Aprenda como fazer scraping no Amazon usando cabeçalhos User-Agent para evitar detecção e BeautifulSoup para analisar conteúdo HTML. Este guia abrangente também inclui um exemplo completo de caso de uso que demonstra o processo de extração de informações de produtos, como títulos, preços e avaliações, usando Python.
Evite a manutenção: use a Amazon Scraping API ou Amazon Product API para saída estruturada em JSON.
Introdução ao web scraping
O que é Web Scraping?
Web scraping é um método usado para extrair automaticamente grandes quantidades de conteúdo de websites. O principal objetivo do web scraping é coletar e estruturar informações da web, que podem então ser usadas para diversas aplicações. Esse conteúdo pode incluir texto, imagens, vídeos e outras formas de mídia disponíveis em páginas da web. Ao automatizar o processo de extração, o web scraping permite que os usuários leiam, pesquisem e analisem o conteúdo da web rapidamente, economizando tempo e esforço significativos em comparação com a coleta manual de dados.
Ferramentas e técnicas
Várias ferramentas e técnicas são empregadas no web scraping para garantir uma coleta eficiente de dados:
- Análise de HTML: Esta técnica envolve analisar a estrutura de uma página da web para coletar informações. Ferramentas como um scraper em Python e Cheerio (JavaScript) são comumente usadas para esse fim. Elas permitem a navegação pela estrutura da página e a recuperação de detalhes relevantes com base em tags, atributos e outros elementos.
- Análise de DOM: A análise do Document Object Model (DOM) envolve interagir com a estrutura DOM de uma página da web para coletar dados. Bibliotecas JavaScript como jQuery facilitam esse processo, permitindo a manipulação e consulta do DOM para recuperar informações específicas.
- Uso de Proxy: Muitos sites implementam medidas para limitar o acesso com base em endereços IP. Utilizando proxies, pode-se contornar essas restrições e acessar os URLs necessários sem ser bloqueado. Este método é frequentemente mais confiável e eficiente.
- Navegadores Headless: Ferramentas como Puppeteer e Selenium simulam interações com páginas da web ao renderizá-las em um navegador headless. Essa abordagem permite navegar por páginas da web complexas, lidar com a execução de JavaScript e coletar dados como se estivesse navegando manualmente.
- Expressões Regulares: Expressões regulares (regex) podem ser usadas para identificar padrões no conteúdo da página da web e coletar informações de acordo. Essa técnica é útil para tarefas específicas onde o conteúdo segue um padrão previsível.
Aviso legal e precauções
Este tutorial aborda técnicas populares de web scraping para fins educacionais. Interagir com servidores públicos requer diligência e respeito, e aqui está um bom resumo do que não fazer:
- Não faça scraping em taxas que possam danificar o site.
- Não faça scraping de avaliações ou textos que não estejam publicamente disponíveis.
- Não armazene informações pessoalmente identificáveis (PII) de cidadãos da UE protegidos pelo GDPR.
- Não reutilize conjuntos de dados públicos inteiros, pois isso pode ser ilegal em alguns países.
Ao pesquisar ou ler conteúdo, certifique-se de seguir diretrizes éticas e considerações legais. Para orientações mais detalhadas, você deve consultar um advogado.
Por que fazer scraping de produtos da Amazon?
Fazer scraping da Amazon oferece vários benefícios significativos para empresas, pesquisadores e indivíduos:
- Análise Competitiva: Ao usar um scraper para coletar informações da Amazon, as empresas podem ler descrições de concorrentes, avaliações de clientes e acompanhar a disponibilidade de itens. Isso ajudará no desenvolvimento de estratégias competitivas e no ajuste de suas próprias ofertas para se manter à frente no mercado.
- Pesquisa de Mercado: Fazer scraping da Amazon permite que as empresas pesquisem tendências de consumo, preferências e comportamentos de compra. Essas informações ajudam a identificar itens populares, entender as necessidades dos clientes e tomar decisões informadas sobre desenvolvimento e estratégias de marketing.
