
Harivony Ratefiarison
August 5, 2025
•
17
min read
•
53
votes
•
Scraping

Reddit is a community-based platform organized into Subreddits where discussions are in a forum-style structure. It is an excellent source of data for Natural Language Processing (NLP), LLM training, sentiment analysis, and dataset generation.
Unlike other platforms that rely on opaque algorithms, Reddit ranks content using a transparent upvote system, making it a rich source for AI training data.
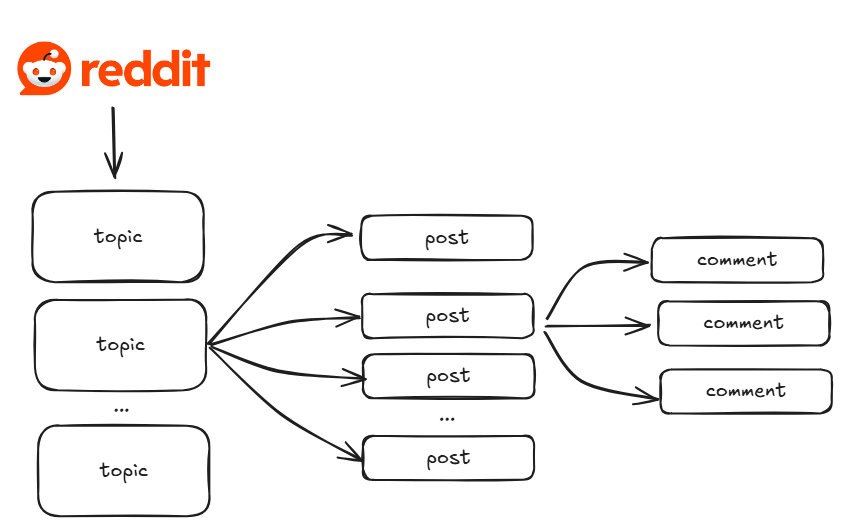
“Reddit's huge amount of data works well for AI companies because it is organised by topics and uses a voting system instead of algorithm to sort content quality” source
Reddit scraping can have a wide range of uses, such as:
Functions are modular in this project. It means that scripts are reusable. For example, if you need to scrape only the list of all topics, just copy and paste the reddit_topics script in your project.
What's next ?
This tutorial is divided into two standalone sections that you can follow in any order:
Clone the project :
git clone https://github.com/harivonyR/Reddit_topic_scraperInstall dependencies :
pip install requests beautifulsoup4Copy the example credentials:
cp credential.exemple.py credential.pyEdit `credential.py` and paste your API key (visit piloterr.com if you don't have one):
x_api_key = "your_actual_api_key_here"Run the main script :
python main.pyThis runs a one-time execution of the three modules: topics, posts, and comments.
It demonstrates how each module works and allows for testing before triggering the full scraping pipeline.
tips: If everything runs as expected, uncomment Step 4 to launch the complete pipeline
This will iterate through all Reddit topics in a continuous loop. In that case, the previous steps can be commented out, as they become optional.
# Step 1: Scrape all Reddit topics and save them
all_reddit_topics = scrape_all()
save_csv(all_reddit_topics, "output/all_reddit_topics.csv")
print(f"[topics] : {len(all_reddit_topics)} topics successfully scraped and saved.\n")
# Step 2: Scrape posts from a sample topic
sample_topic_link = "https://www.reddit.com/t/american_top_team/"
posts = scrape_post(sample_topic_link, wait_in_seconds=10, scroll=0)
print(f"[posts] : {len(posts)} posts scraped from sample topic.\n")
# Step 3: Scrape comments from a sample post
sample_post_link = "https://www.reddit.com/r/IndiaCricket/comments/1dniwap/aaron_finch_shuts_up_dk_during_commentary/"
comments = scrape_comment(post_url=sample_post_link, wait_in_seconds=5, scroll=2)
print(f"[comments] : {len(comments)} comments scraped from sample post.\n")
# Step 4: Full end-to-end pipeline
# Note: Uncomment the line below to run a full scrape of all topics, posts, and comments.
# This process may take considerable time due to the large volume of data.
# reddit_scraping_all()
In this section we will just copy and paste functions. Perfect for a scraping project that needs a ready to go function.
