Todos buscan desarrollar y utilizar nuevas tecnologías en la intensa competencia de hoy en día. El acto de descargar automáticamente datos de sitios web a tu computadora o base de datos se conoce como web scraping. El web scraping a menudo se denomina raspado de datos o extracción de datos web. El web scraping es una técnica automatizada para recopilar grandes cantidades de datos de sitios web. La mayoría de esta información está en formato HTML no estructurado y se convierte en información estructurada en una base de datos o hoja de cálculo para que pueda ser utilizada en diversas funciones. El web scraping puede llevarse a cabo utilizando una serie de técnicas para recopilar datos de sitios web. Estas incluyen el uso de APIs específicas, servicios en línea o incluso escribir tu propio código desde cero para el web scraping. Puedes acceder a los datos estructurados en muchos sitios web grandes, como Google, Twitter, Facebook, StackOverflow y otros, utilizando sus APIs. Aunque esta es la mejor opción, hay otros sitios web que no tienen el mismo nivel de complejidad tecnológica o no permiten a los usuarios acceder a grandes cantidades de datos estructurados. En ese caso, es mejor emplear el web scraping para recopilar datos del sitio web.
Las dos herramientas necesarias para el web scraping son el scraper y el crawler. El crawler es un sistema de inteligencia artificial que hace clic en enlaces para buscar en internet la información necesaria. En contraste, un scraper es una herramienta especial diseñada para extraer datos del sitio web. Según la escala y complejidad del proyecto, la arquitectura del scraper puede variar considerablemente para recuperar los datos de manera eficiente y precisa.
Usos del Web Scraping
Los usos más populares del web scraping son los siguientes:
- Generación de Leads para Marketing: Para fines de marketing, los leads pueden generarse utilizando una herramienta de web scraping. Al extraer la información de sitios web relevantes, se pueden crear listas de correos electrónicos y teléfonos para alcance en frío. Por ejemplo, se pueden extraer datos de sitios web que ofrecen listados de páginas amarillas o de listados de negocios en Google Maps para obtener el número de teléfono y la dirección de correo electrónico de una empresa.
- Evaluación de Precios y Observación de la Competencia: Las empresas que ofrecen productos o servicios deben tener información detallada sobre los productos y servicios de la competencia que se introducen constantemente en el mercado. Esta información puede ser monitoreada regularmente utilizando una herramienta de web scraping.
- Comercio Electrónico: Es posible extraer frecuentemente datos de productos de diferentes sitios web de comercio electrónico como Amazon, eBay, Google Shopping, etc., con la ayuda de una herramienta de web scraping. Una herramienta de web scraping facilita la recuperación de detalles del producto, incluyendo precios, descripciones, imágenes, reseñas y calificaciones.
- Bienes raíces: Se puede utilizar una herramienta de web scraping para recuperar los detalles de las propiedades publicadas en sitios web de bienes raíces como Zillow, Realtor y otros. Además de los datos de la propiedad, el web scraping puede utilizarse para recopilar información de contacto de propietarios y agentes.
- Análisis de Datos: La persona promedio podría querer recopilar y analizar información sobre una categoría específica de otros sitios web. Esta categoría incluye elementos como bienes raíces, automóviles, dispositivos electrónicos, contactos comerciales, junto con marketing. Los diversos sitios web que caen bajo la categoría dada presentan información de diferentes maneras. Es posible que no puedas ver toda la información de una vez incluso utilizando un solo sitio web. La información puede estar dividida entre varias páginas (similar a las listas paginadas o paginadas que se encuentran en los resultados de búsqueda de Google) y organizada en diferentes secciones.
- Evaluación Académica: Cualquier investigación, ya sea académica, de marketing o científica, debe contar con datos. Puedes recopilar fácilmente datos estructurados de numerosas fuentes en Internet con la ayuda de un web scraper.
- Datos para Proyectos de Aprendizaje Automático de Entrenamiento y Prueba: Con la ayuda del web scraping, puedes recopilar datos para probar y entrenar modelos de aprendizaje automático. La precisión de los datos de entrenamiento que utilices determina qué tan bien funcionan tus modelos de aprendizaje automático. Si los datos de entrenamiento no están fácilmente disponibles, puedes utilizar el web scraping para recopilarlos de diferentes fuentes.
- Análisis de Probabilidades de Apuestas Deportivas: Varios corredores de apuestas utilizan el web scraping para recopilar valores de probabilidades de apuestas de sitios web de apuestas deportivas como OddsPortal, BetExplorer, FlashScore, etc.
