité des données
**Selon le type de données, divers contrôles automatiques peuvent être instaurés. Les champs numériques, comme les prix produits, peuvent être validés automatiquement pour leur cohérence, tandis que les données qualitatives, comme les champs texte, peuvent nécessiter des stratégies différentes.
Exhaustivité et cohérence des données
**L'exhaustivité des données est une métrique fondamentale, avec des alertes configurées pour les écarts dans le nombre d'éléments attendus. Par exemple, Retailed.io utilise une méthode Ground Truth, où les développeurs fournissent le nombre d'éléments attendus, revu par les pairs et mis à jour. Des écarts significatifs déclenchent des alertes, suspendant la publication des données jusqu'à vérification.
Qualité des données qualitatives
Les contrôles automatiques ont des limites avec les champs qualitatifs. Certains contrôles sur des valeurs de domaine connues ou des validations de format (e-mail, URL) sont possibles, mais la validité réelle du contenu, comme les descriptions produits, peut nécessiter une inspection manuelle.
Publication des données
**Seules les données ayant passé avec succès tous les contrôles de qualité précédents doivent être publiées.