First of all, copy and paste the script folder in the root of your project, then call function :
To get started, we obviously need the website URL. Additional parameters can be added to simulate user behavior if necessary, for instance, use wait_in_seconds if the content takes time to load, or add a scroll argument to fetch more content.
from script.piloterr import website_crawler, website_rendering
url = “https://www.reddit.com/topics/a-2/” # targeted url sample
html_response_1 = website_crawler(site_url=url )
html_response_2 = website_rendering(site_url=url , wait_in_seconds=5, scroll=2)This function doesn't need parameters since the topics directory starts from "https://www.reddit.com/topics/a-1/". Then choose a preferred output directory.
from script.reddit_topics import scrape_all, save_csv
all_reddit_topics = scrape_all()
save_csv(all_reddit_topics, "output/all_reddit_topics.csv")This function will return every post found in a Reddit topics :
from script.reddit_posts import scrape_post
american_top_tem = "https://www.reddit.com/t/american_top_team/"
posts = scrape_post(american_top_tem,wait_in_seconds=10, scroll=1)This step extracts nested comments from a post, including each comment's content, depth level, and parent ID. This structure ensures no information is lost, which is particularly important for reply analysis.
from script.reddit_comments import scrape_comment
sample_post_link = "https://www.reddit.com/r/IndiaCricket/comments/1dniwap/aaron_finch_shuts_up_dk_during_commentary/"
comments = scrape_comment(post_url=sample_post_link, wait_in_seconds=5, scroll=2)In this chapter, we will build the Reddit scraper step by step. This modular approach makes it easy to customize or integrate into another scraping project.
We begin by creating a script to handle API requests to avoid redundancy. This function is located in script/piloterr.py.
Piloterr provides two types of website scraping that can be used with any URL. In both cases, it returns the HTML code of the targeted website.
What are the key differences ?
The Website Crawler is designed for simple, fast web scraping with basic functionality. It is suitable for scraping static websites, like Reddit’s “Topics Directory”.
We create a basic function that we will call multiple times. It only requires the x_api_key and the target URL as parameters.
💡 To use any Piloterr API, you need an API key. Create an account on Piloterr.com to receive free credits for testing.
from credential import x_api_key
import requests
def website_crawler(site_url):
url = "https://piloterr.com/api/v2/website/crawler"
headers = {"x-api-key": x_api_key}
querystring = {"query":site_url}
response = requests.request("GET", url, headers=headers,params=querystring)
return response.textTo use the Website Crawler function: just import the function and add the URL as a parameter.
from script/piloterr import website_crawler
response = website_crawler(url=”https://www.reddit.com/topics/a-1/”)
💡 Tips : Explore the official documentation here : Piloterr Web Crawler API docs
The Website Rendering API is designed for advanced web scraping with browser simulation like Wait for specific elements to appear in the DOM or use Scrolling to load more content. It is the best for scraping more posts or comments.
from credential import x_api_key
import requests
def website_rendering(site_url, wait_in_seconds=5, scroll=0):
"""
Render a website using Piloterr API.
Supports optional scroll to bottom.
"""
url = "https://piloterr.com/api/v2/website/rendering"
querystring = {"query": site_url, "wait_in_seconds": str(wait_in_seconds)}
headers = {"x-api-key": x_api_key}
# case where we don't need to scroll
if scroll == 0:
response = requests.get(url, headers=headers, params=querystring)
# with scrolling
else:
smooth_scroll = [
{
"type": "scroll",
"x": 0,
"y": 2000, # vertical scrolling height : 2000 pixels down
"duration": 3, # scrolling duration in second (s)
"wait_time_s": 4 # wait time in second (s) before the next instruction.
}
]
instruction = {
"query": site_url,
"wait_in_seconds": str(wait_in_seconds),
"browser_instructions": smooth_scroll*scroll # this will repeat scrolling
}
response = requests.post(url, headers=headers, json=instruction)
return response.textHow to use the Website Rendering function ?
from script.piloterr import website_rendering
response = website_rendering(site_url=topic_url, wait_in_seconds=10,scroll=2)This will open "https://www.reddit.com/t/a_quiet_place/", wait 10 seconds, then repeat scrolling two times before returning the HTML CODE.
💡 Tips : Explore more parameters in the official documentation here : Piloterr Web Rendering API docs
From the previous section, we now know how to retrieve the HTML of any website using just a URL and optional parameters to optimize our scraping.
Let’s now extract useful data from that HTML, starting with the links behind topic names in Reddit’s “Topics Directory”.
