Open-source community is thriving, especially in these times when AI is everywhere and demands an ever-increasing amount of data for its models. This trend has led to a rise in web scraping activities, but it has also prompted the development of more advanced anti-bot measures. With that in mind, let me share some of the most impressive Python libraries for leveraging AI in web scraping and overcoming anti-bot protections.
Skip the library stack: use anti-bot bypass with 400+ library endpoints included.
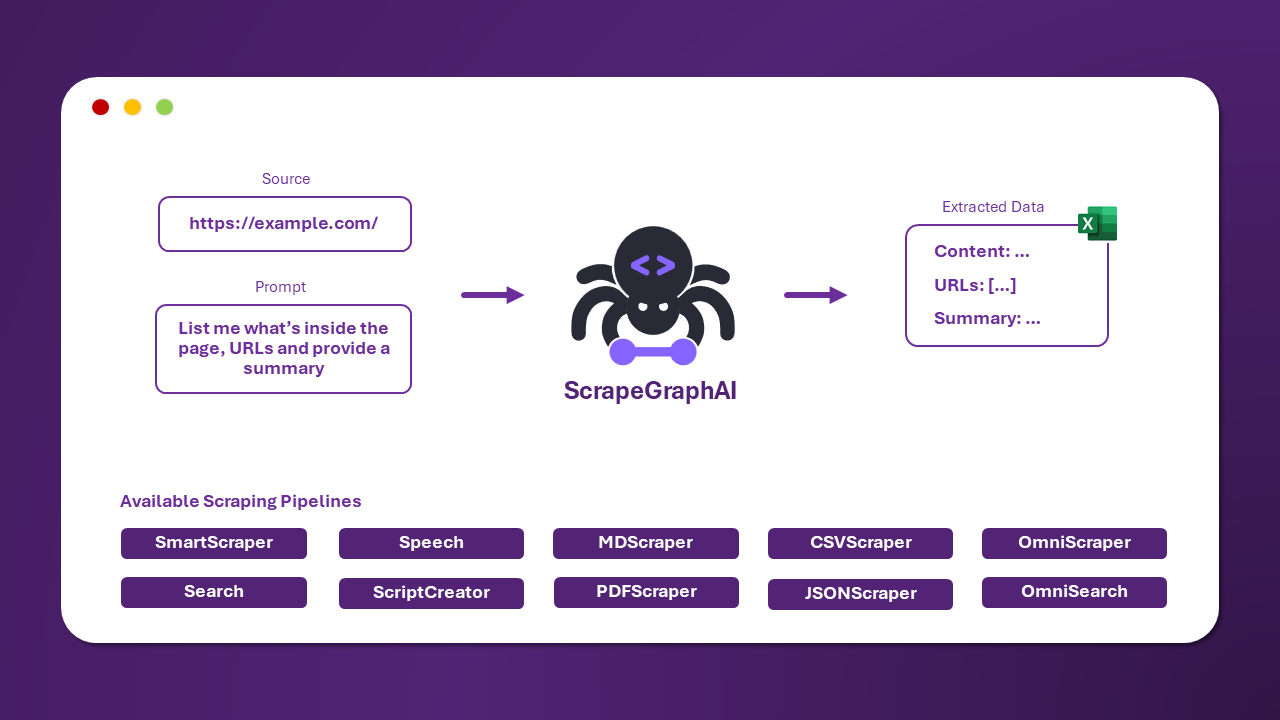
ScrapeGraphAI
With ScrapeGraphAI, you can connect your preferred LLM (locally or online) and:
- Extract data from single or multiple pages by defining a target data schema.
- Extract data from search engine results.
- Generate audio files from extracted website data.
- Automatically write Python code for your scraper using libraries like BeautifulSoup.
While LLMs are becoming more affordable and accurate, their response times still aren't ideal for production-level web scraping projects. The best use of this technology in web scraping, in my opinion, is for automatically writing and fixing scraper code, leaving the execution to current frameworks. They’re also working on extracting data from local documents, which I’m excited to see. You can track their progress by joining their Discord server.
Scrapoxy
You might recognize Fabien Vauchelles, the creator of Scrapoxy, from his insightful talks on bots and anti-bot technologies at various web scraping events and webinars. Scrapoxy is a powerful proxy aggregator that enables you to manage proxies from various providers, both free and commercial.
What sets Scrapoxy apart is its innovative management of datacenter proxies. By creating and rotating virtual machines across different cloud providers, Scrapoxy allows you to build an almost infinite pool of IPs with unlimited bandwidth. Moreover, it’s not just limited to this functionality; by using a single endpoint in your scrapers, you can mix different proxy providers and types, further enhancing your scraping capabilities.
Botasaurus
Botasaurus is another robust framework that’s well worth exploring. It supports the creation of both headless and headful scrapers. During my initial tests a few months ago, Botasaurus demonstrated its ability to bypass detection by Cloudflare and other anti-bot systems, although it has some limitations.
When running a headful scraper from a datacenter, Botasaurus currently lacks advanced options for masking your browser fingerprint, which can lead to blocks. Despite this, it’s a tool to keep on your radar.
Nodriver
Nodriver is the successor to Undetected-Chromedriver, eliminating the need for Selenium and webdrivers. It’s fully asynchronous, offering a fast tool for scraping that’s natively optimized to stay undetected by most anti-bot solutions, all with just a few lines of code. You can also manage different profiles, providing everything you need for your scrapers. Additionally, it includes utilities for smart element lookup, session management, and seamless integration with existing undetected_chromedriver instances, making it a versatile and powerful tool for automated web tasks.
Undetected Playwright
Undetected Playwright is a patch that you can apply to your Playwright scrapers to improve their undetectability against anti-bot systems. We’ve seen this patch in action in an article on CDP detection techniques, where it significantly improved our scrapers’ performance in bypassing these increasingly common anti-bot methods.
Camoufox
Camoufox is a browser currently under development that was recently shared in our Discord server by its author. It looks very promising. Built on Firefox, the author stripped down unnecessary features and added TLS masking, Browserforge for altering the browser’s fingerprint, and several other features. Tests conducted on well-known websites like Browserscan seem promising, and I’m eager to try it out.