- Monitoramento de Preços: Varejistas e consumidores podem usar scraping para acompanhar mudanças de preços ao longo do tempo. Isso é particularmente útil para estratégias dinâmicas de preços, onde as empresas ajustam os valores com base na atividade dos concorrentes e na demanda do mercado.
- Agregação de Dados: Empresas que vendem em várias plataformas podem usar um scraper para agregar seu conteúdo, garantindo consistência em todos os canais. Isso ajuda a manter listagens precisas, gerenciar inventário e otimizar operações.
- Análise de Sentimento do Cliente: Ao analisar avaliações e classificações de clientes, as empresas podem obter insights sobre a satisfação e o desempenho do produto. Essas informações podem ser usadas para melhorar ofertas, resolver problemas comuns e aprimorar o atendimento ao cliente.
- Geração de Leads: Fazer scraping da Amazon pode ajudar a identificar leads potenciais e oportunidades de parcerias ou vendas. Por exemplo, empresas podem pesquisar revendedores, fornecedores ou influenciadores que estejam ativos em seu setor.
No geral, a capacidade de ler e fazer scraping de dados da Amazon é um recurso valioso que ajudará na tomada de decisões estratégicas e na melhoria da eficiência operacional.
Construindo um raspador básico da Amazon
Usando requests para buscar URLs da Amazon
Configurando o user-agent
Ao raspar sites, é importante configurar um User-Agent para imitar uma solicitação de navegador real. Isso ajuda a evitar bloqueios e obter a resposta correta do servidor. Em Python, você pode usar a biblioteca requests para configurar um User-Agent. Aqui está um exemplo:
import requests
import random
# Lista de user-agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 10; SM-G960F)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Mobile Safari/537.36'
]
# Escolha um user-agent aleatório
headers = {
'User-Agent': random.choice(user_agents)
}
url = 'https://www.amazon.com/dp/B0B72B7GM2' # URL do produto de exemplo
# Faz uma solicitação GET para a URL especificada com os headers escolhidos
response = requests.get(url, headers=headers)
# Imprime o código de status da resposta
print(response.status_code)
Neste exemplo, a string User-Agent é configurada para imitar um navegador comum, tornando menos provável que a solicitação seja bloqueada pelos servidores da Amazon.
Recuperando conteúdo HTML
Uma vez feita a solicitação, o próximo passo é recuperar o conteúdo da página da web. Isso pode ser feito usando o objeto de resposta obtido da chamada requests.get. Veja como você pode recuperar e imprimir o conteúdo:
if response.status_code == 200:
html_content = response.text
print(html_content)
else:
print(f"Falha ao recuperar a página da web. Código de status: {response.status_code}")
Este código verifica se a solicitação foi bem-sucedida (código de status 200) e, em seguida, recupera o conteúdo HTML como uma string de texto.
Analisando HTML com BeautifulSoup
O que é BeautifulSoup?
BeautifulSoup é uma biblioteca popular em Python projetada para raspagem de web e análise de documentos XML. Ela permite que um raspador navegue e manipule facilmente a estrutura de uma página da web, simplificando a extração de conteúdo. O BeautifulSoup pegará o código-fonte da página e construirá uma árvore de análise, que pode então ser pesquisada e modificada para extrair texto ou informações relevantes. É especialmente útil para raspar marcações mal formatadas ou inconsistentes. Ao usar o BeautifulSoup em Python, os desenvolvedores podem raspar conteúdo de sites de forma eficiente, automatizando o processo de coleta e organização de informações da web, tornando-se uma ferramenta poderosa para qualquer raspador.
Por que usar BeautifulSoup?
O BeautifulSoup é composto por diferentes ferramentas de análise, como soup, lxml e HTML5lib. Essa flexibilidade permite que você experimente vários métodos de análise e se beneficie de suas vantagens dependendo da situação. Uma das principais razões para usar o BeautifulSoup é sua facilidade de uso. São necessárias apenas algumas linhas em Python para criar um raspador que pode extrair conteúdo de páginas da web de forma eficiente. Apesar de sua simplicidade, ele é robusto e confiável, tornando-se uma escolha popular não apenas para desenvolvedores, mas também para aqueles que trabalham com raspagem de web em geral.