- Evaluación de Sentimientos: El análisis de sentimientos es esencial si las empresas desean comprender cómo se sienten los clientes en general acerca de sus productos. El web scraping es un método que las empresas utilizan para recopilar datos de plataformas de redes sociales como Facebook y Twitter sobre las percepciones generales que las personas tienen de sus productos. Como resultado, podrán superar a sus competidores y crear productos que la gente desee.
¿Cómo Funcionan los Web Scrapers?
Los web scrapers son capaces de recopilar toda la información de ciertos sitios web o la información específica que un usuario solicita. Para asegurar que solo los datos que necesitas sean extraídos rápidamente por el web scraper, este es el escenario ideal. Por ejemplo, podrías querer hacer scraping de un sitio web de Amazon para averiguar qué tipos de exprimidores están disponibles, pero podrías necesitar solo información sobre los modelos de los diferentes exprimidores y no los comentarios de los clientes.
Por lo tanto, primero se proporcionan las URLs cuando un web scraper necesita hacer scraping de un sitio web. Posteriormente, se carga todo el código HTML de los sitios web. Un scraper más sofisticado también podría extraer todos los componentes CSS y JavaScript. Después de extraer los datos necesarios del código HTML, el scraper los presenta en el formato que el usuario ha elegido. Más comúnmente, esto toma la forma de una hoja de cálculo de Excel o un archivo CSV, aunque la información también puede guardarse en otros formatos, como un archivo JSON.
¿Cuál Es El Proceso De Web Scraping Manual?
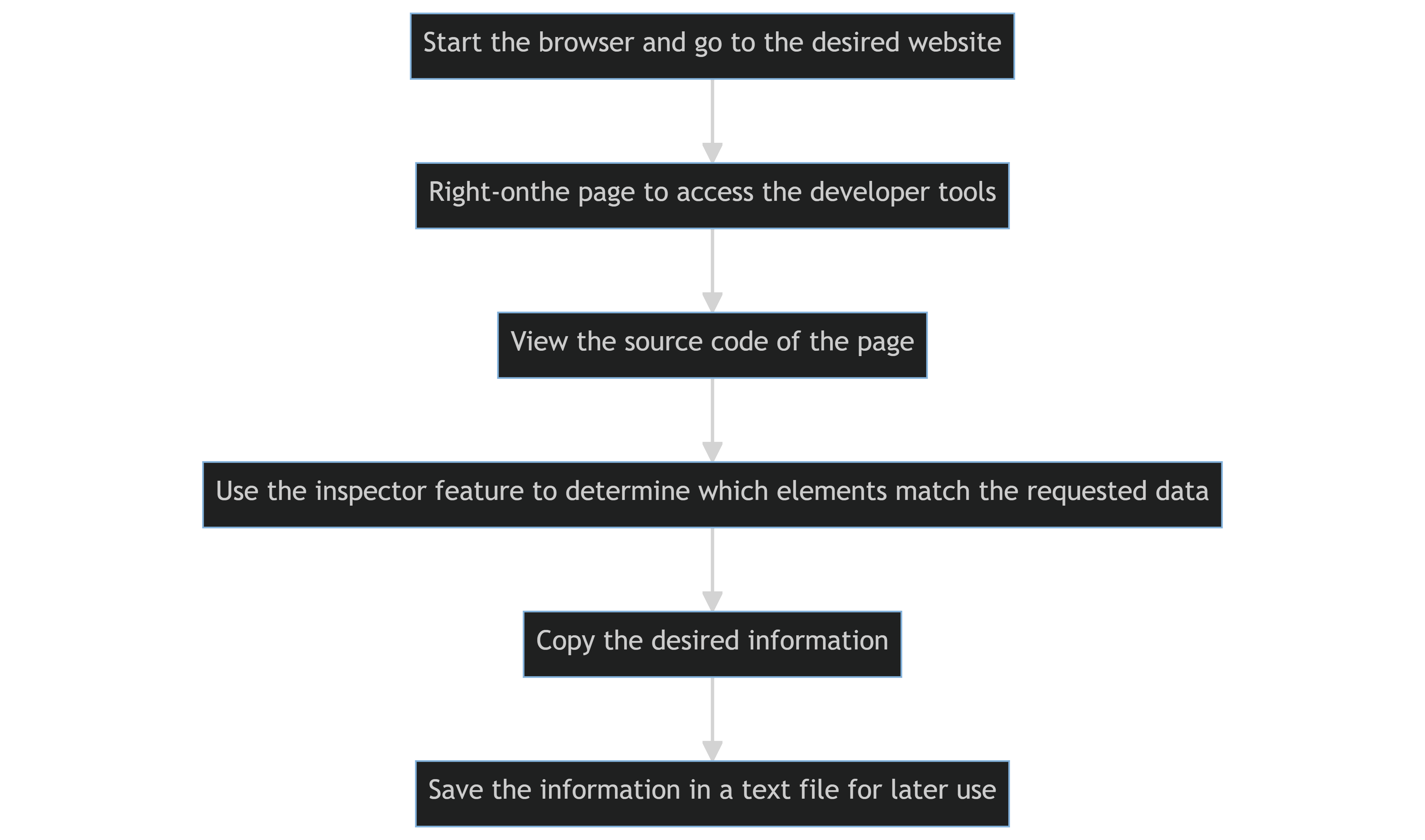
El código fuente de una página web se visualiza y extrae manualmente utilizando las herramientas de desarrollo de un navegador web.