This is where we begin extracting data from Reddit. At this stage, we are only interested in links that will later be used to fetch posts.
Let’s review the project structure and locate the script/reddit_topics file.
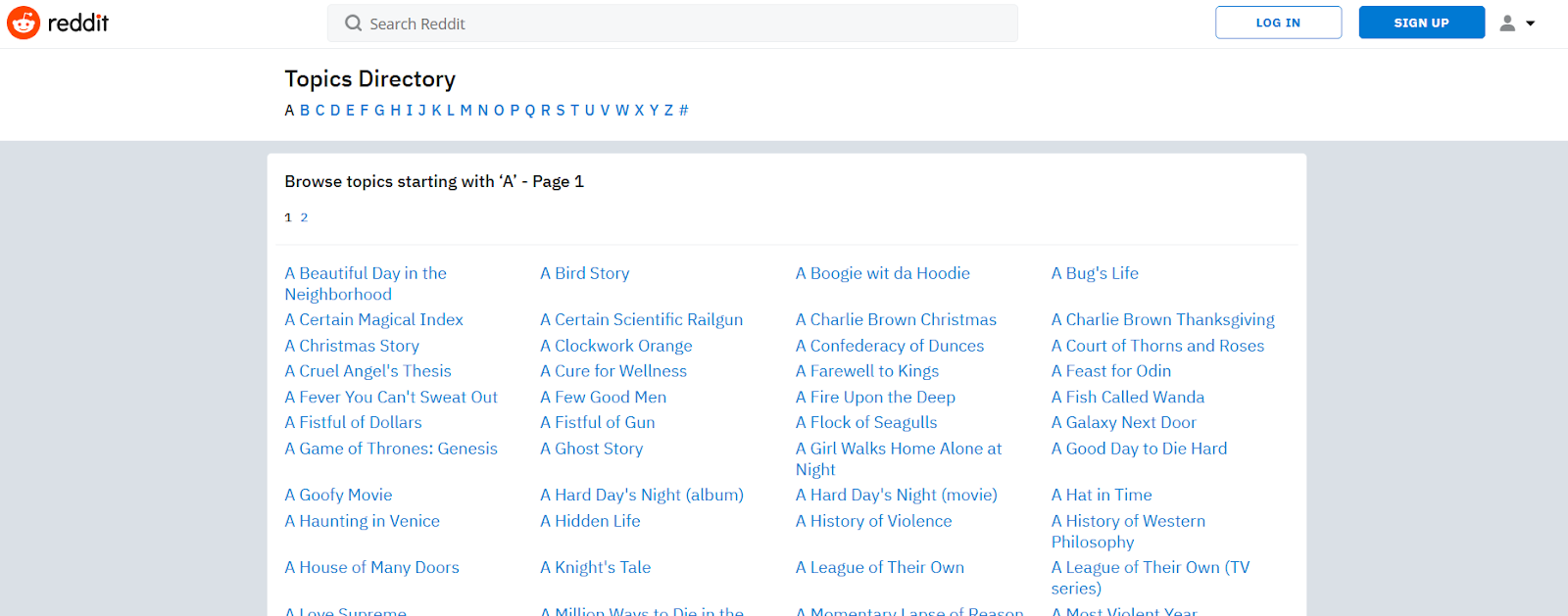
Scraping should start with the letter “a” on page 1: https://www.reddit.com/topics/a-1/
Here’s what the page looks like:
To retrieve all the topic links, we will build three functions : get_letter_pages, get_subpages, scrape_topics.
