Todos buscam desenvolver e utilizar novas tecnologias na intensa competição dos dias atuais. O ato de baixar automaticamente dados de sites para o seu computador ou banco de dados é conhecido como web scraping. O web scraping é frequentemente referido como extração de dados ou extração de dados da web. O web scraping é uma técnica automatizada para coletar grandes quantidades de dados de sites. A maioria dessas informações está em formato HTML não estruturado e é transformada em informações estruturadas em um banco de dados ou planilha para que possa ser utilizada em várias funções. O web scraping pode ser realizado usando várias técnicas para coletar dados de sites. Estas incluem o uso de APIs específicas, serviços online ou até mesmo escrever seu próprio código do zero para web scraping. Você pode acessar os dados estruturados em muitos grandes sites, como Google, Twitter, Facebook, StackOverflow e outros, usando suas APIs. Embora esta seja a melhor opção, existem outros sites que ou não têm o mesmo nível de complexidade tecnológica ou não permitem que os usuários acessem grandes quantidades de dados estruturados. É melhor empregar web scraping, nesse caso, para coletar dados do site.
As duas ferramentas necessárias para o web scraping são o scraper e o crawler. O crawler é um sistema de inteligência artificial que clica em links para pesquisar na internet as informações necessárias. Em contraste, um scraper é uma ferramenta especial projetada para extrair dados do site. De acordo com a escala e complexidade do projeto, a arquitetura do scraper pode variar muito para recuperar os dados de forma eficiente e precisa.
Usos do Web Scraping
Os usos mais populares do web scraping são os seguintes:
- Geração de Leads para Marketing : Para fins de marketing, leads podem ser gerados usando uma ferramenta de web scraping. Ao raspar as informações de sites relevantes, listas de e-mails e telefones para contato frio podem ser criadas. Por exemplo, dados de sites que oferecem listas de páginas amarelas ou de listagens comerciais do Google Maps podem ser usados para extrair o número de telefone e o endereço de e-mail de uma empresa.
- Avaliação de Preços e Observação da Concorrência : Empresas que oferecem produtos ou serviços devem ter informações detalhadas sobre os produtos e serviços concorrentes que estão sempre sendo introduzidos no mercado. Esses dados podem ser monitorados regularmente usando uma ferramenta de web scraping.
- E-Commerce : A extração frequente de dados de produtos de diferentes sites de e-commerce como Amazon, eBay, Google Shopping, etc., é possível com a ajuda do web scraping. Uma ferramenta de web scraping facilita a recuperação de detalhes do produto, incluindo preço, descrição, fotos, avaliações e classificações.
- Imóveis : Uma ferramenta de web scraping pode ser usada para recuperar os detalhes da propriedade publicados em sites imobiliários como Zillow, Realtor e outros. O web scraping pode ser usado para coletar informações de contato de proprietários e agentes além dos dados da propriedade.
- Análise de Dados : A pessoa comum pode querer coletar e analisar informações sobre uma categoria específica de outros sites. Essa categoria inclui itens como imóveis, veículos, gadgets, contatos comerciais, além de marketing. Os vários sites que se enquadram na categoria fornecida apresentam informações de várias maneiras. Você pode não ser capaz de visualizar todas as informações de uma vez, mesmo usando um único site. As informações podem ser divididas entre várias páginas (muito parecido com as listas paginadas ou paginadas encontradas nos resultados de pesquisa do Google) e organizadas em diferentes seções.
- Avaliação Acadêmica : Qualquer pesquisa, seja acadêmica, de marketing ou científica, deve ter dados. Você pode facilmente coletar dados estruturados de várias fontes na Internet com a ajuda de um web scraper.
- Dados para Projetos de Treinamento e Teste de Machine Learning : Com o uso do web scraping, você pode coletar dados para teste e treinamento de modelos de machine learning. A precisão dos dados de treinamento que você usa determina o quão bem seus modelos de machine learning funcionam. Se os dados de treinamento não estiverem facilmente disponíveis, você pode usar o web scraping para coletá-los de várias fontes.
- Análise de Odds de Apostas Esportivas : Várias casas de apostas empregam web scraping para coletar valores de odds de apostas de sites de apostas esportivas como OddsPortal, BetExplorer, FlashScore, etc.