Los pasos fundamentales son los siguientes:
- Iniciar el navegador y dirigirse al sitio web deseado.
- Para acceder a las herramientas de desarrollo en el navegador, hacer clic derecho en la página.
- Ver el código fuente de la página.
- Utilizar la función de inspector de tu navegador para determinar qué elementos en una página web corresponden a los datos solicitados.
- Copiar la información deseada.
- Copiar la información y guardarla en un archivo de texto para su uso posterior.
¿Cuál Es El Proceso De Web Scraping Automatizado?
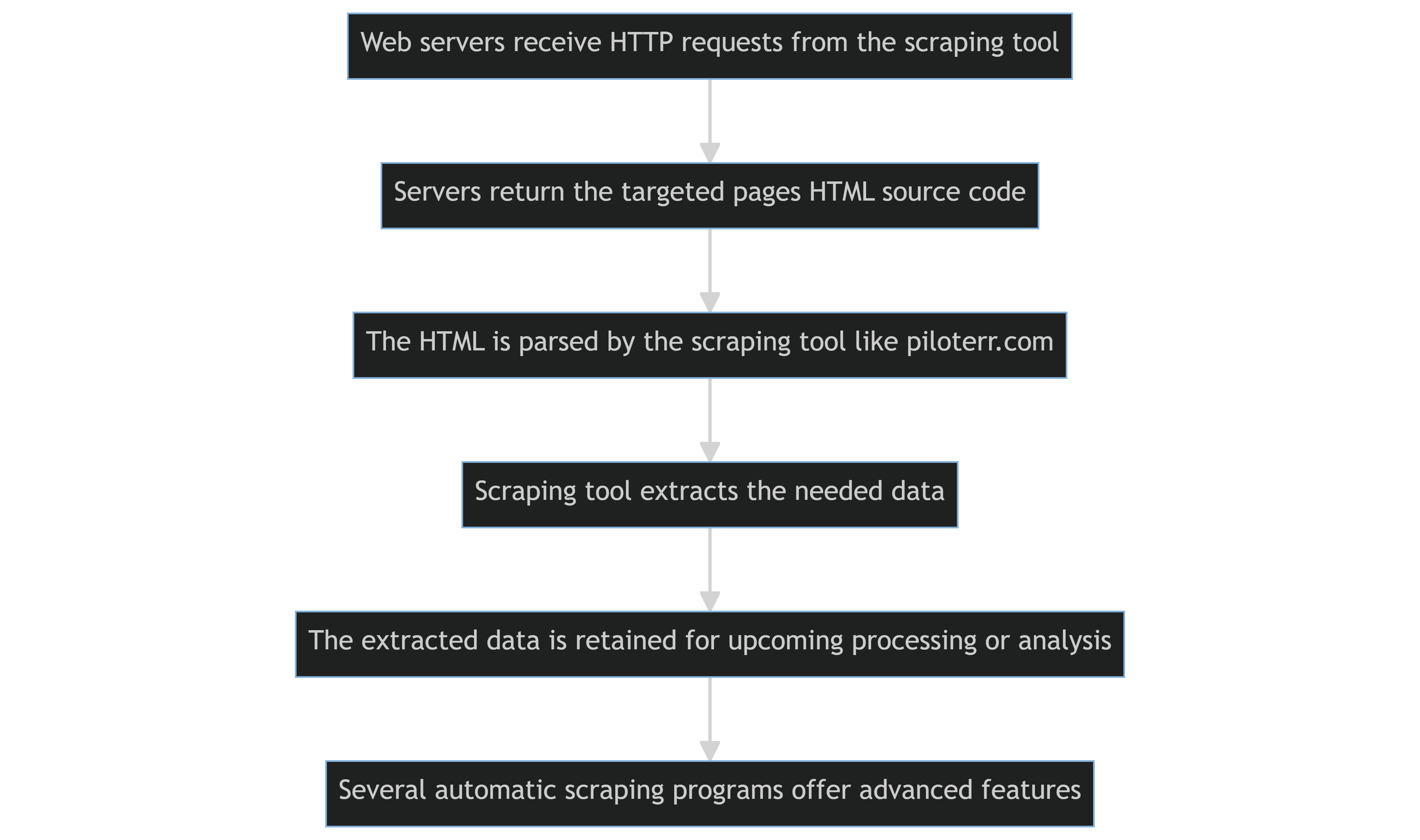
El uso de tecnologías de scraping, como scripts en Python o bibliotecas Scrapy, para extraer contenido de numerosos sitios web se conoce como web scraping automatizado.
Los pasos fundamentales son los siguientes:
- Las herramientas de scraping envían solicitudes HTTP a los servidores web que alojan los sitios web objetivo de manera programática.
- Los servidores devuelven el código fuente HTML de las páginas objetivo.
- La herramienta de scraping analiza el HTML y extrae los datos necesarios.
- Los datos extraídos se conservan para su procesamiento o análisis futuro.
- Varios programas automáticos de scraping web pueden ofrecer funcionalidades más avanzadas, como la capacidad de manejar cookies o eludir los Términos de Uso de un sitio web que prohíben o restringen el scraping de contenido.
Tipos de Web Scraping
Los web scrapers pueden clasificarse en muchos tipos distintos, incluyendo los creados por uno mismo o preconstruidos, software o extensión de navegador, en la nube o locales.
Web Scraping Autoconstruido: Es posible crear web scrapers por cuenta propia, pero requieren un alto nivel de conocimientos de programación. Además, se necesita aún más conocimiento si deseas que tu web scraper tenga más funcionalidades. Los web scrapers preconstruidos, por otro lado, son scrapers que ya han sido creados y son fáciles de descargar y usar. Puedes personalizar estos y añadir opciones más avanzadas también.