Com sua documentação clara e abrangente, o BeautifulSoup ajudará os raspadores a aprender rapidamente e resolver problemas de forma eficaz. Além disso, uma comunidade online ativa oferece várias soluções para os desafios que você pode enfrentar ao raspar, tornando-o uma ótima ferramenta tanto para iniciantes quanto para especialistas.
Encontrando título e preço do produto
Para analisar o conteúdo HTML e extrair informações específicas, como o título e o valor do produto, você pode usar a biblioteca Beautiful Soup.
O BeautifulSoup é uma biblioteca poderosa e fácil de usar em Python para extrair dados de arquivos HTML e XML, permitindo que os usuários naveguem, pesquisem e modifiquem o conteúdo de páginas da web de forma eficiente, tudo enquanto desfrutam da simplicidade dessas ferramentas de análise.
Aqui está um exemplo de como extrair esses detalhes:
Vamos examinar a estrutura da página de detalhes do produto.
Abra uma URL de produto, como https://www.amazon.com/dp/B0B72B7GM2, no Chrome ou em qualquer outro navegador moderno, clique com o botão direito do mouse no título do produto e selecione Inspecionar.
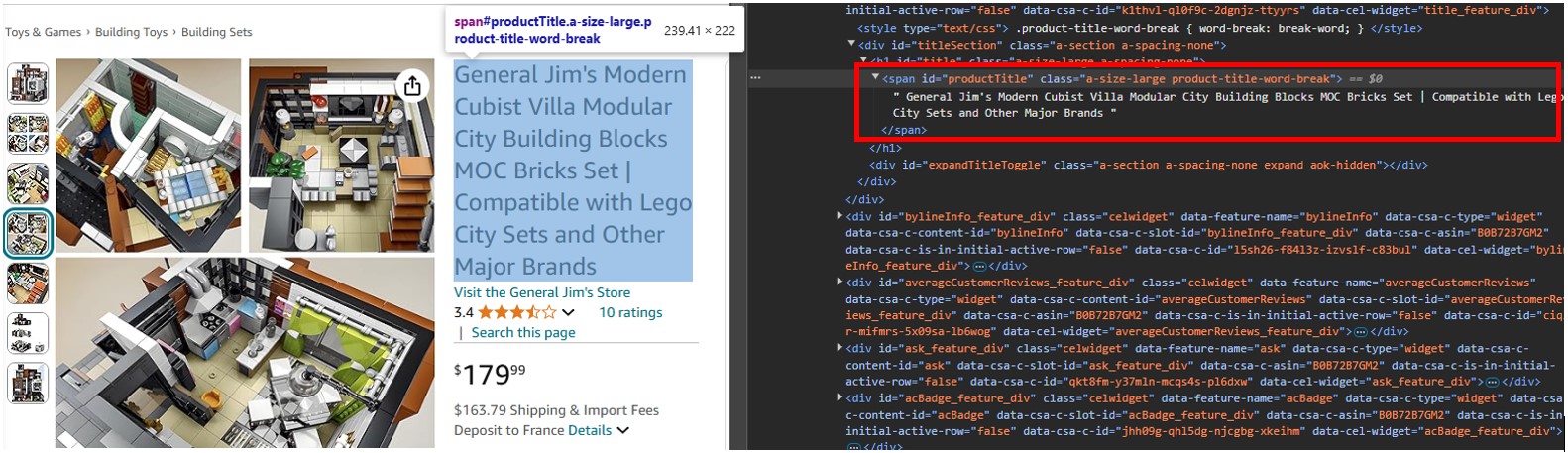
Você verá que é uma tag span com seu atributo id definido como "productTitle". Da mesma forma, se você clicar com o botão direito do mouse no elemento e selecionar Inspecionar, verá a marcação do conteúdo, que o raspador lerá e permitirá que você procure por detalhes específicos.
