Environ 20 % des sites web que vous devez scraper utilisent Cloudflare, un système robuste de protection anti-bot capable de vous bloquer facilement. Indeed fait partie des sites protégés par le système anti-bot de Cloudflare, avec son défi bien connu « Verify you are human » ou « Additional Verification Required ». Dans cet article, nous explorons les solutions possibles pour contourner leurs mesures anti-bot et scraper avec succès les pages d'offres d'emploi et les pages entreprise.
Vue d'ensemble du scraping Indeed
Indeed est structuré en plusieurs sections :
- Pages de résultats de recherche
- Pages d'offres d'emploi
- Pages profil entreprise
Qu'est-ce que le extraction de données ?
Le extraction de données, ou « web scraping », désigne l'extraction automatisée de données depuis un site web via un logiciel ou des scripts. Ce processus permet aux entreprises de collecter rapidement de grandes quantités d'informations, incluant offres d'emploi, détails entreprise et même profils utilisateurs. Par exemple, les données scrapées sur Indeed peuvent être précieuses pour l'analytique, le recrutement et la veille concurrentielle, mais doivent respecter des cadres juridiques stricts.
Comprendre l'importance du extraction de données sur Indeed
Le extraction de données permet aux entreprises et chercheurs de collecter des informations précieuses sur la plateforme Indeed, comme les tendances emploi, salaires, compétences requises et données employeurs. Ces données aident à prendre des décisions éclairées, mener des études de marché et créer des services innovants.
Comment les entreprises utilisent-elles les données collectées ?
Les entreprises utilisent les données scrapées pour suivre les tendances sectorielles, analyser la concurrence, améliorer leurs stratégies de recrutement et produire des informations sur le marché de l'emploi. Ces données permettent d'optimiser les pratiques d'embauche, de construire des produits [pilotés par les données](/dictionary/fondée sur les données-decision-making) et de mieux comprendre la demande du marché. Scraper Indeed requiert une approche stratégique en raison de la structure de la plateforme et des protections en place, notamment les mesures anti-bot de Cloudflare. Comprendre l'organisation d'Indeed et comment contourner ces protocoles de sécurité vous aidera à collecter efficacement les données dont vous avez besoin.
Méthode 1 : explorer le processus de web scraping
Étapes principales pour créer un web scraper Indeed
- Définir vos objectifs
Définissez clairement les données à extraire d'Indeed : intitulés de poste, localisation(s), salaires ou noms d'entreprise. Des détails précis facilitent le développement d'un scraper efficace et évitent la collecte de données superflues. - Analyser les éléments des pages d'offres : utilisez les outils de développement du navigateur pour examiner la structure des pages d'offres ou entreprise. En identifiant les éléments HTML pertinents, vous pouvez localiser et extraire le texte requis depuis les résultats de recherche.
- Gérer la protection Cloudflare : Indeed emploie la protection anti-bot de Cloudflare, qui peut entraver les tentatives de scraping. Pour surmonter ces protections, des outils comme
Cloudscraper,FlareSolverr,Cfscrapeou d'autres solveurs Cloudflare peuvent être utiles. Ces outils émulent le comportement de navigation humaine et aident le scraper à surmonter les défis CAPTCHA et autres mécanismes de détection de bots. - Développer votre web scraper : utilisez des bibliothèques Python comme
Beautiful Soup,Scrapy,Cheeriooulxmlpour développer votre scraper. Ces bibliothèques aident à naviguer sur les pages Indeed, parser le HTML et extraire les données/texte/images souhaités. - Gérer les limites de débit : scraper trop rapidement déclenche les protections anti-bot. Pour éviter le blocage, intégrez des proxies rotatifs et des délais entre requêtes pour imiter la navigation humaine. Vous collecterez ainsi de grands volumes de données tout en restant discret.
- Parser et nettoyer les données : après extraction, nettoyez et structurez les données pour l'analyse. Supprimez les caractères superflus et formatez les données d'offres d'emploi.