Extensiones de Navegador para Web Scraping: Existen extensiones para tu navegador, incluyendo web scrapers. Como están integradas en tu navegador, son fáciles de usar, pero esto también significa que tienen algunas limitaciones. Los web scrapers que funcionan como extensiones de navegador no pueden utilizar funciones complejas que están más allá de las capacidades de tu navegador. Sin embargo, los web scrapers de software, que pueden descargarse e instalarse en tu computadora, no tienen esta limitación. Aunque estos son más avanzados que los web scrapers de navegador, también incluyen funciones innovadoras que no están limitadas por las capacidades de tu navegador.
Web Scrapers en la Nube: El servidor externo que proporciona la empresa de la que compras el scraper generalmente ofrece la nube donde se ejecutan los web scrapers en la nube. Dado que no requieren raspar datos de sitios web, tu computadora puede concentrarse en otras tareas. Por otro lado, los web scrapers locales utilizan los recursos locales de tu computadora para funcionar. Por lo tanto, si los web scrapers necesitan más CPU o RAM, tu computadora se ralentizará y no podrá manejar otras operaciones.
¿Es Legal el Web Scraping?
El web scraping es generalmente aceptable siempre y cuando se realice con fines razonables y no contravenga las regulaciones de derechos de autor, acuerdos de licencia o los términos y condiciones de un sitio web.
La moralidad del web scraping depende principalmente de su uso previsto, los datos a los que se accede, los Términos de Uso del sitio y las leyes de privacidad en el estado-nación donde se realiza.
El Web Scraping No Es Necesariamente Difícil
Varias herramientas generales de web scraping tienen el inconveniente de ser bastante difíciles de aprender y operar. Implican una curva de aprendizaje significativa. Para abordar este problema, se creó WebHarvy. La interfaz extremadamente sencilla de apuntar y hacer clic de WebHarvy te permite comenzar a extraer datos de cualquier sitio web en solo unos minutos.