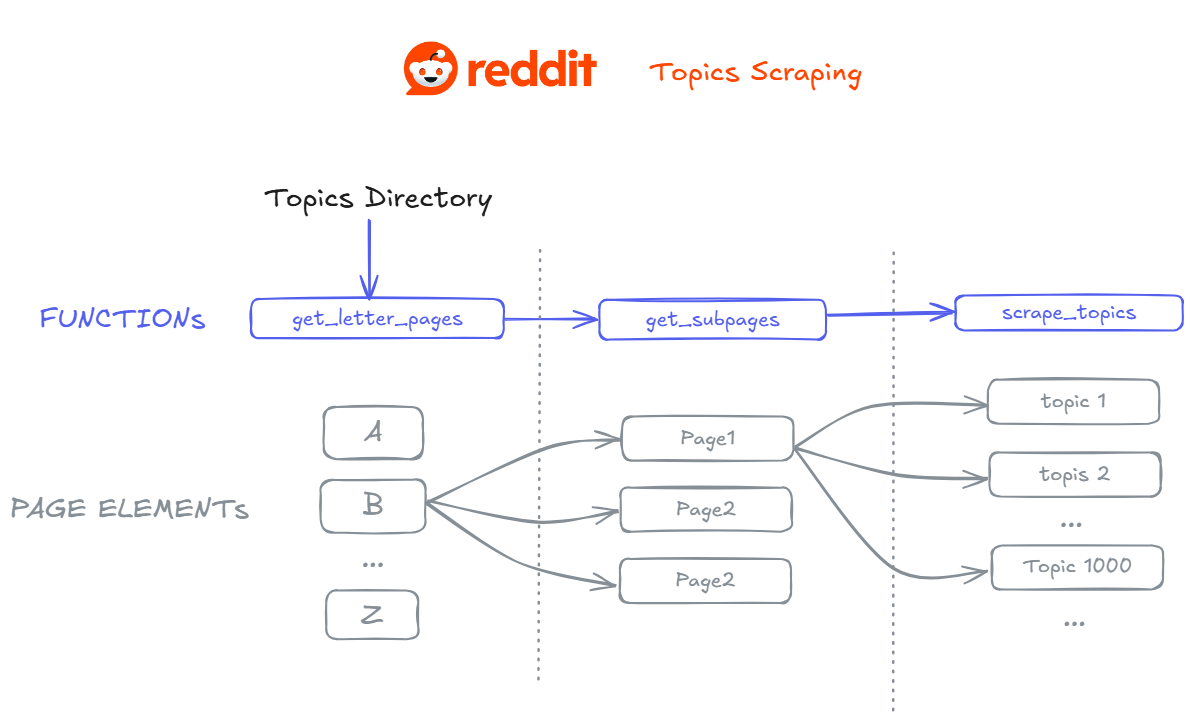
First, we need to identify all existing letters that start a Reddit directory using the get_letter_pages() function. This function will select and concatenate internal links with the Reddit domain to produce usable URLs.
💡 Tip: Use the following line to clean HTML:
response.encode('utf-8').decode('unicode_escape')
This ensures BeautifulSoup won’t encounter issues when parsing elements.

from script.piloterr import website_crawler
from bs4 import BeautifulSoup
import csv
import os
def get_letter_pages():
"""
Get all topic sections by letter (A-Z).
Each link points to a paginated topic list.
"""
site_url = "https://www.reddit.com/topics/a-1/"
response = website_crawler(site_url=site_url)
clean_html = response.encode('utf-8').decode('unicode_escape')
soup = BeautifulSoup(clean_html, 'html.parser')
links = soup.find_all("a", attrs={"class": "page-letter"})
letters_href = ["https://www.reddit.com" + link.get("href") for link in links]
letters_href.insert(0, site_url)
print(f"> all topics found by lettre : \n {letters_href}")
return letters_hrefNow that we have the letters, we’ll scrape the existing subpages. Most letters only have one page, but some, for example the letter "S", can have up to three pages :
💡 Tip: Use this CSS selector to select pages in the Topics section:
“div.digit-pagination.top-pagination a.page-number”
def get_subpages(site_url):
"""
Get all paginated pages for a given letter section.
Includes the first page.
"""
response = website_crawler(site_url=site_url)
clean_html = response.encode('utf-8').decode('unicode_escape')
soup = BeautifulSoup(clean_html, 'html.parser')
pages = soup.select("div.digit-pagination.top-pagination a.page-number")
pages_href = ["https://www.reddit.com" + page.get("href") for page in pages]
pages_href.insert(0, site_url)
print("> pages href : {pages_href}")
return pages_hrefLast, but not the least, we’ll scrape the topic titles and links found on each topic directory page.
def scrape_topics(site_url):
"""
Get all topics and links from a topic page.
Returns a list of dicts: [{topic: link}, ...]
"""
response = website_crawler(site_url=site_url)
clean_html = response.encode('utf-8').decode('unicode_escape')
soup = BeautifulSoup(clean_html, 'html.parser')
topics = soup.select('a.topic-link')
topics_list = []
for topic in topics:
text = topic.get_text(strip=True)
href = topic.get('href')
print(f"{text} : {href}")
topics_list.append({text: href})
print("------------------")
print(f"{site_url} : found {len(topics_list)} topics")
print("------------------")
return topics_listOnce all functions are defined, we can bring everything together to collect all topic links using a scrape_all() function :
def scrape_all():
"""
Collect all topics across all letter sections and pages.