- Stockage des données : une fois nettoyées, stockez les données dans un format efficace, comme une base Postgres (Supabase, Airtable…) ou un fichier CSV. Cela facilitera l'analyse, la visualisation ou le traitement selon vos besoins. Maintenance régulière : le scraping nécessite une maintenance continue. Surveillez et mettez à jour régulièrement votre scraper pour vous adapter aux changements de structure des pages Indeed, aux mises à jour de contenu et à l'évolution des protocoles de sécurité, y compris les défenses Cloudflare.
Comprendre Cloudflare Bot Management
Cloudflare fournit des services de diffusion de contenu et de sécurité web, dont son pare-feu applicatif web (WAF), qui protège les sites contre des menaces comme le cross-site scripting (XSS), le credential stuffing et les attaques par déni de service distribué (DDoS).
Un composant essentiel de Cloudflare est le Bot Manager, conçu pour protéger les sites du trafic bot malveillant. Le Bot Manager identifie et atténue les attaques de bots sans perturber les utilisateurs légitimes. Cependant, Cloudflare considère tout trafic bot inconnu ou non whitelisté, comme les web scrapers, comme malveillant. Ainsi, même les tentatives de scraping légitimes peuvent être bloquées, refusant l'accès aux sites protégés par Cloudflare.
Ces erreurs s'accompagnent souvent d'un code de réponse HTTP Cloudflare 403 Forbidden, indiquant que la requête a été bloquée pour activité bot suspectée. Pour contourner ces protections, des solveurs Cloudflare spécifiques ou des techniques comme les proxies rotatifs, l'imitation du comportement humain ou l'utilisation de navigateurs headless peuvent être nécessaires.
Mauvais exemple de scraper Python pour les offres
L'extrait de code suivant montre un exemple de requête HTTP et de parsing visant à extraire des données d'offres depuis Indeed avec des bibliothèques Python comme httpx et re :
import httpx
import re
import json
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
}
def parse_search_page(html: str):
data = re.findall(r'window.mosaic.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});', html)
if data is not None and data != 'null':
return json.loads(data[0])
response = httpx.get("https://www.indeed.com/viewjob?jk=cbce6eaf017aa47b", headers=headers)
print(parse_search_page(response.text))
Cette requête échoue, car le site Indeed emploie des protections anti-bot, notamment via Cloudflare, qui bloque les requêtes HTTP ne simulant pas le comportement humain. Des bibliothèques comme httpx ou requests sont généralement inefficaces face à ces protections. Pour contourner Cloudflare, vous avez besoin d'outils comme des navigateurs headless ou des API de scraping dédiées capables d'imiter plus fidèlement les interactions humaines.
Méthode 3 : API de web scraping pour contourner Cloudflare
Bien que les techniques mentionnées dans cet article puissent être utiles, elles ne garantissent pas le succès à tout moment, Cloudflare mettant fréquemment à jour ses mesures de sécurité. La méthode la plus fiable pour gérer Cloudflare est d'utiliser une API de web scraping, comme Piloterr. Elle gère toutes les méthodes de détection de Cloudflare en coulisses, vous permettant de vous concentrer sur votre logique de scraping sans vous soucier du contournement anti-bot.
Piloterr fonctionne avec tous les langages de programmation. Une seule requête API suffit pour contourner Cloudflare et récupérer les données dont vous avez besoin.
Pour voir comment Piloterr fonctionne, utilisons-le pour accéder aux offres Indeed, un site fortement protégé par Cloudflare.
