Everyone seeks to develop and use new technology in the intense competition of nowadays. The act of automatically downloading data from websites to your computer or database is known as web scraping. Web scraping is often referred to as data scraping or web data extraction. Web scraping is a computerized technique for gathering enormous amounts of data from websites. Most of this information is unstructured in HTML format and is changed into structured information in a database or spreadsheet so that it may be utilized in many functions. Web scraping can be carried out using a number of techniques to gather data from websites. These include leveraging specific APIs, online services, or even writing your own code from scratch for web scraping. You may access the structured data on many huge websites, including Google, Twitter, Facebook, StackOverflow, and others, using their APIs. Although this is the best selection, there are other websites that either don't have the same level of technological complexity or don't let customers access large amounts of structured data. It's better to employ web scraping, in that case, to gather data from the website.
The two tools required for web scraping are the scraper and the crawler. The crawler is an artificially intelligent system that clicks on links to search the internet for the necessary information. In contrast, a scraper is a special tool designed to extract data from the website. According to the scale and complexity of the project, the scrapers architecture may vary greatly in order to efficiently and precisely retrieve the data.
Uses of Web Scraping
The uses of web scraping that are most popular are as follows:
- Generating Leads for Marketing : For marketing purposes, leads can be generated using a web scraping tool. By scraping the information from pertinent websites, email and phone lists for cold outreach can be created. As an example, data from websites that offer yellow pages listings or from Google Maps business listings can be used to extract a companies phone number and email address.
- Price Evaluation and Competition Observation : Companies that offer goods or services must have thorough information about the rival goods and services that are always being introduced to the market. This data can be regularly monitored using a web scraping tool.
- E-Commerce : Frequently extracting product data from different e-commerce websites like Amazon, eBay, Google Shopping, etc. is possible with the help of web scraping. A web scraping tool makes it simple to retrieve product details including pricing, description, photos, reviews, and ratings.
- Real estate : A web scraping tool can be used to retrieve the property details published on real estate websites like Zillow, Realtor, and others. Web scraping can be used to collect owner and agent contact information besides property data.
- Analyzing Data : The average person could want to gather and examine information about a certain category from other websites. This category includes items like real estate, vehicles, gadgets, business contacts, along with marketing. The various websites that fall under the given category present information in a variety of ways. You might not be able to view all the info at once even using a single website. The information may be divided among several pages (much like the paginated or paginated lists found in Google search results) and organized into different sections.
- Academic Evaluation : Any research, whether it be academic, marketing, or scientific, must have data. You may easily collect structured data from numerous sources on the Internet with the aid of a web scraper.
- Data for Machine Learning Projects Training and Testing : With the use of web scraping, you can collect data for machine learning model testing and training. The accuracy of the training data you use determines how well your machine-learning models perform. If the training data is not easily available, you can utilize web scraping to gather it from multiple sources.
- Analysis of Sports Betting Odds : Various bookies employ web scraping to gather betting odds values from sports betting websites like OddsPortal, BetExplorer, FlashScore, etc.
- Sentimental Evaluation : Sentiment analysis is essential if businesses wish to comprehend how customers feel about their products in general. Web scraping is a method that companies use to acquire data from social media sites like Facebook and Twitter about the general perceptions people have of their products. As a result, they will be able to surpass their competitors and create products that people will want.
How Do Web Scrapers Work?
Web scrapers are capable of gathering all the information from certain websites or the specific information a user requests. To ensure that only the data you require is swiftly extracted by the web scraper, this is the ideal situation. As an example, you might want to scrape an Amazon website to find out what kinds of juicers are offered, but you could only require information on the models of the various juicers and not the feedback from customers.
Therefore, the URLs are first provided when a web scraper needs to scrape a website. Subsequently, all of the websites' HTML code is loaded. A more sophisticated scraper might also extract all of the CSS and Javascript parts. After extracting the necessary data from the HTML code, the scraper outputs it in the manner that the user has chosen. Most often, this takes the form of an Excel spreadsheet or a CSV file, although the information can also be saved in other formats, like a JSON file.