- Avaliação Sentimental : A análise de sentimento é essencial se as empresas desejam compreender como os clientes se sentem sobre seus produtos em geral. O web scraping é um método que as empresas usam para adquirir dados de sites de mídia social como Facebook e Twitter sobre as percepções gerais que as pessoas têm de seus produtos. Como resultado, elas poderão superar seus concorrentes e criar produtos que as pessoas desejarão.
Como Funcionam os Web Scrapers?
Os web scrapers são capazes de coletar todas as informações de determinados sites ou as informações específicas que um usuário solicita. Para garantir que apenas os dados necessários sejam rapidamente extraídos pelo web scraper, essa é a situação ideal. Por exemplo, você pode querer raspar um site da Amazon para descobrir quais tipos de espremedores de frutas são oferecidos, mas pode precisar apenas de informações sobre os modelos dos diferentes espremedores e não dos comentários dos clientes.
Portanto, as URLs são fornecidas primeiro quando um web scraper precisa raspar um site. Em seguida, todo o código HTML dos sites é carregado. Um scraper mais sofisticado também pode extrair todas as partes de CSS e Javascript. Após extrair os dados necessários do código HTML, o scraper os apresenta no formato que o usuário escolheu. Na maioria das vezes, isso assume a forma de uma planilha do Excel ou um arquivo CSV, mas as informações também podem ser salvas em outros formatos, como um arquivo JSON.
Qual é o Processo de Web Scraping Manual?
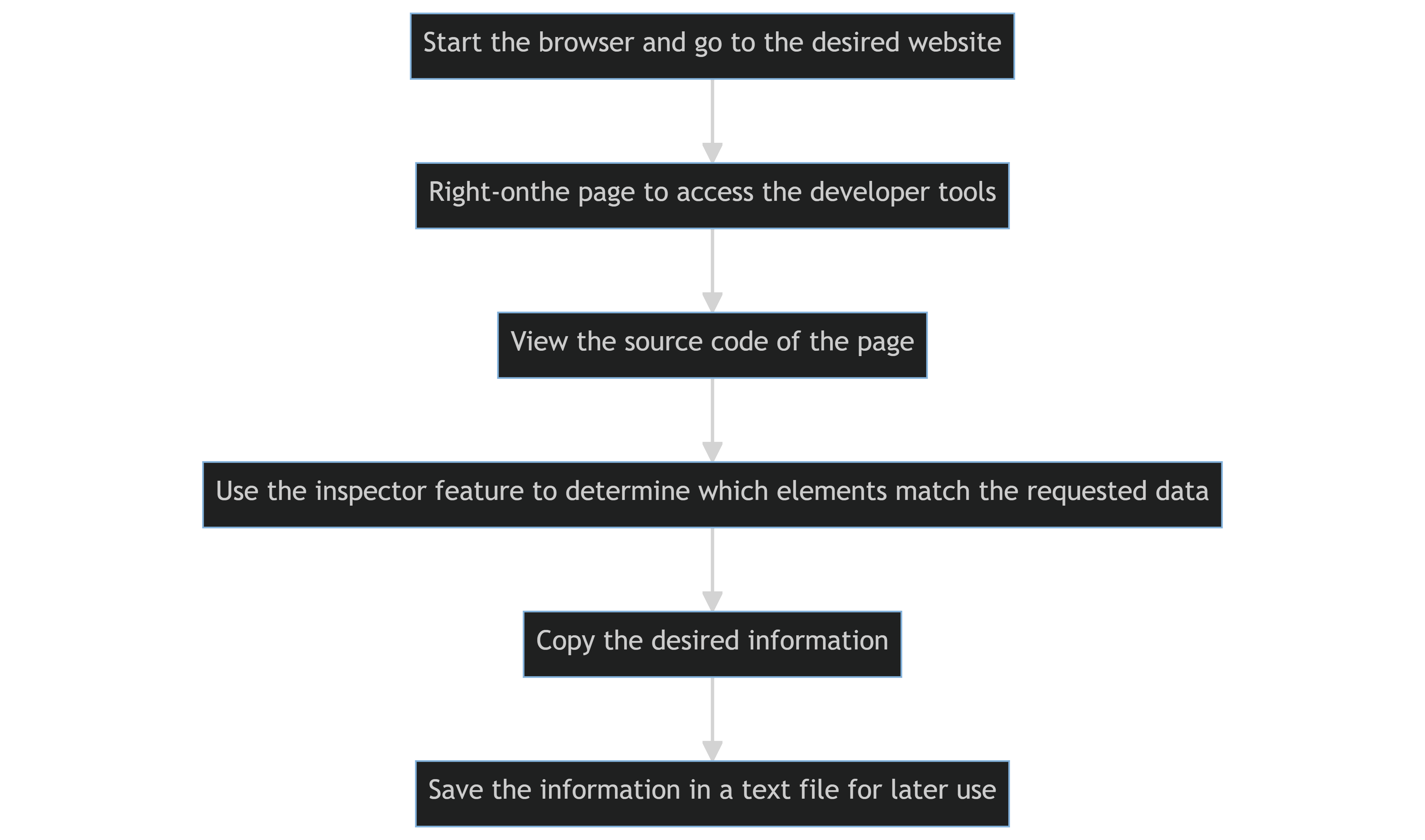
O código-fonte de uma página da web é visualizado e extraído manualmente utilizando as ferramentas de desenvolvedor de um navegador da web.