Returns a flat list of dicts: [{topic: link}, ...]
"""
letter_list = get_letter_pages()
page_list = []
for letter_link in letter_list:
pages = get_subpages(letter_link)
page_list.extend(pages)
full_topics_list = []
for page in page_list:
topics = scrape_topics(page)
full_topics_list.extend(topics)
print(f"> all topics found : {len(full_topics_list)}")
return full_topics_list💡 tips :
You can copy the full code from this repository : Reddit topic scraper full code
Finally, call the function, no parameters are needed since it uses a default starting URL for the Topics directory. Once the scraping is done, don’t forget to save the scraped data to avoid repeating the process.
Call scrap_all and save data :
full_topics_list = scrape_all() # scrape all existing reddit topic
save_csv(full_topics_list, destination="output/all_reddit_topics.csv")Output :
In this section, we will extract all posts listed under a specific Reddit topic. Each post contains metadata such as the author, score, number of comments, and the post content itself.
To do this, we will use the script/reddit_posts module, which handles the logic for fetching and parsing post data from the HTML previously obtained.
Let’s take a closer look at how this part of the project is structured :
To build a dataset of Reddit posts, we parse each article element from the topic page's HTML. Each post is represented by a <shreddit-post> tag containing post data.
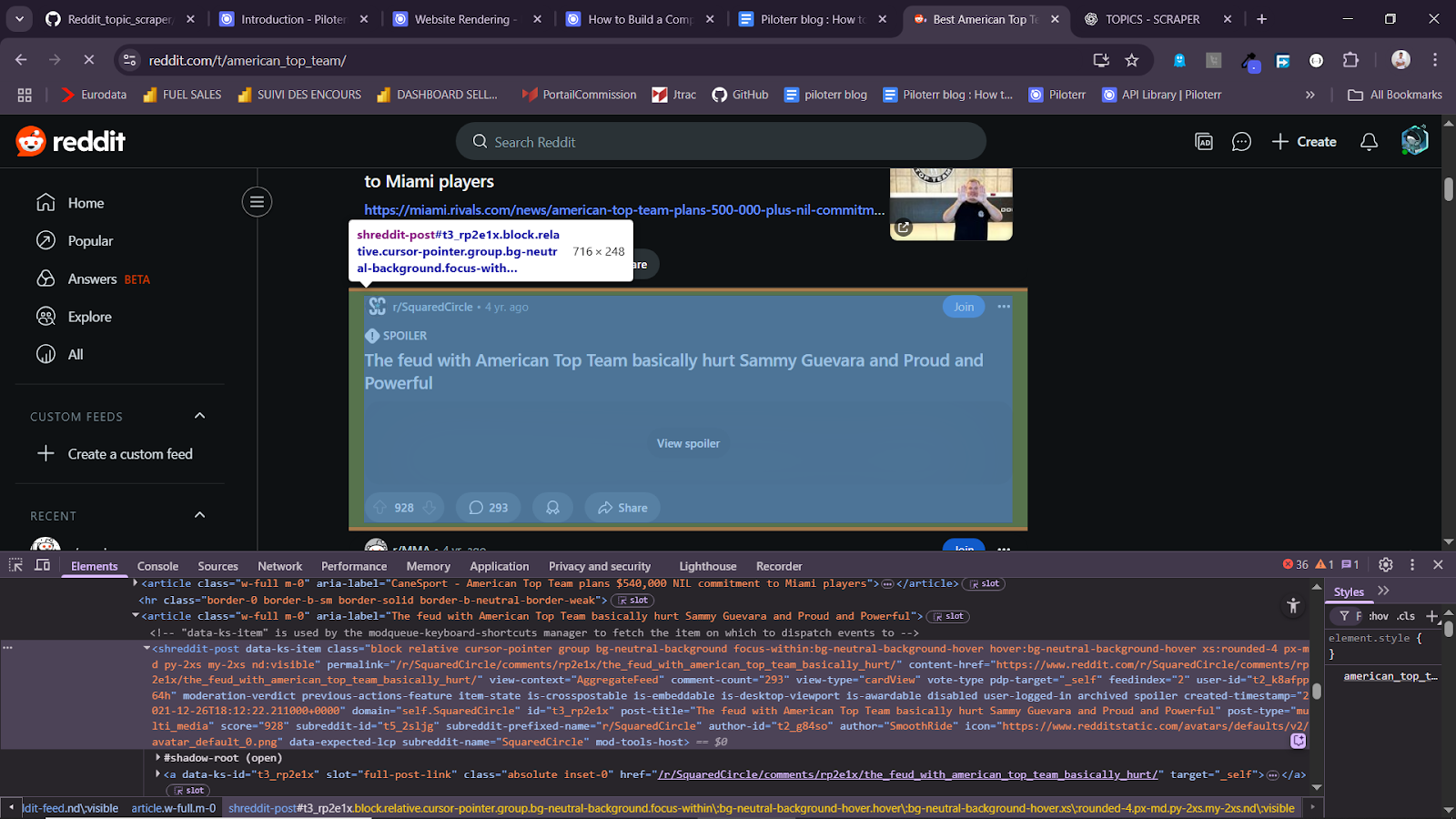
Then, we construct our dataset using the BeautifulSoup selector. This function may include scrape_comment. We will explore how to scrape comments in the next section.
