La comunidad de código abierto está prosperando, especialmente en estos tiempos en los que la IA está en todas partes y demanda una cantidad cada vez mayor de datos para sus modelos. Esta tendencia ha llevado a un aumento en las actividades de web scraping, pero también ha impulsado el desarrollo de medidas anti-bot más avanzadas. Con esto en mente, permíteme compartir algunas de las bibliotecas de Python más impresionantes para aprovechar la IA en el web scraping y superar las protecciones anti-bot.
Omite la pila de bibliotecas: usa anti-bot bypass con 500 endpoints de biblioteca incluidos.
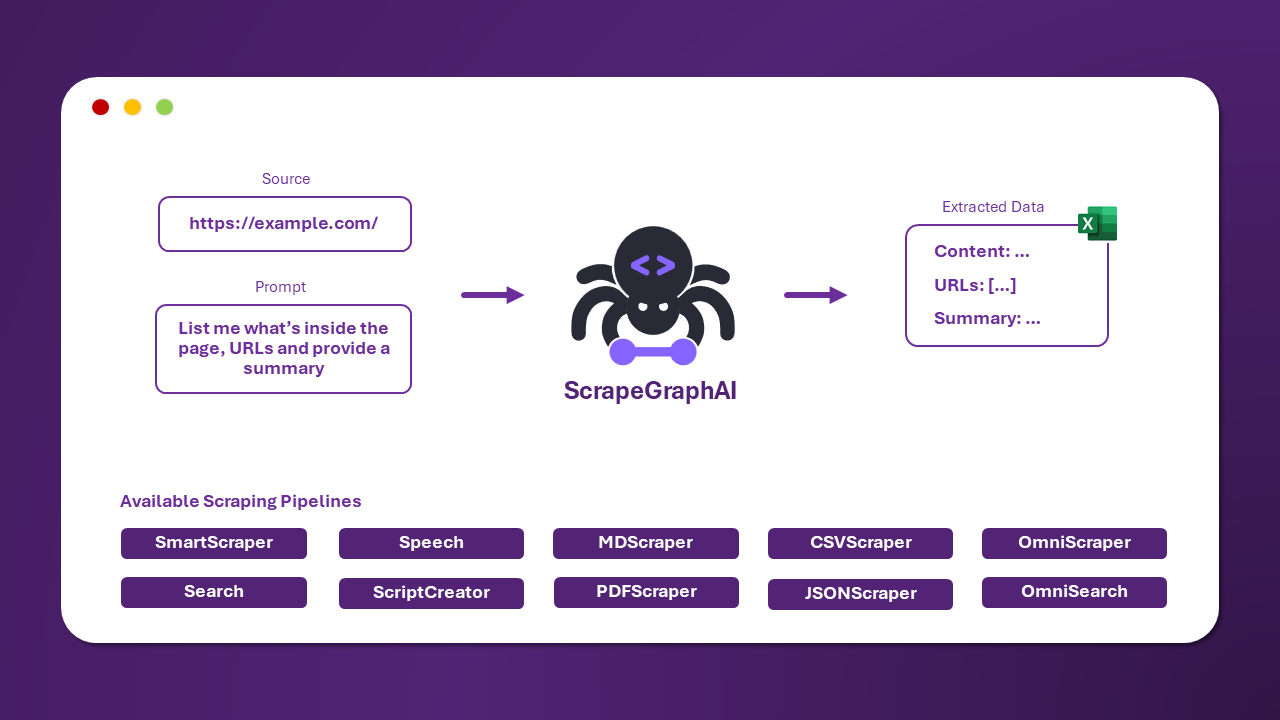
ScrapeGraphAI
Con ScrapeGraphAI, puedes conectar tu LLM preferido (local o en línea) y:
- Extraer datos de una o varias páginas definiendo un esquema de datos objetivo.
- Extraer datos de los resultados de motores de búsqueda.
- Generar archivos de audio a partir de datos extraídos de sitios web.
- Escribir automáticamente código Python para tu scraper utilizando bibliotecas como BeautifulSoup.
Aunque los LLM se están volviendo más asequibles y precisos, sus tiempos de respuesta aún no son ideales para proyectos de web scraping a nivel de producción. El mejor uso de esta tecnología en el web scraping, en mi opinión, es para escribir y corregir automáticamente el código del scraper, dejando la ejecución a los frameworks actuales. También están trabajando en la extracción de datos de documentos locales, lo cual estoy emocionado de ver. Puedes seguir su progreso uniéndote a su servidor de Discord.