Code Python :
# Install the requests module if needed
import requests
# Indeed URL
url = 'https://www.indeed.com/jobs?q=senior+java+developer&l=berlin'
api_key = ''
# Request parameters for the Piloterr API
params = {
'query': url,
'wait_in_seconds': 10
}
# Sending a GET request to the Piloterr API
response = requests.get(
'https://piloterr.com/api/v2/website/rendering',
params=params,
headers={'x-api-key': api_key}
)
# Printing the raw HTML of the Indeed page
print(response.text)
Avec cette requête, vous obtenez toutes les offres contenant le mot-clé « Senior Java Developer » dans la localisation « Berlin ».
Consultez la documentation pour configurer la requête de scraping. Collez simplement l'URL cible, ajoutez un wait_in_seconds entre 5 et 20 secondes, et vous pourrez effectuer une simple requête HTTP pour rechercher des offres (et contourner l'anti-bot Cloudflare), scraper URLs et texte sans difficulté.
Méthode 4 : scraper les pages entreprise Indeed avec Python
Si vous souhaitez scraper des données entreprise sur Indeed, Piloterr propose une API de web scraping dédiée pour simplifier et optimiser le processus. En utilisant cette API, vous contournez la protection Cloudflare et obtenez des données JSON structurées sur les entreprises Indeed.
Cas d'usage : scraper les informations entreprise avec Python
Pour récupérer les informations d'une entreprise spécifique sur Indeed, suivez ces étapes :
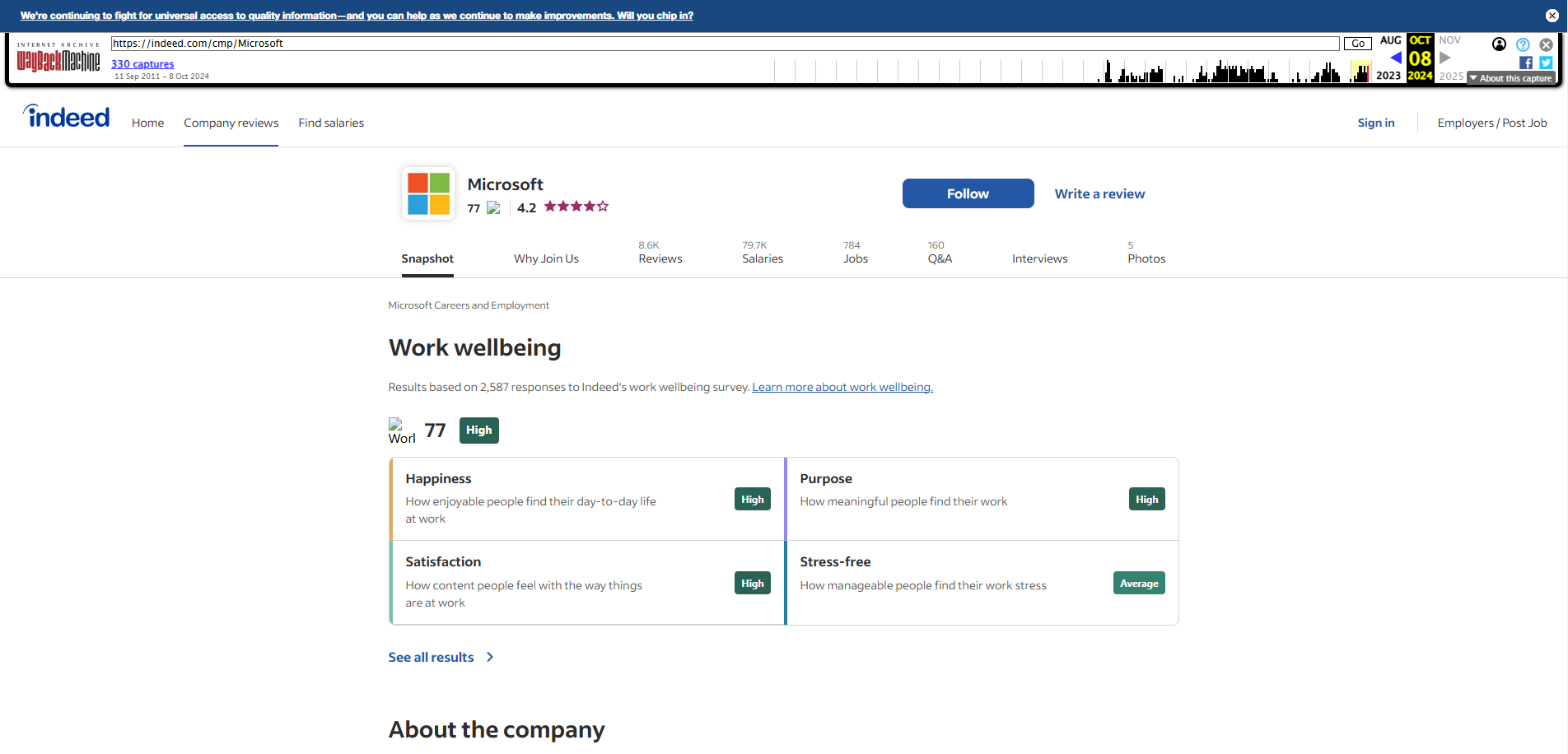
- Choisir l'entreprise : trouvez l'URL entreprise sur Indeed (ex. https://indeed.com/cmp/Microsoft).
- Appel API : utilisez une requête GET vers l'endpoint dédié Piloterr pour les informations entreprise Indeed.
Code Python :
import requests
# Define the API URL for company information
url = 'https://indeed.com/cmp/Microsoft'
api_key = ''
# Set the API endpoint and parameters
api_endpoint = 'https://piloterr.com/api/v2/indeed/company/info'
params = {'query': url}
# Send the GET request with the API key
response = requests.get(api_endpoint, params=params, headers={'x-api-key': api_key})