post = {
"title": article.get("aria-label","#N/A"),
"author": shreddit_post.get("author","#N/A"),
"link": post_link,
"date": shreddit_post.get("created-timestamp","#N/A"),
"comment_count": shreddit_post.get("comment-count", "#N/A"),
"score": shreddit_post.get("score","#N/A")#,
"comment": scrape_comment(post_url=post_link,wait_in_seconds=5, scroll=2)
}Here the full code :
from script.piloterr import website_crawler, website_rendering
from script.reddit_comments import scrape_comment
from bs4 import BeautifulSoup
# 1 - Fetch post data with post_link (we need this to fetch comments later)
#------------------------------------------------------------------------------
def scrape_post(topic_url,wait_in_seconds=10, scroll=2 ):
print("------------------")
print(f"scraping topics : {topic_url}")
# url is a topic link on reddit
response = website_rendering(topic_url,wait_in_seconds, scroll)
# Decode raw HTML
clean_html = response.encode('utf-8').decode('unicode_escape')
soup = BeautifulSoup(clean_html, 'html.parser')
# Select all posts
articles = soup.select('article')
posts = []
for article in articles:
try:
shreddit_post = article.find("shreddit-post")
post_link = "https://www.reddit.com"+article.find("a", href=True).get("href")
post = {
"title": article.get("aria-label","#N/A"),
"author": shreddit_post.get("author","#N/A"),
"link": post_link,
"date": shreddit_post.get("created-timestamp","#N/A"),
"comment_count": shreddit_post.get("comment-count", "#N/A"),
"score": shreddit_post.get("score","#N/A")#,
"comment": scrape_comment(post_url=post_link,wait_in_seconds=5, scroll=2)
}
print(f"post scraped : {article.get('aria-label','#N/A')}")
print("-------------------")
posts.append(post)
except Exception as e:
print(f"Error parsing article: {e}")
return posts
if __name__ == "__main__":
# sample
american_top_tem = "https://www.reddit.com/t/american_top_team/"
posts = scrape_post(american_top_tem,wait_in_seconds=10, scroll=0)To begin, we need the post_url collected in the previous section.
We can extract two useful information at this time :
Extract Additional Post Metadata
We use specific attributes from the <shreddit-post> element to enrich our dataset with useful metadata such as the title, author, score, and comment count. This also helps validate that the post was correctly loaded before scraping its comments.
post_details = {
"comment_count": post.get("comment-count", "0"),
"score": post.get("score", "0"),
"author": post.get("author", "#N/A"),
"text_content": post.select_one('div[slot="text-body"]').get_text(strip=True) if post.select_one('div[slot="text-body"]') else None,
"title": post.select_one("h1").get_text(strip=True) if post.select_one("h1") else None,
}Get nested comment
Reddit comments are nested and stored within <shreddit-comment> elements.