As etapas fundamentais são as seguintes:
- Abra o navegador e acesse o site desejado.
- Para acessar as ferramentas de desenvolvedor no navegador, clique com o botão direito na página.
- Veja o código-fonte da página.
- Para determinar quais elementos em uma página da web correspondem aos dados solicitados, use o recurso de inspetor do seu navegador.
- Copie as informações desejadas.
- Copie as informações e salve-as em um arquivo de texto para uso posterior.
Qual é o Processo de Web Scraping Automatizado?
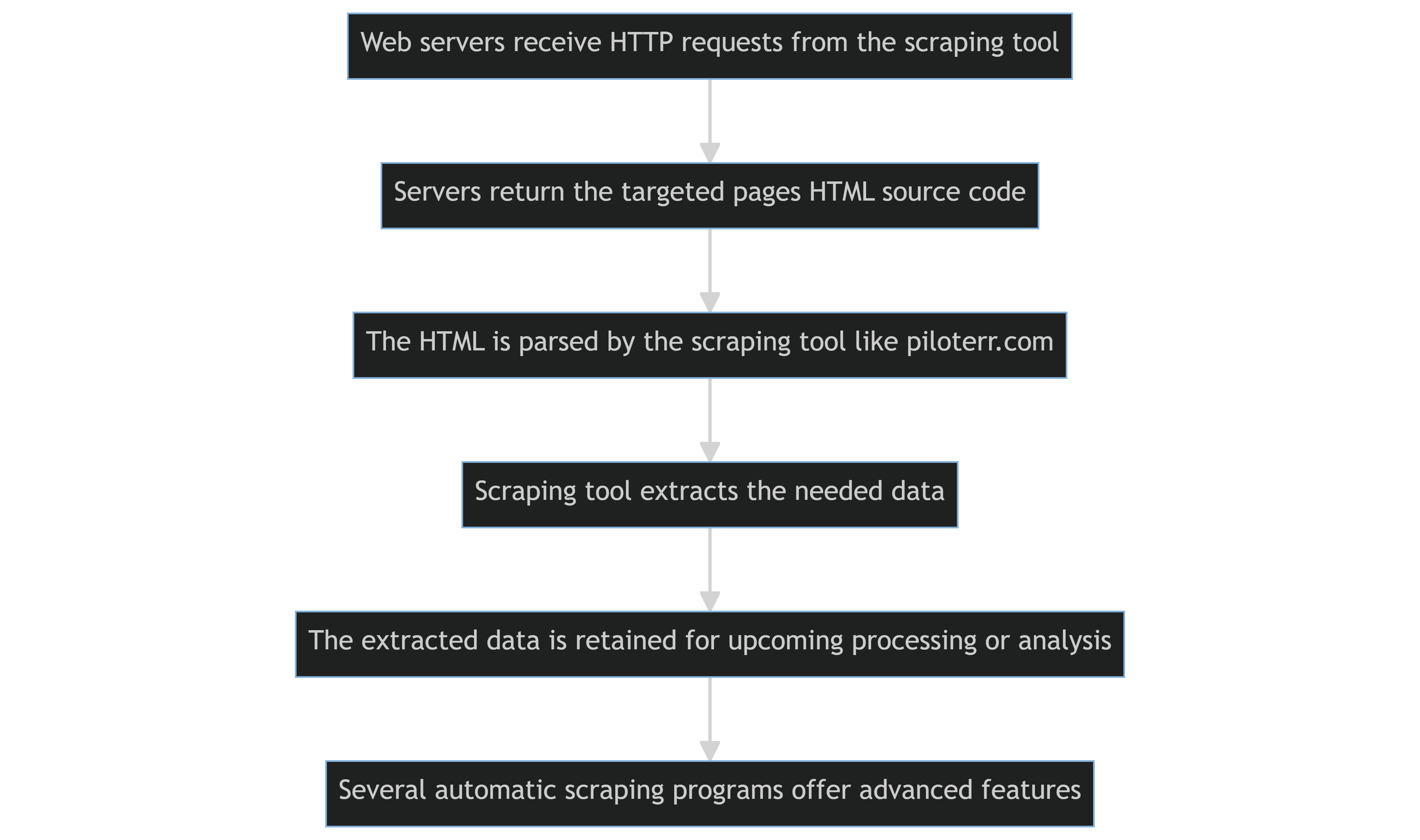
Usar ferramentas de scraping, como scripts Python ou bibliotecas Scrapy, para extrair conteúdo de vários sites é conhecido como web scraping automatizado.
As etapas fundamentais são as seguintes:
- Os servidores web que hospedam os sites alvo recebem solicitações HTTP da ferramenta de scraping programaticamente.
- Os servidores retornam o código-fonte HTML das páginas alvo.
- O HTML é analisado pela ferramenta de scraping, que então extrai os dados necessários.
- Os dados extraídos são retidos para processamento ou análise futura.
- Vários programas de web scraping automático podem oferecer funcionalidades mais avançadas, como a capacidade de gerenciar cookies ou contornar os Termos de Uso de um site que proíbem ou restringem o scraping de conteúdo.
Tipos de Web Scraping
Muitos tipos distintos podem ser usados para categorizar web scrapers, incluindo auto-construídos ou pré-construídos, software ou plugin de navegador, em nuvem ou local.
Web Scraping Auto-Construído : Web scrapers auto-construídos são possíveis, mas exigem um alto nível de conhecimento em programação. Além disso, você precisa de ainda mais compreensão se quiser que seu web scraper tenha mais funcionalidades. Web scrapers pré-construídos, por outro lado, são scrapers que já foram criados e são fáceis de baixar e usar. Você pode personalizar esses e adicionar opções mais avançadas também.