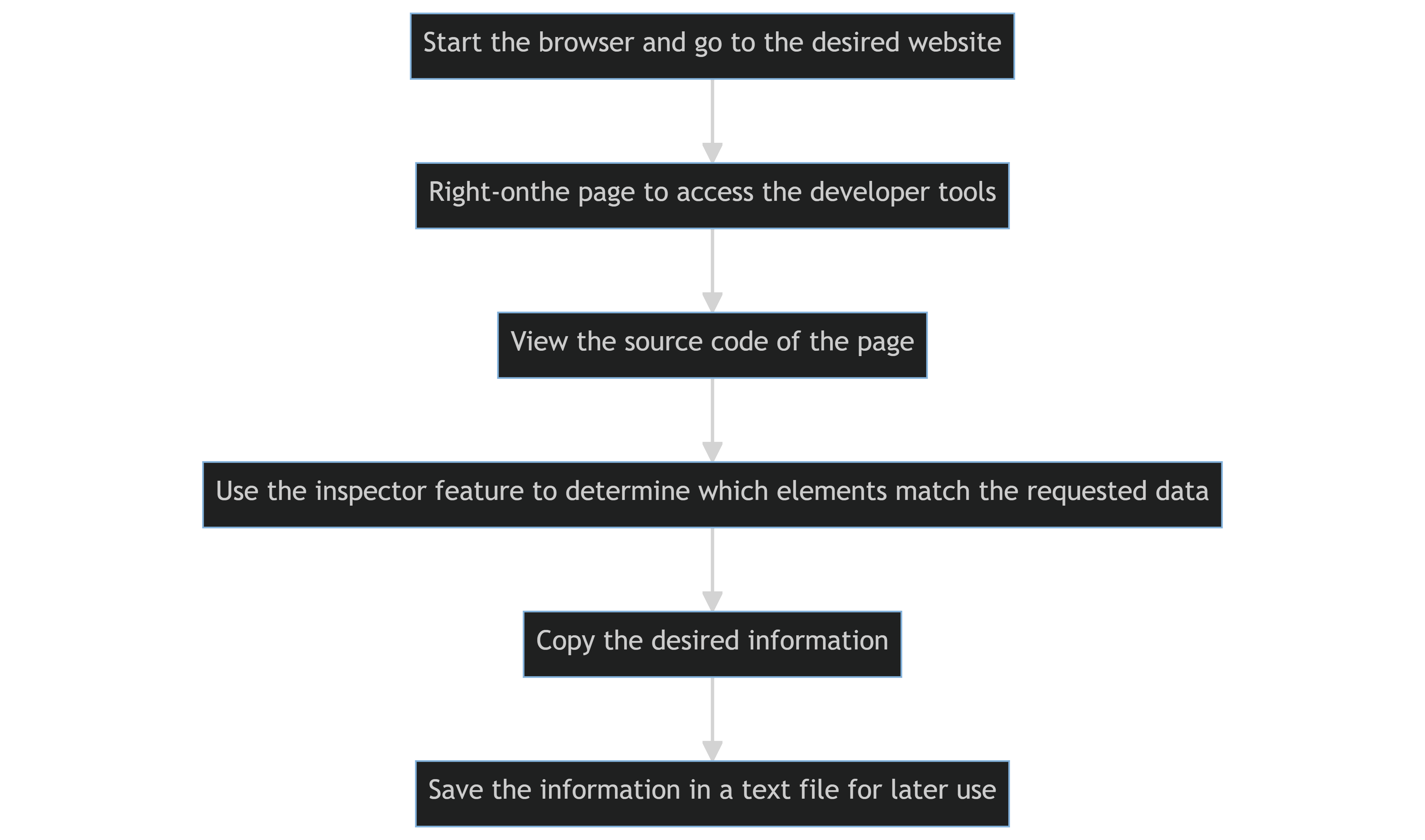
What Is The Process Of Manual Web Scraping?
The source code of a web page is viewed and extracted manually by utilizing the developer tools of a web browser.
The fundamental steps are as follows:
- Start the browser and go to the desired website.
- To access the developer tools in the browser, right-click on the page.
- View the source code of the page.
- To determine which elements on a web page match to the requested data, use the inspector feature of your browser.
- Copy the desired information.
- Copy the information, then save it in a text file for later use.