Each comment may have metadata and parent-child relationships that are essential for reconstructing threaded discussions.
data = {
"author": comment.get("author", "#N/A"),
"time": comment.select_one("time")["datetime"] if comment.select_one("time") else None,
"score": comment.get("score", "#N/A"),
"depth": comment.get("depth", "#N/A"),
"post_id": comment.get("postid", None),
"parent_id": comment.get("parentid", None),
"content_type": comment.get("content-type", None),
"content": [p.get_text(strip=True) for p in comment.find_all("p")] or None
}Full Code Example :
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 21 20:45:43 2025
@author: BEST
"""
from script.piloterr import website_rendering
from bs4 import BeautifulSoup
# 1 - Fetch post data with post_link (we need this to fetch comments later)
#------------------------------------------------------------------------------
def scrape_comment(post_url,wait_in_seconds=10, scroll=0):
print("-------------------------------")
print(f"scraping comment from {post_url}")
response = website_rendering(site_url = post_url,wait_in_seconds=wait_in_seconds,scroll=scroll)
# Decode raw HTML
clean_html = response.encode('utf-8').decode('unicode_escape')
soup = BeautifulSoup(clean_html, 'html.parser')
# get post details
# ----------------
post = soup.select_one("shreddit-post")
post_details = {
"comment_count": post.get("comment-count", "0"),
"score": post.get("score", "0"),
"author": post.get("author", "#N/A"),
"text_content": post.select_one('div[slot="text-body"]').get_text(strip=True) if post.select_one('div[slot="text-body"]') else None,
"title": post.select_one("h1").get_text(strip=True) if post.select_one("h1") else None,
}
# get comment details
# --------------------
comments = soup.select('shreddit-comment')
# scrape data from comment
comment_details = []
for comment in comments:
try:
data = {
"author": comment.get("author", "#N/A"),
"time": comment.select_one("time")["datetime"] if comment.select_one("time") else None,
"score": comment.get("score", "#N/A"),
"depth": comment.get("depth", "#N/A"),
"post_id": comment.get("postid", None),
"parent_id": comment.get("parentid", None),
"content_type": comment.get("content-type", None),
"content": [p.get_text(strip=True) for p in comment.find_all("p")] or None
}
comment_details.append(data)
print(f"author comment scrapped : {comment.get('author', '#N/A')}")
except Exception as e:
print(f"error: {e}")
continue
return {"post_details":post_details,"comment_details":comment_details}
if __name__=="__main__":
reddit = "https://www.reddit.com/r/IndiaCricket/comments/1dniwap/aaron_finch_shuts_up_dk_during_commentary/"
comment = scrape_comment(post_url=reddit,wait_in_seconds=5, scroll=2)Finally, we loop and connect all components scraping : topic directory, post extraction, and comment parsing, into a single pipeline function.
We run full pipeline by calling in the main function reddit_scraping_all, we trigger:
reddit_scraping_all(output_folder="output", wait=5, scroll=2)See full function below :
from script.reddit_topics import scrape_all, save_csv
from script.reddit_posts import scrape_post
from script.reddit_comments import scrape_comment
# -------------------------------------------------------
# FULL PIPELINE: loop through topics > posts > comments
# -------------------------------------------------------
def reddit_scraping_all(output_folder="output", wait=5, scroll=2):
"""
Runs the full Reddit scraping pipeline:
1. Scrape all topics and save them.
2. For each topic, scrape posts.
3. For each post, scrape comments.
Args:
output_folder (str): Folder to save CSVs.
wait (int): Wait time between requests (seconds).
scroll (int): Number of scroll iterations for dynamic loading.
Returns:
list: A list of all comments scraped across all posts.
"""
print("\n[RUNNING] Full Reddit Scraping Pipeline")
all_reddit_topics = scrape_all()
save_csv(all_reddit_topics, f"{output_folder}/all_reddit_topics.csv")
print(f"[topics] {len(all_reddit_topics)} topics saved to CSV.")
all_results = []
for topic, link in all_reddit_topics.items():
print(f"\n[TOPIC] : {topic} - {link}")
try:
posts = scrape_post(link, wait_in_seconds=wait, scroll=scroll)
print(f"> {len(posts)} posts found.")
for post in posts:
try:
comments = scrape_comment(post_url=post, wait_in_seconds=wait, scroll=scroll)
all_results.append(comments)
print(f" Scraped {len(comments)} comments from post.")
except Exception as e:
print(f" Error scraping comments from {post}: {e}")
except Exception as e:
print(f" TOPIC scraping {topic} : error {e}")
print("\n [Pipeline] completed !")
return all_resultsInterviews, tips, guides, industry best practices and news.