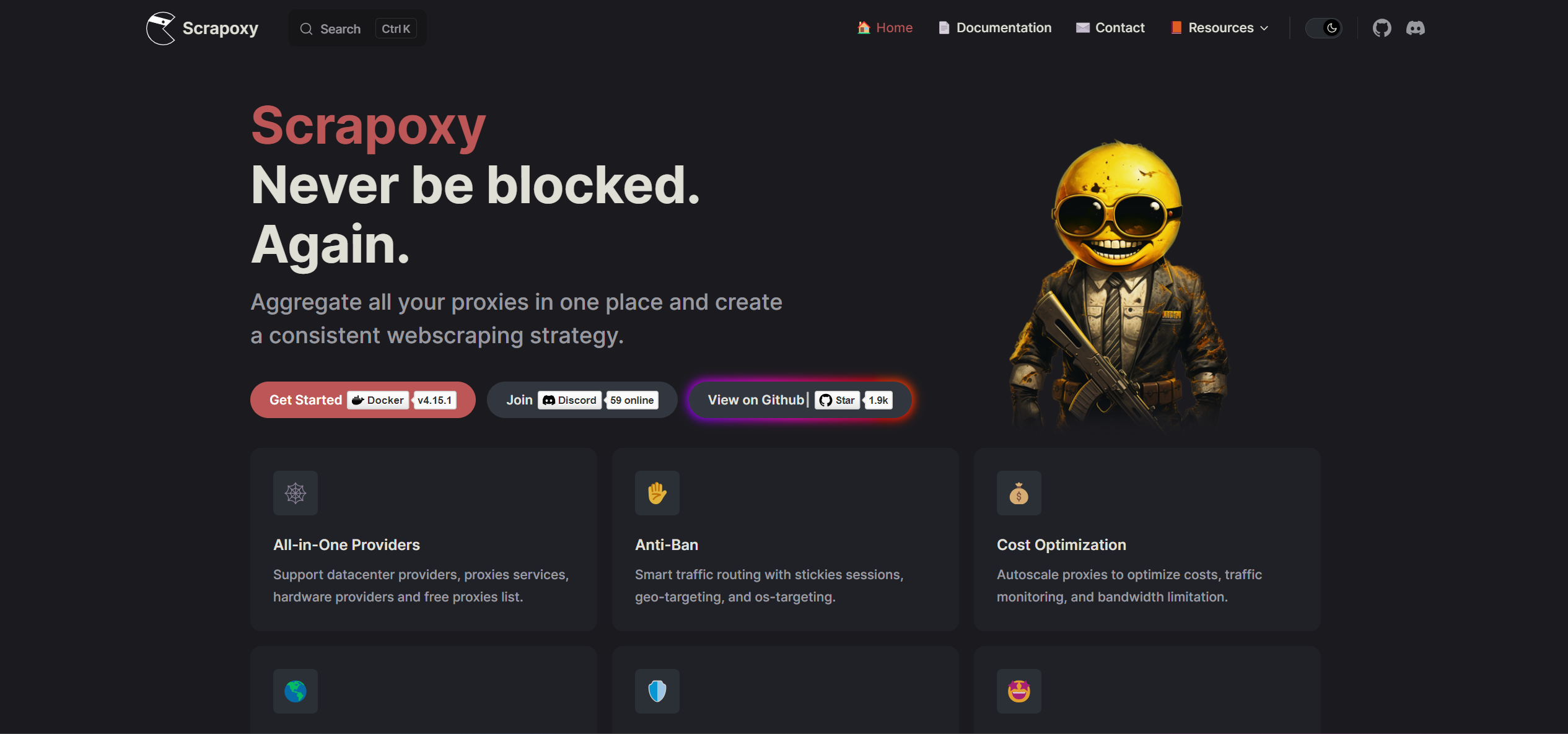
Scrapoxy
Es posible que reconozcas a Fabien Vauchelles, el creador de Scrapoxy, por sus perspicaces charlas sobre bots y tecnologías anti-bot en varios eventos y seminarios web de web scraping. Scrapoxy es un potente agregador de proxies que te permite gestionar proxies de diversos proveedores, tanto gratuitos como comerciales.
Lo que distingue a Scrapoxy es su innovadora gestión de proxies de centros de datos. Al crear y rotar máquinas virtuales en diferentes proveedores de la nube, Scrapoxy te permite construir un grupo casi infinito de IPs con ancho de banda ilimitado. Además, no se limita solo a esta funcionalidad; al usar un único endpoint en tus scrapers, puedes mezclar diferentes proveedores y tipos de proxy, mejorando aún más tus capacidades de scraping.