¿Qué Tipo De Herramientas Se Pueden Utilizar Para El Web Scraping?
Se necesitan habilidades de programación para el web scraping, siendo Python el lenguaje más comúnmente utilizado para esta tarea. Afortunadamente, Python cuenta con una gran cantidad de módulos de código abierto que simplifican enormemente el web scraping. Algunos de estos son los siguientes:
Otro paquete de Python que se utiliza frecuentemente para extraer datos de textos XML y HTML se llama BeautifulSoup. Grandes cantidades de datos son significativamente más fáciles de navegar y buscar gracias a la organización de este material procesado en árboles más amigables para el usuario que ofrece BeautifulSoup. A menudo es la herramienta preferida por los analistas de datos.
Un framework de aplicación basado en Python llamado Scrapy rastrea la web y extrae datos estructurados de ella. Se emplea frecuentemente para el procesamiento de información, la minería de datos y la preservación de contenido histórico. Puede usarse como un rastreador web de propósito general o para extraer datos a través de APIs además del web scraping, para el cual fue creado específicamente.
Pandas
Otra biblioteca de Python de propósito general para la manipulación e indexación de datos se llama Pandas. Puede usarse junto con BeautifulSoup para hacer web scraping. La principal ventaja de utilizar pandas es que los analistas no tienen que cambiar a otros lenguajes, como R, para completar el proceso de análisis de datos.
Existen otras herramientas disponibles, que van desde aquellas utilizadas para scraping de propósito general hasta las creadas para tareas más complejas y especializadas. La mejor opción es investigar qué tecnologías se adaptan mejor a tus intereses y nivel de habilidad antes de incorporarlas a tu caja de herramientas de análisis de datos.
¿Qué Pasos Puedo Tomar Para Evitar Que El Contenido De Mi Sitio Web Sea Scrapeado?
El hecho de que el scraping de contenido de sitios web se utilice con tanta frecuencia para objetivos aceptables, como la optimización para motores de búsqueda (SEO), hace que sea una tarea difícil de prevenir. Los editores pueden emplear las siguientes técnicas para reducir la probabilidad de que su contenido sea scrapeado de manera ilegal o no autorizada:
- Archivos Robots.txt: Los rastreadores y scrapers web pueden leer archivos robots.txt para saber qué sitios web son apropiados para acceder y hacer scraping.
- CAPTCHAs: Al establecer pruebas que son fáciles de completar para los humanos pero difíciles para los programas de computadora, los CAPTCHAs podrían evitar herramientas de scraper no deseadas.
- Límites de solicitudes: Usar reglas llamadas "límites de solicitudes" para restringir la frecuencia con la que un sitio web puede recibir solicitudes HTTP de scrapers.
- Ofuscación de código: Usar técnicas como la minificación (el término "minificación" se refiere al proceso de modificar el código para eliminar caracteres y partes innecesarias), renombrar variables y funciones, o codificación para convertir JavaScript en código difícil de leer y entender.
- Bloqueo de IP: Monitorear los registros del servidor en busca de actividad de scraper y bloquear las direcciones IP de los scrapers sospechosos.
- Acción Legal: Tomar acciones legales para detener el scraping no autorizado presentando una queja al proveedor de hosting o solicitando una orden judicial.
Métodos Para Usar Sitios Web Para Scrapear Datos
Establecer las URLs Objetivo: Haz una lista de las URLs objetivo (es decir, las páginas web de las que extraerás datos) una vez que hayas determinado de qué sitio web deseas extraer datos. Recuerda revisar las páginas web para encontrar los datos específicos que deseas scrapear.
Acceder al Sitio Web Enviando una Solicitud HTTP: Puedes organizar solicitudes y respuestas a través de internet utilizando el protocolo de capa de aplicación HTTP. Los datos deben transferirse de un lugar a otro a través de la red utilizando el mecanismo de servidor-cliente de HTTP. Tu computadora o smartphone puede funcionar como el cliente, mientras que el host web es el servidor, listo para proporcionar los datos tras una solicitud exitosa. Cuando el cliente solicita datos del servidor, el servidor requiere una respuesta GET. Ten en cuenta que los métodos utilizados por diferentes programas y lenguajes de computadora para enviar solicitudes HTTP varían. El servidor proporciona los datos en respuesta a la solicitud HTTP, permitiéndote ver la página en HTML o XML.