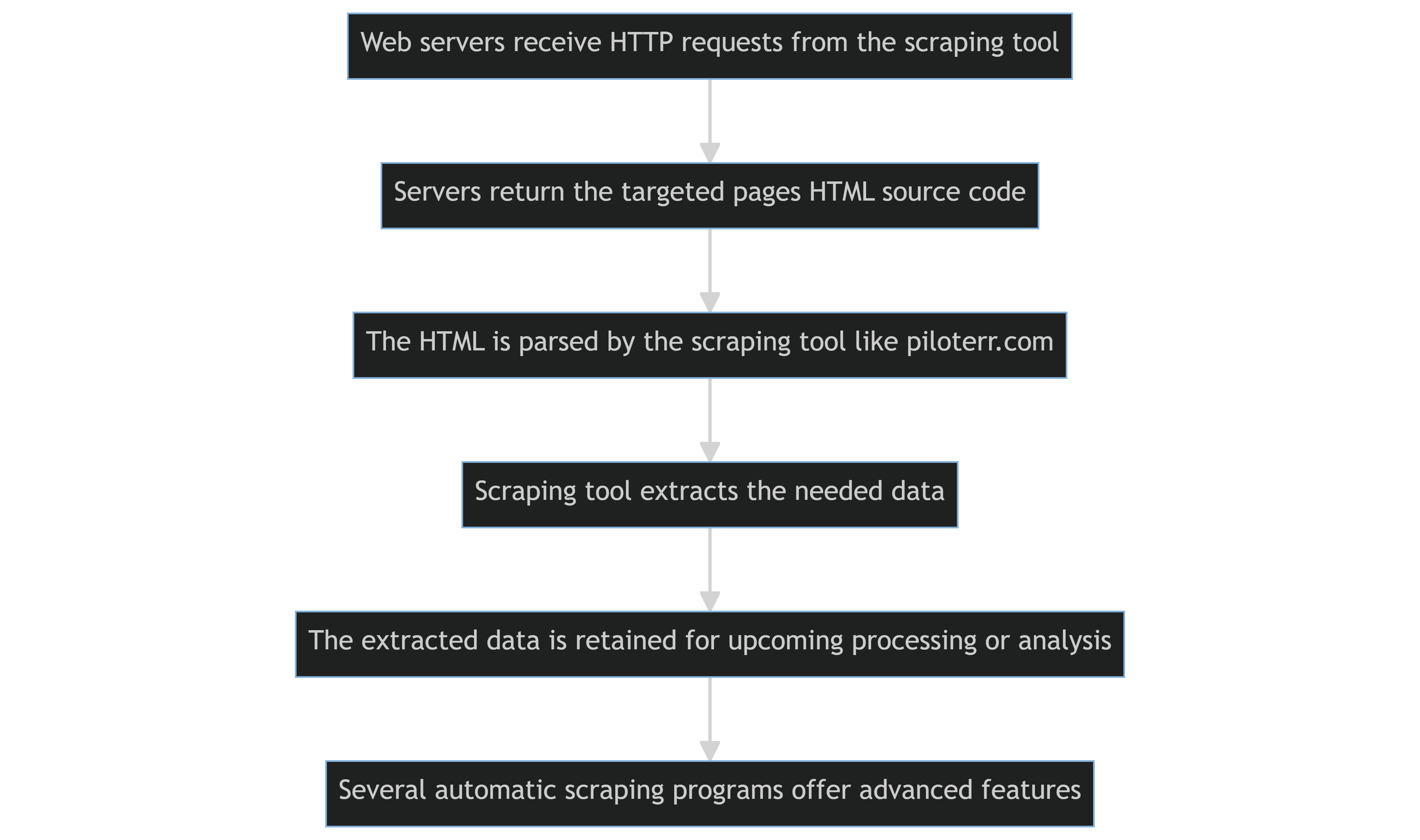
What Is The Process Of Automated Web Scraping?
Using scraping technologies, such as Python scripts or Scrapy libraries, to extract content from numerous websites is known as automated web scraping.
The fundamental steps are as follows:
- The web servers hosting the targeted websites receive HTTP requests from the scraping tool programmatically.