# Print the JSON response containing the company data
print(response.json())
Réponse :
{
"founded": 1975,
"revenue": "over-$10B (USD)",
"website": "http://www.microsoft.com/",
"industry": "Information Technology",
"logo_url": "https://d2q79iu7y748jz.cloudfront.net/s/_squarelogo/96x96/88813b3f866a5b58c9685073e3b87e05",
"company_url": "https://indeed.com/cmp/Microsoft",
"description": "There's work, and then there's your life's work...",
"headquarter": "One Microsoft Way Redmond, Washington 98052-6399",
"staff_range": "over-10000",
"company_name": "Microsoft",
"dynamic_sections": {...},
"similar_companies": {...}
}
- Traiter le JSON : la réponse inclut les informations entreprise au format JSON, facilitant l'analyse du texte et l'intégration dans vos applications.
En utilisant cet endpoint, vous gagnez du temps : la réponse est déjà structurée en JSON, permettant une intégration fluide avec votre logique de scraping sans parser du HTML brut.
Note : il ne contient pas d'URLs ni d'offres d'emploi ; cet endpoint API se concentre sur les informations entreprise. Certains champs de la réponse JSON peuvent être null si l'information n'est pas disponible ou si Indeed a restreint l'accès à certaines données. Assurez-vous que votre code Python gère ces cas pour éviter des erreurs de traitement.
Cet endpoint fait gagner du temps, la réponse étant déjà structurée en JSON pour une intégration fluide sans parser du texte HTML brut. Consultez la documentation Piloterr pour des options supplémentaires, comme le temps d'attente en secondes, les paramètres de recherche ou l'ajustement des en-têtes user-agent pour améliorer la qualité de la réponse.
Avec Piloterr, vous pouvez aussi scraper les offres directement depuis les profils entreprise Indeed, comme cette URL : indeed.com/cmp/Google/jobs. L'Indeed Job Scraper permet d'extraire des données précieuses : intitulé, description, nom d'entreprise, localisation, salaire, notes, type de contrat, etc.