Descargar Contenido de Página de las URLs Objetivo (Descarga de Datos): Puedes descargar una página web y ver su contenido en tu pantalla utilizando la obtención de datos.
Extraer Información de la Página (Análisis de Datos): Después de extraer datos de las URLs objetivo, debes analizarlos para que sean más fáciles de entender y adecuados para el análisis de datos. Debido a que es difícil entender los datos en HTML plano, se requiere el análisis de datos. Los datos deben presentarse primero en un formato comprensible para el analista de datos. Esto podría implicar la generación de informes a partir de cadenas HTML o la creación de tablas de datos que muestren los datos apropiados.
Formatear los Datos Extraídos: Los datos analizados pueden luego exportarse a una hoja de cálculo de Excel, Google Sheets o CSV. Puedes utilizar APIs porque muchas soluciones automatizadas de web scraping aceptan formatos como JSON.
Prevención del Web Crawling
Algunas precauciones de seguridad estándar ya no son efectivas debido a la inteligencia de los bots de scraper maliciosos. Por ejemplo, los bots de navegadores sin cabeza pueden hacerse pasar por humanos para evitar la detección mediante la mayoría de las técnicas de mitigación. Imperva emplea un análisis detallado del tráfico para frustrar los avances realizados por operadores de bots maliciosos. Se asegura de que tanto el tráfico humano como el automatizado hacia tu sitio web sea completamente legítimo.
Durante el proceso se verifican varios criterios, incluyendo:
- Huella TLS: Un examen detallado de los encabezados HTML sirve como el primer paso en el proceso de filtrado. Estos pueden ofrecer pistas sobre si un visitante es malicioso o seguro, humano o bot. Se compara la firma de los encabezados con una base de datos de más de 10 millones de variantes conocidas que se actualiza frecuentemente.
- Reputación de IP: Recolectar información de IP de todos los ataques a nuestros clientes. Las visitas desde direcciones IP que tienen un historial de ser utilizadas en ataques se consideran sospechosas y es más probable que sean sometidas a una inspección adicional.
- Análisis de comportamiento: Monitorear cómo los usuarios interactúan con un sitio web puede revelar patrones de comportamiento inusuales, como tasas de solicitud sospechosamente altas y hábitos de navegación irracionales. Esto facilita la identificación de visitantes que en realidad son bots.
- Desafíos progresivos: Se utilizan desafíos progresivos para filtrar bots y reducir falsos positivos. Estos desafíos incluyen soporte para cookies y ejecución de JavaScript. Un desafío CAPTCHA puede, como último recurso, eliminar bots que intentan hacerse pasar por humanos.
Ejemplos de Web Scraping
Cuando se extraen datos de sitios web sin el consentimiento de los propietarios, la práctica se conoce como web scraping malicioso. El scraping de precios y el robo de contenido son los dos escenarios de uso más típicos.
Scraping de precios: Para escanear conjuntos de datos de negocios competidores, un perpetrador de scraping de precios generalmente lanza bots de scraper desde una botnet. El objetivo es obtener acceso a datos de precios, reducir los precios de los competidores y aumentar las ventas. Los ataques suelen ocurrir en sectores donde los productos son fácilmente comparables y los precios influyen mucho en las compras. Proveedores de viajes, vendedores de entradas y minoristas en línea de electrónica pueden ser víctimas del scraping de precios.
Scraping de contenido: El robo de contenido a gran escala de un sitio web específico se conoce como scraping de contenido. Directorios de productos en línea y sitios web que dependen del contenido digital para generar tráfico son objetivos comunes. Un ataque de scraping de contenido podría ser fatal para estos negocios.
¿Por Qué Python Es Un Lenguaje De Programación Tan Valorado Para El Web Scraping?
¡Hoy en día, Python parece estar de moda! Debido a que puede manejar fácilmente la mayoría de las tareas, es el lenguaje más utilizado para el web scraping. Además, ofrece una serie de bibliotecas diseñadas específicamente para el web scraping. Scrapy, basado en Python, es un framework de código abierto bastante conocido para el rastreo web. Es ideal tanto para la extracción de datos basada en API como para el web scraping. Otro módulo de Python excelente para el web scraping se llama Beautiful Soup. Para extraer datos de HTML en un sitio web, crea un árbol de análisis. Estos árboles de análisis pueden ser navegados, buscados y modificados utilizando diversas capacidades en Beautiful Soup.