Aprenda a hacer scraping en Amazon utilizando encabezados User-Agent para evitar la detección y BeautifulSoup para analizar el contenido HTML. Esta guía completa también incluye un ejemplo de caso de uso completo que demuestra el proceso de extracción de información de productos, como títulos, precios y calificaciones, utilizando Python.
Evite el mantenimiento: use la Amazon Scraping API o la Amazon Product API para obtener resultados estructurados en JSON.
Introducción al web scraping
¿Qué es el Web Scraping?
El web scraping es un método utilizado para extraer automáticamente grandes cantidades de contenido de sitios web. El objetivo principal del web scraping es recopilar y estructurar información de la web, que luego puede ser utilizada para diversas aplicaciones. Este contenido puede incluir texto, imágenes, videos y otras formas de medios disponibles en las páginas web. Al automatizar el proceso de extracción, el web scraping permite a los usuarios leer, buscar y analizar rápidamente el contenido web, ahorrando tiempo y esfuerzo significativo en comparación con la recopilación manual de datos.
Herramientas y técnicas
Se emplean varias herramientas y técnicas en el web scraping para garantizar una recopilación eficiente de datos:
- Análisis de HTML: Esta técnica implica analizar la estructura de una página web para recopilar información. Herramientas como un scraper de Python y Cheerio (JavaScript) son comúnmente utilizadas para este propósito. Permiten navegar por la estructura de la página y recuperar detalles relevantes basados en etiquetas, atributos y otros elementos.
- Análisis de DOM: El análisis del Modelo de Objetos del Documento (DOM) implica interactuar con la estructura del DOM de una página web para recopilar datos. Bibliotecas de JavaScript como jQuery facilitan este proceso al permitir la manipulación y consulta del DOM para recuperar información específica.
- Uso de Proxy: Muchos sitios web implementan medidas para limitar el acceso basado en direcciones IP. Al utilizar proxies, se pueden evitar estas restricciones y acceder a las URLs necesarias sin ser bloqueado. Este método suele ser más confiable y eficiente.
- Navegadores sin cabeza: Herramientas como Puppeteer y Selenium simulan interacciones con páginas web al renderizarlas en un navegador sin cabeza. Este enfoque permite navegar por páginas web complejas, manejar la ejecución de JavaScript y recopilar datos como si se navegara manualmente.
- Expresiones Regulares: Las expresiones regulares (regex) pueden utilizarse para identificar patrones en el contenido de la página web y recopilar información en consecuencia. Esta técnica es útil para tareas específicas donde el contenido sigue un patrón predecible.
Descargo de responsabilidad legal y precauciones
Este tutorial cubre técnicas populares de web scraping con fines educativos. Interactuar con servidores públicos requiere diligencia y respeto, y aquí hay un buen resumen de lo que no se debe hacer:
- No haga scraping a tasas que puedan dañar el sitio web.
- No haga scraping de reseñas o texto que no esté disponible públicamente.
- No almacene información personal identificable (PII) de ciudadanos de la UE protegidos por el GDPR.
- No reutilice conjuntos de datos públicos completos, ya que esto puede ser ilegal en algunos países.
Cuando busque o lea contenido, asegúrese de seguir pautas éticas y consideraciones legales. Para una orientación más detallada, debe consultar a un abogado.
¿Por qué hacer scraping de productos de Amazon?
Hacer scraping de Amazon ofrece varios beneficios significativos para empresas, investigadores e individuos:
- Análisis Competitivo: Al usar un scraper para recopilar información de Amazon, las empresas pueden leer descripciones de competidores, reseñas de clientes y rastrear la disponibilidad de artículos. Esto ayudará a desarrollar estrategias competitivas y ajustar sus propias ofertas para mantenerse a la vanguardia en el mercado.
- Investigación de Mercado: Hacer scraping de Amazon permite a las empresas buscar tendencias de consumo, preferencias y comportamientos de compra. Esta información ayuda a identificar artículos populares, entender las necesidades de los clientes y tomar decisiones informadas sobre desarrollo y estrategias de marketing.