Scraper les données entreprise Indeed
Voici des cas d'usage précieux :
1. Analyse salariale et benchmarking / en utilisant les données salariales des offres, vous pouvez :
- Comparer la rémunération selon les postes et localisations
- Suivre les tendances salariales pour des postes spécifiques
- Aider les candidats à négocier de meilleures conditions
Par exemple, d'après les données, les salaires de Software Engineer chez Microsoft varient significativement selon la localisation et l'expérience.
2. Veille marché de l'emploi / les données fournissent des informations sur :
- Les intitulés de poste recherchés et leur demande (ex. Microsoft compte 339 postes en développement logiciel)
- La répartition géographique des opportunités (ex. Redmond, WA compte 438 ouvertures)
- Les tendances de recrutement et axes prioritaires des entreprises
3. Planification de parcours professionnel / les données structurées sur les intitulés permettent de :
- Cartographier les parcours d'évolution
- Identifier les compétences requises pour progresser
- Comparer les rôles entre entreprises (ex. Senior Program Manager vs Project Manager)
4. Analyse de la culture d'entreprise / en utilisant les données d'avis et de notes :
- Analyser la satisfaction au travail (note globale de 4,2 pour Microsoft)
- Comparer l'équilibre vie pro/perso entre entreprises
- Évaluer les valeurs et l'expérience employé
5. Préparation aux entretiens / les données d'entretien fournissent :
- Des informations sur la durée du processus (« environ deux semaines »)
- Les niveaux de difficulté (notés « MEDIUM »)
- Les questions et expériences d'entretien courantes pour un poste
- Des retours d'entretien par localisation
6. Veille concurrentielle / les entreprises peuvent :
- Surveiller les schémas de recrutement des concurrents
- Comparer avantages et rémunération pour un poste
- Suivre l'expansion vers de nouveaux marchés ou technologies
- Analyser les entreprises similaires dans leur secteur
Ces données sont particulièrement précieuses pour les professionnels RH, candidats et analystes métier souhaitant prendre des décisions [pilotées par les données](/dictionary/fondée sur les données-decision-making) sur l'emploi et les tendances du marché du travail.
Méthode 5 : alternatives au cache Google
Bien que Google n'offre plus l'accès aux pages en cache, vous pouvez encore consulter des versions archivées de nombreux sites via des services comme WebCite et Internet Archive. Ces sites fournissent des instantanés de pages web, permettant d'accéder au contenu de sites protégés sans visiter directement leur domaine ni passer par le CDN de Cloudflare.
Pour utiliser les archives lorsque les autres méthodes échouent, voici quelques étapes :
- Vérifier la disponibilité et la fraîcheur des données : assurez-vous que les données archivées sont présentes et suffisamment récentes pour vos besoins. Évaluer la pertinence est crucial.
- Évaluer le niveau de sécurité : considérez si la sécurité de l'archive est inférieure à celle du site original. Cela peut influencer la sécurité et l'intégrité des données extraites.
Si ces conditions sont remplies, explorez l'archive du site cible pour voir si une version en cache est accessible.
Méthode 6 : scraper les intitulés de poste développeur avec Python
Si vous devez automatiser la récupération de suggestions d'intitulés liés à « developer », vous pouvez utiliser un script simple pour interagir avec l'endpoint Indeed de suggestions d'autocomplétion. Cela vous aide à obtenir une liste d'intitulés pertinents fréquemment associés aux rôles développeur, offrant des informations sur des postes similaires ou connexes.
Vous pouvez utiliser le script Python suivant pour scraper et parser le texte, en extrayant uniquement les suggestions d'intitulés pertinentes :
import httpx
def get_job_title_suggestions(query="cto"):
url = "https://autocomplete.indeed.com/api/v0/suggestions/cmp-what-with-top-companies"
params = {
"country": "US",
"language": "en",
"count": 10,
"counts": 10,
"formatted": 1,
"query": query
}
response = httpx.get(url, params=params)
if response.status_code == 200:
suggestions = [item['suggestion'] for item in response.json() if item['suggestion'] != 'null']
return suggestions
else:
return []
# Retrieve CTO-related job titles
cto_suggestions = get_job_title_suggestions("cto")
print(cto_suggestions)
Ce script envoie une requête HTTP à l'API Indeed et affiche une liste d'intitulés suggérés liés à « developer ». Cet endpoint Indeed n'est actuellement pas protégé par Cloudflare, mais cela pourrait changer.