Web Scrapers de Extensões de Navegador : Extensões para o seu navegador estão disponíveis, incluindo web scrapers. Como são incorporados ao seu navegador, são fáceis de usar, mas isso também significa que têm algumas limitações. Web scrapers que funcionam em extensões de navegador não podem usar quaisquer funções complexas que estejam além das capacidades do seu navegador. No entanto, como os web scrapers de software podem ser baixados e instalados no seu computador, eles não são limitados dessa forma. Embora esses sejam mais avançados do que os web scrapers de navegador, eles também contêm funções avançadas que não são limitadas pelas capacidades do seu navegador.
Web scrapers em nuvem : O servidor externo que a empresa da qual você compra o scraper geralmente fornece a nuvem, onde os web scrapers em nuvem são executados, é chamada de nuvem. Como eles não envolvem a raspagem de dados de sites, o seu computador pode se concentrar em outras tarefas. Por outro lado, os web scrapers locais utilizam os recursos locais do seu computador para funcionar. Portanto, se os web scrapers precisarem de mais CPU ou RAM, o seu computador ficará mais lento e incapaz de lidar com outras operações.
O Web Scraping é Legal?
O web scraping é geralmente aceitável desde que seja realizado para fins razoáveis e não contrarie as leis de direitos autorais, acordos de licença ou os termos e condições de um site.
A moralidade do web scraping depende principalmente do seu uso pretendido, dos dados sendo acessados, dos Termos de Uso do site e das leis de privacidade do estado-nação onde está sendo realizado.
O Web Scraping Não é Necessariamente Desafiador
Várias ferramentas gerais de web scraping têm a desvantagem de serem bastante difíceis de aprender e operar. Isso envolve uma curva de aprendizado significativa. Para resolver esse problema, o WebHarvy foi criado. A interface extremamente simples de apontar e clicar do WebHarvy permite que você comece a raspar dados de qualquer site em apenas alguns minutos.