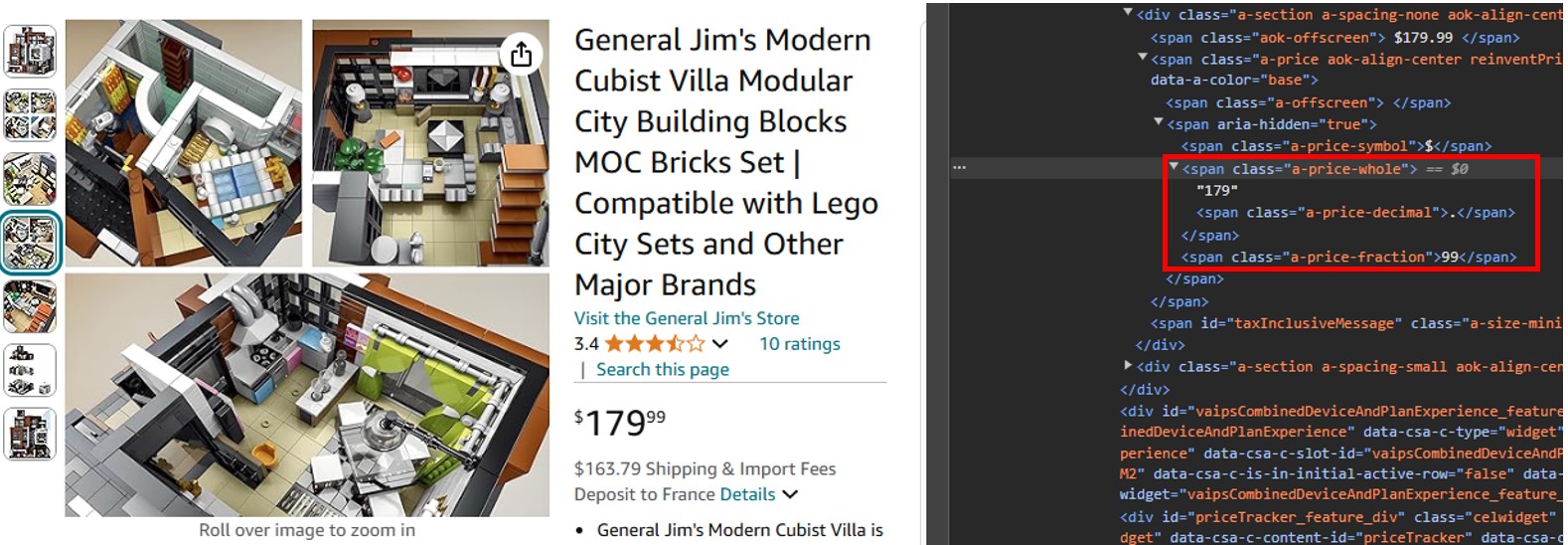
Você pode ver que o componente em dólar do preço está em uma tag span com a classe "a-price-whole", e o componente em centavos está em outra tag span com a classe definida como "a-price-fraction".
Da mesma forma, você pode localizar a classificação, a imagem e a descrição.
Uma vez que você tenha essas informações, podemos configurar nosso código com o BeautifulSoup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Encontrando o título
title_tag = soup.find('span', {'id': 'productTitle'})
product_title = title_tag.get_text(strip=True) if title_tag else 'Título não encontrado'
price_tag = soup.find('span', {'class': 'a-offscreen'})
product_price = price_tag.get_text(strip=True) if price_tag else 'Preço não encontrado'
print(f"Título: {product_title}")
print(f"Preço: {product_price}")
Neste exemplo, o BeautifulSoup é usado para analisar o conteúdo HTML e encontrar as tags que contêm o título e o preço do produto. O método get_text(strip=True) é usado para extrair o conteúdo de texto e remover qualquer espaço em branco no início ou no final.
