Garantizar datos de alta calidad en operaciones de web scraping es un desafío multifacético, crucial para análisis y toma de decisiones confiables. A medida que los proyectos de web scraping escalan, la complejidad de validar la corrección y completitud de los datos raspados aumenta, lo que potencialmente disminuye la calidad de los datos. Este artículo presenta una visión general completa de técnicas para mejorar la integridad de los proyectos de web scraping.
Los datos confiables comienzan con una extracción confiable: explora Scraper APIs y nuestro glosario de calidad de datos.
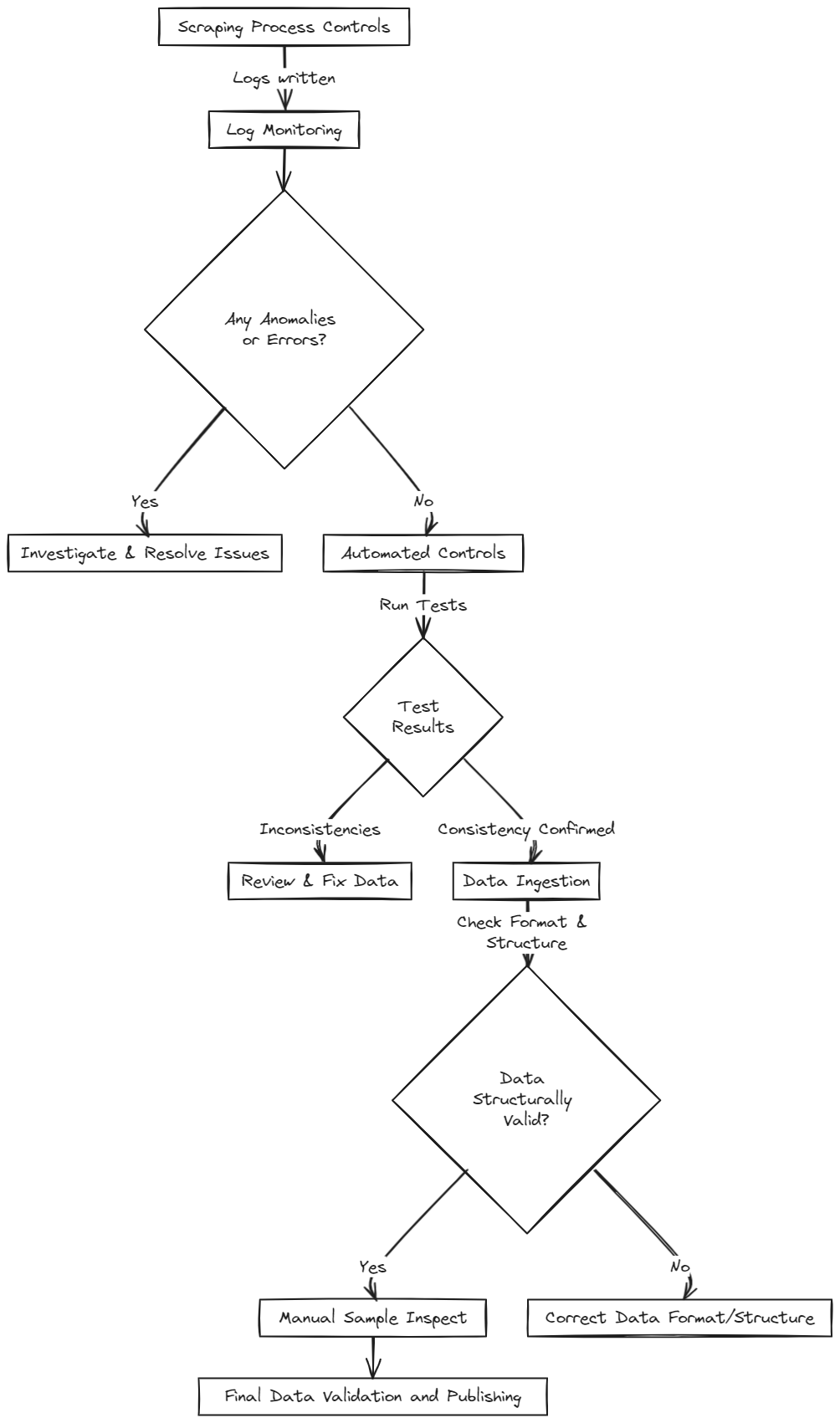
Monitoreo del Proceso de Scraping
**La gestión efectiva de la calidad de los datos comienza con raspadores bien diseñados que registran su actividad, destacando posibles problemas a través de códigos de retorno HTTP. Por ejemplo, un error 404 indica una página faltante, posiblemente debido a un enlace roto o una medida anti-bot, lo que lleva a datos parciales o incompletos. Recopilar estos registros, como lo hace Scrapy, es esencial para la solución de problemas.
Ingesta de Datos
**Los cambios en las estructuras de las páginas web pueden llevar a que los selectores se rompan, capturando datos en formatos inesperados. Implementar verificaciones durante la carga en la base de datos ofrece un punto centralizado de control para mantener la consistencia de los datos a través de múltiples fuentes de scraping.
Controles Automáticos de Calidad de Datos
**Dependiendo del tipo de datos, se pueden instituir varias verificaciones automáticas. Los campos numéricos, como los precios de los productos, pueden validarse automáticamente por coherencia, mientras que los datos cualitativos, como los campos de texto, pueden requerir diferentes estrategias.
Completitud y Coherencia de los Datos
**La completitud de los datos es una métrica fundamental, con alertas configuradas para discrepancias en los conteos de elementos esperados. Por ejemplo, Retailed.io utiliza un método de Verdad Terrenal, donde los desarrolladores proporcionan conteos de elementos esperados, que son revisados por pares y actualizados. Desviaciones significativas activan alertas, pausando la publicación de datos hasta que sean verificados.
Calidad de Datos Cualitativos
Los controles automatizados tienen limitaciones con los campos cualitativos. Aunque algunas verificaciones para valores de dominio conocidos o validaciones de formato (por ejemplo, correo electrónico, URLs) son posibles, la verdadera validez del contenido, como las descripciones de productos, puede requerir inspección manual.
Solo los datos que hayan pasado exitosamente todos los controles de calidad anteriores deben ser publicados.