- The servers return the targeted pages HTML source code.
- The HTML is parsed by the scraping tool, which then extracts the needed data.
- The extracted data is retained for upcoming processing or analysis.
- Several automatic online scraping programs can offer more sophisticated functionality, like the capacity to manage cookies or circumvent a website's Terms of Use that forbids or restricts content scraping.
Types of Web Scraping
Many distinct types can be used to categorize web scrapers, including self-built or pre-built, software or browser plugin, cloud, or local.
Self-Build Web Scraping : Self-built web scrapers are possible, but they demand a high level of programming expertise. Additionally, you need even more understanding if you want your web scraper to have more functionality. Pre-built Web scrapers, on the other hand, are scrapers that have already been made and are simple to download and use. You may customize these and add more sophisticated options as well.
Browser Extensions Web Scrapers : Extensions for your browser are available, including web scrapers. As they are built into your browser, they are simple to use, but this also means that they have some limitations. Web scrapers that run on browser extensions are unable to use any complex functions that are beyond the capabilities of your browser. However, since software web scrapers may be downloaded and set up on your machine, they are not constrained in this way. Although these are more sophisticated than browser web scrapers, they also contain innovative functions that are not constrained by the capabilities of your browser.
Cloud web scrapers : The off-site server that the organization from which you purchase the scraper typically provides the cloud, where cloud web scrapers are run, is called a cloud. Since they don't involve scraping data from websites, your computer may concentrate on other activities. On the other hand, local web scrapers utilize your computer's local resources to operate. Therefore, if the Web scrapers need more CPU or RAM, your computer will slow down and become incapable of handling other operations.
Web Scraping Is Legal?
Web scraping is generally acceptable as long as it is carried out for reasonable purposes and doesn't contravene copyright regulations, license agreements, or the terms and conditions of a website.
Web scraping's morality mainly depends on its intended use, the data being accessed, the site's Terms of Use, and the privacy laws in the nation-state where it is being done.
Web Scraping Is Not Necessarily Challenging
Several general web scraping programs have the drawback of being quite challenging to learn and operate. It involves a significant learning curve. In order to address this issue, WebHarvy was created. WebHarvy's extremely simple point-and-click interface enables you to start scraping data from any website in only a few minutes.
What Kind Of Tools Can Be Utilized For Web Scraping?
Programming skills are necessary for web scraping, with Python being the most common language used for the job. Fortunately, Python comes with a tonne of open-source modules that greatly simplify web scraping. A few of these are as follows :
Another Python package that is frequently used to extract data from XML and HTML texts is called BeautifulSoup. Large swaths of data are significantly simpler to navigate and search through because of BeautifulSoup's organization of this processed stuff into more user-friendly trees. It is frequently the data analyst's preferred tool.
A Python-based application framework called Scrapy scans the web and pulls structured data from it. It is frequently employed for information processing, data mining, and the preservation of historical content. It can be used as a general-purpose web crawler or to extract data through APIs in addition to web scraping, for which it was specially created.
Pandas
Another general-purpose Python library for data manipulation and indexing is called Pandas. It can be used in conjunction with BeautifulSoup to scrape the web. The key advantage of utilizing pandas is that analysts don't have to transfer to other languages, such as R, in order to complete the data analysis process.
Other tools are readily available, ranging from those used for general-purpose scraping to those created for more intricate, specialized jobs. The best course of action is to investigate which technologies best fit your interests and skill level before incorporating them into your data analytics toolbox.
What Steps Can I Take To Stop Content From My Website Being Scraped?
The fact that website content scraping is so frequently utilized for acceptable objectives, such as search engine optimization (SEO), makes it a difficult task to prevent. Publishers can employ the following techniques to lessen the chance that their content will be illegal or unauthorized scraped:
- Robots.txt files : Web crawlers and scrapers can read robots.txt files to find out which websites are appropriate for access and scraping.
- CAPTCHAs : By establishing tests that are simple for people to complete but challenging for computer programs to complete, CAPTCHAs could prevent unpleasant scraper tools.
- Request limits : Use rules called "request limits" to restrict how frequently a website can receive HTTP requests from scrapers.