Extraindo avaliações e classificações de clientes
Para extrair avaliações e classificações de clientes, você precisa encontrar as tags e classes HTML relevantes. Aqui está um exemplo:
# Encontrando avaliações de clientes
reviews = []
review_tags = soup.find_all('span', {'data-hook': 'review-body'})
for tag in review_tags:
review_text = tag.get_text(strip=True)
reviews.append(review_text)
# Encontrando classificações de clientes
ratings = []
rating_tags = soup.find_all('i', {'data-hook': 'review-star-rating'})
for tag in rating_tags:
rating_text = tag.get_text(strip=True)
ratings.append(rating_text)
print(f"Avaliações de Clientes: {reviews}")
print(f"Classificações de Clientes: {ratings}")
Neste código, find_all é usado para localizar todas as instâncias de corpos de avaliações e classificações. O conteúdo de texto de cada avaliação e classificação é extraído e armazenado em listas.
Combinando essas etapas, você pode construir um raspador básico da Amazon que busca detalhes do produto, avaliações e classificações de clientes. Lembre-se de lidar com erros e respeitar os termos de serviço da Amazon para evitar possíveis problemas legais.
Revisão do script final
Para raspar páginas de produtos da Amazon, usaremos a biblioteca requests do Python para buscar URLs e o BeautifulSoup para analisar o conteúdo HTML. Aqui está o script consolidado final que demonstra esses processos:
import requests
import random
from bs4 import BeautifulSoup
# Lista de user-agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 10; SM-G960F)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Mobile Safari/537.36'
]
# Escolha um user-agent aleatório
headers = {
'User-Agent': random.choice(user_agents)
}
# URL do produto de exemplo
url = 'https://www.amazon.com/dp/B0B72B7GM2'
# Faz uma solicitação GET para a URL especificada com os headers escolhidos
response = requests.get(url, headers=headers)
# Verifica se a solicitação foi bem-sucedida
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
# Encontrando o título
title_tag = soup.find('span', {'id': 'productTitle'})
product_title = title_tag.get_text(strip=True) if title_tag else 'Título não encontrado'
# Encontrando o preço
price_tag = soup.find('span', {'class': 'a-offscreen'})
product_price = price_tag.get_text(strip=True) if price_tag else 'Preço não encontrado'
# Encontrando avaliações de clientes
reviews = []
review_tags = soup.find_all('span', {'data-hook': 'review-body'})
for tag in review_tags:
review_text = tag.get_text(strip=True)
reviews.append(review_text)
# Encontrando classificações de clientes
ratings = []
rating_tags = soup.find_all('i', {'data-hook': 'review-star-rating'})
for tag in rating_tags:
rating_text = tag.get_text(strip=True)
ratings.append(rating_text)
print(f"Título: {product_title}")
print(f"Preço: {product_price}")
print(f"Avaliações de Clientes: {reviews}")
print(f"Classificações de Clientes: {ratings}")
else:
print(f"Falha ao recuperar a página da web. Código de status: {response.status_code}")

Neste capítulo, exploraremos técnicas avançadas para raspar a Amazon. Essas ferramentas poderosas, utilizando Python, especializam-se na recuperação de dados de URLs, economizando tempo e dinheiro, ao mesmo tempo em que tornam a raspagem de web acessível a todos.
Por que usar um software de raspagem de web?
A capacidade de raspar, coletar e analisar conteúdo da internet usando um raspador tornou-se uma habilidade crucial para empresas e pesquisadores. É aqui que o software de raspagem de web, especialmente com Python, fará uma diferença significativa na sua capacidade de buscar e recuperar informações relevantes.
Risco reduzido de detecção e bloqueio
Um dos desafios ao construir um raspador personalizado é o risco de ser detectado e bloqueado por sites. Os sites frequentemente têm medidas de segurança em vigor, como limitação de taxa ou bloqueio de IP, para evitar a raspagem. No entanto, usar um software especializado de raspagem de web com Python reduz significativamente o risco de detecção. Essas ferramentas são projetadas para lidar com mecanismos sofisticados anti-raspagem, como rotação de IP, imitando comportamento semelhante ao humano e gerenciando intervalos de solicitação para evitar acionar sistemas de segurança.