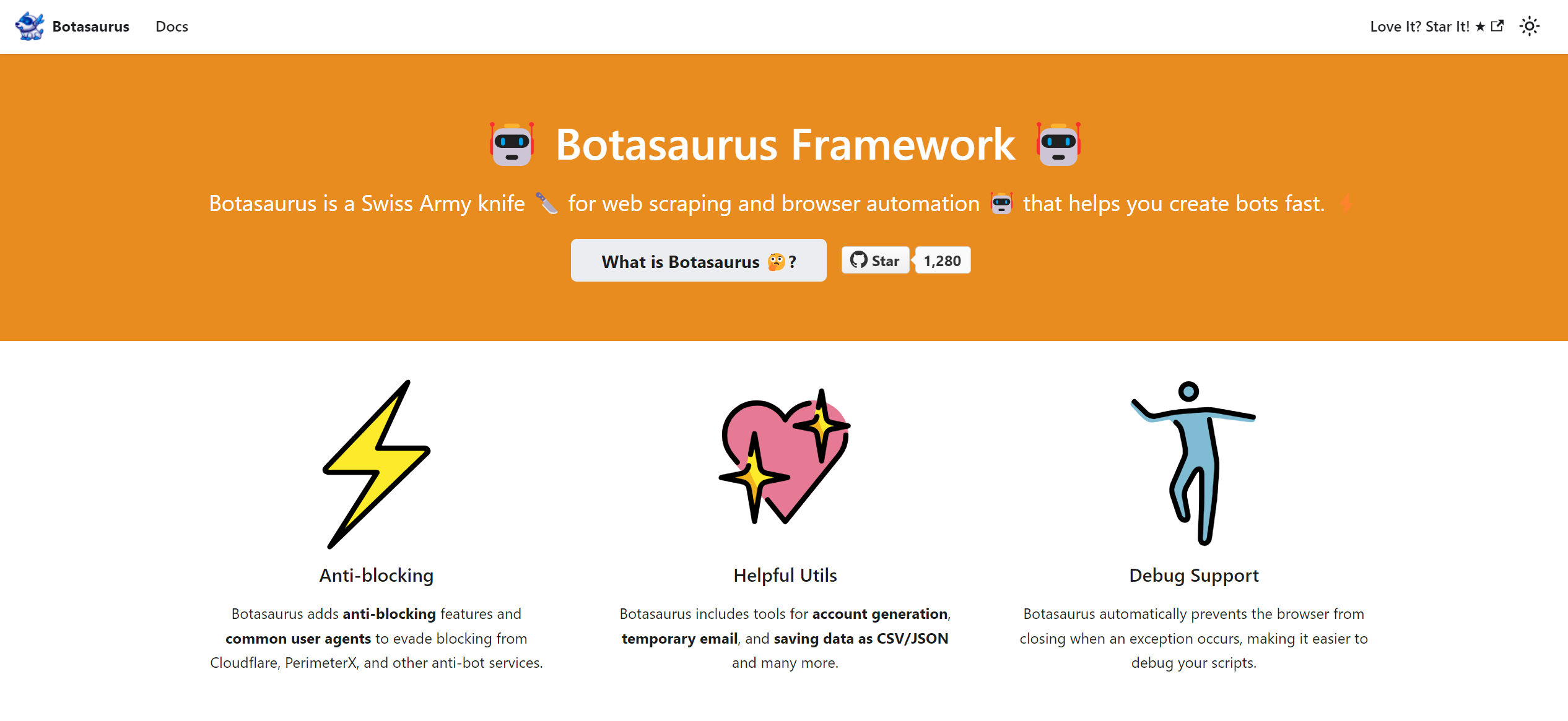
Botasaurus
Botasaurus es otro framework robusto que vale la pena explorar. Admite la creación de scrapers tanto headless como headful. Durante mis pruebas iniciales hace unos meses, Botasaurus demostró su capacidad para eludir la detección de Cloudflare y otros sistemas anti-bot, aunque tiene algunas limitaciones.
Cuando se ejecuta un scraper headful desde un centro de datos, Botasaurus actualmente carece de opciones avanzadas para enmascarar la huella digital de tu navegador, lo que puede llevar a bloqueos. A pesar de esto, es una herramienta a tener en cuenta.
Nodriver
Nodriver es el sucesor de Undetected-Chromedriver, eliminando la necesidad de Selenium y webdrivers. Es completamente asíncrono, ofreciendo una herramienta rápida para el scraping que está optimizada de forma nativa para pasar desapercibida por la mayoría de las soluciones anti-bot, todo con solo unas pocas líneas de código. También puedes gestionar diferentes perfiles, proporcionando todo lo que necesitas para tus scrapers. Además, incluye utilidades para la búsqueda inteligente de elementos, gestión de sesiones e integración perfecta con instancias existentes de undetected_chromedriver, convirtiéndolo en una herramienta versátil y potente para tareas web automatizadas.
Undetected Playwright
Undetected Playwright es un parche que puedes aplicar a tus scrapers de Playwright para mejorar su indetectabilidad frente a sistemas anti-bot. Hemos visto este parche en acción en un artículo sobre técnicas de detección de CDP, donde mejoró significativamente el rendimiento de nuestros scrapers para eludir estos métodos anti-bot cada vez más comunes.
Camoufox
Camoufox es un navegador actualmente en desarrollo que fue compartido recientemente en nuestro servidor de Discord por su autor. Parece muy prometedor. Construido sobre Firefox, el autor eliminó características innecesarias y añadió enmascaramiento TLS, Browserforge para alterar la huella digital del navegador y varias otras características. Las pruebas realizadas en sitios web conocidos como Browserscan parecen prometedoras, y estoy ansioso por probarlo.