Note : la même approche permet de récupérer des suggestions de localisation depuis Indeed, fournissant une liste de villes pertinentes. Cela est particulièrement utile lors du développement d'une application web pour éviter des résultats null côté client en préremplissant les champs de recherche avec des options valides.
Indeed autorise-t-il le scraping d'offres d'emploi ?
La légalité du extraction de données est régie par le droit de la propriété intellectuelle et la protection des données. Le Code de la propriété intellectuelle encadre l'extraction de données en termes d'usage, de quantité et d'intention. Voici un résumé de ce qui est généralement autorisé :
- Extraction non substantielle de données : extraire une petite portion non substantielle de données publiquement disponibles pour un usage privé est typiquement autorisé. Cette approche garantit que les utilisateurs ne collectent qu'un minimum de données, sans compromettre la valeur de la base.
- Usage privé et non commercial : une extraction à plus grande échelle peut être acceptable si elle est à des fins personnelles et non commerciales. Cependant, tous les droits de propriété intellectuelle et de confidentialité doivent être respectés.
- Usage académique et recherche : à des fins éducatives ou de recherche, une quantité plus substantielle de données peut être extraite. Cet usage est typiquement non commercial et destiné à un public limité (étudiants, chercheurs), minimisant le risque de violation des conditions de la plateforme.
Conformité aux conditions Indeed
Les Conditions d'utilisation d'Indeed interdisent explicitement le scraping à des fins commerciales sans autorisation. Elles restreignent l'usage de « bots, scripts ou API » pour scraper des données du site, surtout lorsque les données servent à des fins concurrentielles, de profilage ou de collecte massive.
Exemple de clause : « You agree not to use any robot, spider, scraper, or other automated means to access the Indeed site for any purpose without Indeed's express written permission. »
La violation de ces conditions peut entraîner des actions en justice et des amendes importantes. Indeed se réserve le droit de demander réparation pour les dommages causés par un scraping non autorisé, pouvant représenter des pertes financières et réputationnelles significatives pour l'entreprise fautive.
Puis-je utiliser l'API Indeed pour scraper des offres d'emploi ?
Depuis juin 2023, Indeed propose une gamme d'API pour les développeurs gratuitement. Cependant, ces API sont principalement destinées au côté recruteur de la plateforme. Elles sont utiles pour intégrer Indeed aux systèmes de suivi des candidatures, suivre les conversions ou planifier des entretiens, mais ne sont pas conçues pour la recherche d'emploi.
Auparavant, la Publisher Jobs API (incluant Get Job et Job Search) était disponible spécifiquement pour la recherche d'emploi, permettant de collecter intitulés, noms d'entreprise, descriptions, localisations et dates de publication. Depuis la dépréciation de ces API, les utilisateurs se tournent vers des alternatives, comme un scraper Indeed, pour accéder à des données similaires.
Conclusion
En conclusion, le data scraper sur Indeed permet d'accéder à une richesse d'informations précieuses, incluant offres d'emploi, entreprises, localisations et autres détails utiles. Grâce aux méthodes décrites, notamment l'utilisation d'API de scraping comme Piloterr, il est possible d'extraire des données texte depuis une simple URL tout en contournant des protections comme Cloudflare. Cette approche fournit aux entreprises des informations critiques pour améliorer leurs stratégies de recrutement, l'analyse concurrentielle et les études de tendances du marché. Il reste crucial de respecter les conditions d'utilisation d'Indeed pour garantir un usage légal de ces données.