Que Tipo de Ferramentas Podem Ser Utilizadas para Web Scraping?
Habilidades de programação são necessárias para o web scraping, com Python sendo a linguagem mais comum usada para essa tarefa. Felizmente, o Python vem com uma tonelada de módulos de código aberto que simplificam muito o web scraping. Alguns deles são os seguintes:
Outro pacote Python que é frequentemente usado para extrair dados de textos XML e HTML é chamado BeautifulSoup. Grandes quantidades de dados são significativamente mais fáceis de navegar e pesquisar graças à organização desse material processado em árvores mais amigáveis pelo BeautifulSoup. É frequentemente a ferramenta preferida do analista de dados.
Um framework de aplicação baseado em Python chamado Scrapy rastreia a web e extrai dados estruturados dela. É frequentemente empregado para processamento de informações, mineração de dados e a preservação de conteúdo histórico. Ele pode ser usado como um rastreador web de propósito geral ou para extrair dados através de APIs, além de web scraping, para o qual foi especialmente criado.
Pandas
Outra biblioteca Python de propósito geral para manipulação e indexação de dados é chamada Pandas. Ela pode ser usada em conjunto com o BeautifulSoup para raspar a web. A principal vantagem de usar pandas é que os analistas não precisam mudar para outras linguagens, como R, para completar o processo de análise de dados.
Outras ferramentas estão prontamente disponíveis, variando desde aquelas usadas para scraping de propósito geral até aquelas criadas para tarefas mais complexas e especializadas. A melhor ação é investigar quais tecnologias melhor se adaptam aos seus interesses e nível de habilidade antes de incorporá-las à sua caixa de ferramentas de análise de dados.
Que Passos Posso Tomar Para Impedir que o Conteúdo do Meu Site Seja Raspado?
O fato de que o scraping de conteúdo de sites é tão frequentemente utilizado para objetivos aceitáveis, como otimização para motores de busca (SEO), torna uma tarefa difícil impedir. Os editores podem empregar as seguintes técnicas para reduzir a chance de que seu conteúdo seja ilegal ou não autorizado raspado:
- Arquivos robots.txt : Rastreadores e scrapers da web podem ler arquivos robots.txt para descobrir quais sites são apropriados para acesso e scraping.
- CAPTCHAs : Ao estabelecer testes que são simples para humanos completarem, mas desafiadores para programas de computador, os CAPTCHAs podem impedir ferramentas de scraper indesejadas.
- Limites de solicitação : Use regras chamadas "limites de solicitação" para restringir a frequência com que um site pode receber solicitações HTTP de scrapers.
- Ofuscação de código : Use técnicas como minificação (O termo "minificação" refere-se ao processo de modificar código para eliminar caracteres e partes desnecessárias), renomeação de variáveis e funções, ou codificação para transformar JavaScript em código difícil de ler e entender.
- Bloqueio de IP : Monitore registros do servidor para atividades de scraper e bloqueie endereços IP de scrapers suspeitos.
- Ação Legal : Tome medidas legais para impedir scraping não autorizado, apresentando uma reclamação à empresa de hospedagem ou solicitando uma ordem judicial.
Métodos para Raspar Dados de Sites
Estabeleça as URLs Alvo : Faça uma lista das URLs alvo (ou seja, as páginas da web das quais você extrairá dados) depois de determinar de qual site deseja raspar dados. Lembre-se de revisar as páginas da web para encontrar os dados específicos que deseja raspar.
Acesse o Site Enviando uma Solicitação HTTP : Você pode organizar solicitações e respostas pela internet usando o protocolo da camada de aplicação HTTP. Os dados devem ser transferidos de um local para outro pela rede usando o mecanismo servidor-cliente do HTTP. Seu computador ou smartphone pode funcionar como o cliente, enquanto o host da web é o servidor, pronto para fornecer os dados mediante uma solicitação bem-sucedida. Quando o cliente solicita dados do servidor, o servidor requer uma resposta GET. Esteja ciente de que os métodos usados por diferentes programas e linguagens de computador para enviar solicitações HTTP variam. O servidor fornece os dados em resposta à solicitação HTTP, permitindo que você visualize a página HTML ou XML.