Acesso a grandes volumes de dados
A internet é um tesouro de informações, mas raspar sites manualmente pode ser demorado e impraticável. Um raspador usando Python automatiza esse processo, permitindo que os usuários raspem grandes volumes de conteúdo de forma rápida e eficiente. Seja para pesquisa de mercado, análise competitiva ou estudos acadêmicos, a raspagem de web reunirá informações que, de outra forma, levariam dias ou semanas para serem compiladas manualmente.
Escalabilidade
À medida que as empresas crescem, também cresce sua necessidade de raspar mais informações. Um raspador usando Python é altamente escalável, capaz de lidar com quantidades crescentes de conteúdo sem perda de desempenho. Essa escalabilidade torna a raspagem de web uma solução ideal para empresas de todos os tamanhos, desde startups até grandes corporações.
Por que usar a API Piloterr para raspagem da Amazon?
O raspador Piloterr se destaca como uma ferramenta poderosa para raspar dados de produtos da Amazon. Aqui estão várias razões pelas quais você deve considerar usar a solução Piloterr para suas necessidades de raspagem da Amazon:
- Proxy Privado: O Piloterr usa seus próprios proxies privados, garantindo que suas solicitações sejam distribuídas por vários endereços IP (rotação de IP). Isso reduzirá significativamente a probabilidade de ser bloqueado pela Amazon e permite que você raspe dados de forma eficiente e eficaz. Nossa infraestrutura robusta é construída com Python e projetada para lidar com grandes volumes de solicitações, mantendo uma alta taxa de sucesso.
- Acesso Abrangente à Biblioteca com uma Única Assinatura: Uma das razões mais convincentes para escolher o Piloterr é o valor oferecido pelo nosso modelo de assinatura. Com uma única assinatura, você terá acesso aos nossos endpoints da biblioteca e recursos de raspagem. Isso inclui não apenas o raspador da Amazon, mas também outras soluções de raspagem para vários sites e fontes de dados. Esse acesso inclusivo garante que você tenha as ferramentas necessárias para qualquer projeto de raspagem, tudo em um só lugar.
Com o Piloterr, você pode facilmente buscar, ler e recuperar as informações necessárias da Amazon e de outras plataformas, dando-lhe uma vantagem poderosa em seus esforços de coleta de dados.
Crie sua conta
- Registre-se em piloterr.com
- Crie sua assinatura (50 créditos gratuitos no registro)
- Crie e copie sua chave de API
Estudo de caso: raspar a Amazon
Aqui está um exemplo prático de como usar Python para raspar o título e outros detalhes relevantes de um item da Amazon a partir de sua URL. Um raspador será usado para recuperar as informações necessárias de forma eficiente.
Código básico em Python
Não se esqueça de substituir PILOTERR_API_KEY pela sua chave de API real. O script assume que as respostas da API Piloterr estão em um formato específico da nossa API, portanto, pode ser necessário ajustá-lo dependendo do provedor que você escolher.