- Code obfuscation : Use techniques like minification (The term "minification" refers to the process of modifying code to eliminate extraneous characters and parts.), renaming variables, and functions, or encoding to make JavaScript into code that is difficult to read and understand.
- IP Blocking : keep an eye on server records for scraper activity and block suspected scrapers IP addresses.
- Legal Action : Take legal action to stop unauthorized scraping by complaining to the hosting company or requesting a court injunction.
Methods for Using Websites to Scrape Data
Establish the Target URLs : Make a list of the target URLs (i.e., the web pages you'll be extracting data from) once you've determined which website you want to scrape data from. Remember to look over the web pages to find the precise data you want to scrape.
Access the Website by Sending an HTTP Request : You can arrange requests and responses across the internet using the application layer protocol HTTP. Data must be transferred from one location to another via the network using the server-client mechanism of HTTP. Your computer or smartphone can function as the client, while the web host is the server, ready to provide the data upon a successful request. When the client requests data from the server, the server requires a GET response. Be aware that the methods used by various programs and computer languages to send HTTP requests vary. The server provides the data in response to the HTTP request, enabling you to view the HTML or XML page.
Download Page Content from Target Urls (Data Downloading) : You can download a web page and view its contents on your screen by using data fetching.
Remove Information from the Page (Data Parsing) : After extracting data from the target URLs, you must parse it to make it easier to understand and suitable for data analysis. Because it is difficult to understand plain HTML data, data parsing is required. Data must first be displayed in an understandable format for the data analyst. This could entail producing reports from HTML strings or making data tables that display appropriate data.
The extracted data should be formatted : The parsed data can then be exported into an Excel, Google Sheets, or CSV spreadsheet. You can utilize APIs because many automated web scraping solutions accept formats like JSON.
Prevention of Web Crawling
Some standard security precautions are no longer effective due to the intelligence of malicious scraper bots. For instance, headless browser bots can pose as humans in order to avoid detection by the majority of mitigation techniques. Imperva employs detailed traffic analysis to thwart the advancements made by harmful bot operators. It makes sure that both human and automated traffic to your website is entirely valid.
A number of criteria are cross-verified during the process, including:
- TLS fingerprint: A thorough examination of HTML headers serves as the first step in the filtering process. These can offer hints as to whether a visitor is dangerous or safe, a human or a bot. A database of more than 10 million known variants that are updated often is used to compare header signatures.
- IP reputation: Gather IP information from all assaults on our clients. Visits from IP addresses that have a history of being used in assaults are viewed suspiciously and are more likely to undergo further inspection.
- Behavior analysis: Monitoring how users interact with a website might show odd patterns of behavior, such as suspiciously high request rates and irrational browsing habits. This makes it easier to spot visitors who are actually bots.
- Progressive challenges: Progressive challenges are used to screen out bots and reduce false positives. These challenges include cookie support and JavaScript execution. A CAPTCHA challenge can, as a last resort, eliminate bots that are attempting to impersonate humans.
Examples of Web Scraping
When data is taken from websites without the owners' consent, the practice is known as web scraping, which is harmful. Price scraping and content theft are the two most typical use scenarios.
Scraping prices: In order to scan competitor business datasets, a perpetrator of price scraping often launches scraper bots from a botnet. The objective is to gain access to pricing data, undercut competitors, and increase sales. Attacks usually happen in sectors where goods are readily comparable and pricing influences purchases greatly. Travel providers, ticket sellers, and online electronics vendors can all fall prey to price scraping.
Scraping content : Large-scale content stealing from a specific website is referred to as content scraping. Online product directories and websites that rely on digital content to generate traffic are common targets. A content scraping attack could be fatal for these businesses.
What Makes Python Such A Valued Programming Language For Web Scraping?
These days, Python seems to be trendy! Because it can readily manage most tasks, it is the most widely used language for web scraping. Additionally, it offers a number of libraries designed expressly for web scraping. Python-based Scrapy is a fairly well-known open-source web crawling framework. It is perfect for both API-based data extraction and web scraping. Another Python module that is excellent for web scraping is called Beautiful Soup. In order to extract data from HTML on a website, it produces a parse tree. These parse trees can be navigated, searched, and modified using a variety of capabilities in Beautiful Soup.