Baixe o Conteúdo da Página das URLs Alvo (Download de Dados) : Você pode baixar uma página da web e visualizar seu conteúdo na tela usando a busca de dados.
Remova Informações da Página (Análise de Dados) : Após extrair dados das URLs alvo, você deve analisá-los para torná-los mais fáceis de entender e adequados para análise de dados. Como é difícil entender dados HTML simples, a análise de dados é necessária. Os dados devem primeiro ser exibidos em um formato compreensível para o analista de dados. Isso pode envolver a produção de relatórios a partir de strings HTML ou a criação de tabelas de dados que exibam dados apropriados.
Formate os dados extraídos : Os dados analisados podem então ser exportados para uma planilha do Excel, Google Sheets ou CSV. Você pode utilizar APIs porque muitas soluções automatizadas de web scraping aceitam formatos como JSON.
Prevenção de Web Crawling
Algumas precauções de segurança padrão não são mais eficazes devido à inteligência dos bots de scraper maliciosos. Por exemplo, bots de navegador headless podem se passar por humanos para evitar a detecção pela maioria das técnicas de mitigação. A Imperva emprega uma análise detalhada de tráfego para frustrar os avanços feitos por operadores de bots maliciosos. Ela garante que tanto o tráfego humano quanto o automatizado para o seu site sejam totalmente válidos.
Vários critérios são verificados durante o processo, incluindo:
- Impressão digital TLS: Uma análise detalhada dos cabeçalhos HTML serve como o primeiro passo no processo de filtragem. Estes podem oferecer pistas sobre se um visitante é malicioso ou seguro, humano ou bot. Um banco de dados com mais de 10 milhões de variantes conhecidas, que é atualizado frequentemente, é usado para comparar assinaturas de cabeçalhos.
- Reputação do IP: Reúna informações de IP de todos os ataques aos nossos clientes. Visitas de endereços IP que têm histórico de uso em ataques são vistas com suspeita e têm maior probabilidade de passar por uma inspeção mais detalhada.
- Análise de comportamento: Monitorar como os usuários interagem com um site pode revelar padrões de comportamento incomuns, como taxas de solicitação suspeitamente altas e hábitos de navegação irracionais. Isso facilita a identificação de visitantes que são, na verdade, bots.
- Desafios progressivos: Desafios progressivos são usados para filtrar bots e reduzir falsos positivos. Esses desafios incluem suporte a cookies e execução de JavaScript. Um CAPTCHA pode, como último recurso, eliminar bots que estão tentando se passar por humanos.
Exemplos de Web Scraping
Quando dados são retirados de sites sem o consentimento dos proprietários, a prática é conhecida como web scraping, que é prejudicial. Scraping de preços e roubo de conteúdo são os dois cenários de uso mais comuns.
Scraping de preços: Para escanear conjuntos de dados de negócios concorrentes, um perpetrador de scraping de preços geralmente lança bots de scraper a partir de uma botnet. O objetivo é obter acesso a dados de preços, subcotar concorrentes e aumentar as vendas. Ataques geralmente acontecem em setores onde os produtos são facilmente comparáveis e os preços influenciam muito as compras. Provedores de viagens, vendedores de ingressos e vendedores online de eletrônicos podem todos ser vítimas de scraping de preços.
Scraping de conteúdo : O roubo de conteúdo em larga escala de um site específico é referido como scraping de conteúdo. Diretórios de produtos online e sites que dependem de conteúdo digital para gerar tráfego são alvos comuns. Um ataque de scraping de conteúdo pode ser fatal para esses negócios.
O Que Torna o Python Uma Linguagem de Programação Tão Valiosa Para Web Scraping?
Hoje em dia, o Python parece estar na moda! Por ser capaz de lidar prontamente com a maioria das tarefas, é a linguagem mais usada para web scraping. Além disso, ele oferece uma série de bibliotecas projetadas especificamente para web scraping. O Scrapy, baseado em Python, é um framework de web crawling de código aberto bastante conhecido. É perfeito tanto para extração de dados baseada em API quanto para web scraping. Outro módulo Python excelente para web scraping é chamado Beautiful Soup. Para extrair dados de HTML em um site, ele produz uma árvore de análise. Essas árvores de análise podem ser navegadas, pesquisadas e modificadas usando várias capacidades no Beautiful Soup.