- Copie o código
- Crie um novo arquivo
get_amazon_product.py - Substitua o token da API pelo seu próprio
- Substitua a variável
JOB_TITLE&LOCATIONpela sua necessidade - Execute o script com
python get_amazon_product.py
import requests
PILOTERR_API_KEY = 'YOUR-API-KEY-HERE'
LIST_ASIN_AMAZON_PRODUCT = [
"B0CN78FNTY",
"B09JGLMDLZ",
"B09VZ3ZQWQ",
"B0B72B7GM2"
]
def get_amazon_product_info(url: str):
amazon_api_url = "https://piloterr.com/api/v2/amazon/product"
headers = {
"x-api-key": PILOTERR_API_KEY
}
data = {
"query": url,
"domain": "com"
}
response = requests.get(
url=amazon_api_url,
headers=headers,
params=data # Usando params em vez de json para solicitação GET
)
if response.status_code == 200:
return response.json()
else:
print(f"Erro: Não foi possível realizar a busca. Código de status: {response.status_code}")
return None
def extract_product_data(json_data):
product_data = {
"url": json_data.get("url"),
"asin": json_data.get("asin"),
"price": json_data.get("price"),
"stock": json_data.get("stock"),
"title": json_data.get("title")
}
return product_data
def process_amazon_products(url_list):
all_product_data = []
for url in url_list:
product_info = get_amazon_product_info(url)
if product_info:
extracted_data = extract_product_data(product_info)
all_product_data.append(extracted_data)
return all_product_data
# Uso
if __name__ == "__main__":
products_data = process_amazon_products(LIST_ASIN_AMAZON_PRODUCT)
print(products_data)
Explicação em Python
- Imports: O código importa a biblioteca
requestspara fazer solicitações HTTP. - Chave da API e Lista de Produtos: Define uma constante
PILOTERR_API_KEYpara autenticação da API e uma listaLIST_ASIN_AMAZON_PRODUCTcontendo ASINs (Amazon Standard Identification Numbers) dos produtos a serem consultados. - Função
get_amazon_product_info(url: str):- Constrói uma solicitação para a API Piloterr para recuperar informações do produto.
- Define os cabeçalhos da solicitação com a chave da API e parâmetros para a busca do produto.
- Se o código de status da resposta for 200 (OK), retorna os dados JSON; caso contrário, imprime uma mensagem de erro.
- Função
extract_product_data(json_data):- Extrai campos específicos (
url,asin,price,stocketitle) dos dados JSON retornados pela API e os retorna em um dicionário.
- Extrai campos específicos (
- Função
process_amazon_products(url_list):- Itera sobre uma lista de URLs de produtos (ASINs), recupera informações do produto usando
get_amazon_product_infoe extrai dados relevantes usandoextract_product_data. - Compila todos os dados extraídos dos produtos em uma lista e a retorna.
- Itera sobre uma lista de URLs de produtos (ASINs), recupera informações do produto usando
Outros casos de uso
- Recuperar Artigos Mais Vendidos: Use a API para coletar dados sobre os produtos mais vendidos em uma categoria específica ou no geral. Isso pode ajudar a identificar itens em alta com base no desempenho de vendas.
- Analisar Estrelas: Raspe informações do produto, incluindo classificações por estrelas. Isso permite que os usuários filtrem produtos com base na satisfação do cliente e encontrem itens altamente avaliados.
- Extrair Imagens de Produtos: Recupere imagens de alta qualidade dos artigos para uso em sites de comércio eletrônico ou plataformas de comparação. Isso melhora o apelo visual das listagens e ajuda os clientes a tomar decisões informadas.
- Criar um Agregador de Avaliações: Compile avaliações e classificações de clientes para os melhores artigos em um nicho específico. Isso pode ajudar os consumidores a tomar decisões com base em feedbacks abrangentes de outros compradores.
Precauções para raspagem na Amazon
Ao raspar a Amazon, é crucial lembrar que os seletores CSS (elem.css()) podem mudar ao longo do tempo, já que os desenvolvedores da Amazon atualizam frequentemente o CSS do site. Essas atualizações podem alterar a estrutura, fazendo com que seus seletores CSS existentes falhem. Para reduzir a manutenção, escolha cuidadosamente os seletores para o seu elemento (elem), priorizando elementos <div> com atributos estáveis, como id. Ao direcionar elementos com atributos id específicos, você melhora a resiliência do seu script de raspagem contra mudanças no CSS.
Conclusão
O Piloterr é uma das melhores maneiras de raspar itens da Amazon de forma simples e eficiente usando nosso raspador em Python. Ao integrar essa solução ao seu fluxo de trabalho, você otimizará seu processo, eliminando a necessidade de gerenciar agentes ou endereços IP, já que tudo passa pelos nossos proxies. Seja raspando dados de URLs para análise de mercado, pesquisa de concorrentes ou outros fins, o Piloterr permitirá que você busque, leia e recupere facilmente as informações de que precisa. É uma ferramenta valiosa para adicionar ao seu kit de ferramentas de raspagem de web.