- Monitoreo de Precios: Los minoristas y consumidores pueden usar el scraping para rastrear cambios a lo largo del tiempo. Esto es particularmente útil para estrategias dinámicas de precios, donde las empresas pueden ajustar los valores en función de la actividad de los competidores y la demanda del mercado.
- Agregación de Datos: Las empresas que venden en múltiples plataformas pueden usar un scraper para agregar su contenido, asegurando la consistencia en todos los canales. Esto ayuda a mantener listados precisos, gestionar el inventario y optimizar las operaciones.
- Análisis de Sentimiento del Cliente: Al analizar las reseñas y calificaciones de los clientes, las empresas pueden obtener información sobre la satisfacción y el rendimiento del producto. Esta información puede utilizarse para mejorar las ofertas, abordar problemas comunes y mejorar el servicio al cliente.
- Generación de Leads: Hacer scraping de Amazon puede ayudar a identificar posibles leads y oportunidades para asociaciones o ventas. Por ejemplo, las empresas pueden buscar revendedores, proveedores o influencers que estén activos en su industria.
En general, la capacidad de leer y hacer scraping de datos de Amazon es un recurso valioso que ayudará en la toma de decisiones estratégicas y mejorará la eficiencia operativa.
Construyendo un scraper básico de Amazon
Usando requests para obtener URLs de Amazon
Configurando el user-agent
Al hacer scraping de sitios web, es importante configurar un User-Agent para imitar una solicitud de navegador real. Esto ayuda a evitar bloqueos y obtener la respuesta correcta del servidor. En Python, puede usar la biblioteca requests para configurar un User-Agent. Aquí tiene un ejemplo:
import requests
import random
# Lista de user-agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 10; SM-G960F)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Mobile Safari/537.36'
]
# Elegir un user-agent aleatorio
headers = {
'User-Agent': random.choice(user_agents)
}
url = 'https://www.amazon.com/dp/B0B72B7GM2' # URL de producto de ejemplo
# Hacer una solicitud GET a la URL especificada con los encabezados elegidos
response = requests.get(url, headers=headers)
# Imprimir el código de estado de la respuesta
print(response.status_code)
En este ejemplo, la cadena User-Agent se configura para imitar un navegador web común, lo que hace menos probable que la solicitud sea bloqueada por los servidores de Amazon.
Recuperando contenido HTML
Una vez realizada la solicitud, el siguiente paso es recuperar el contenido de la página web. Esto se puede hacer utilizando el objeto de respuesta obtenido de la llamada requests.get. Así es como puede recuperar e imprimir el contenido:
if response.status_code == 200:
html_content = response.text
print(html_content)
else:
print(f"No se pudo recuperar la página web. Código de estado: {response.status_code}")
Este código verifica si la solicitud fue exitosa (código de estado 200) y luego recupera el contenido HTML como una cadena de texto.
Analizando HTML con BeautifulSoup
¿Qué es BeautifulSoup?
BeautifulSoup es una popular biblioteca de Python diseñada para el web scraping y el análisis de documentos XML. Permite a un scraper navegar y manipular fácilmente la estructura de una página web, simplificando la extracción de contenido. BeautifulSoup tomará el código fuente de la página y construirá un árbol de análisis, que luego se puede buscar y modificar para extraer texto o información relevante. Es especialmente útil para hacer scraping de marcado mal formateado o inconsistente. Al usar BeautifulSoup en Python, los desarrolladores pueden extraer contenido de manera eficiente de sitios web, automatizando el proceso de recopilación y organización de información de la web, convirtiéndolo en una herramienta poderosa para cualquier scraper.
¿Por qué usar BeautifulSoup?
BeautifulSoup está compuesto por diferentes herramientas de análisis como soup, lxml y HTML5lib. Esta flexibilidad le permite probar varios métodos de análisis y beneficiarse de sus ventajas según la situación. Una de las principales razones para usar BeautifulSoup es su facilidad de uso. Solo se necesitan unas pocas líneas en Python para crear un scraper que pueda extraer contenido de manera eficiente de las páginas web. A pesar de su simplicidad, es robusto y confiable, lo que lo convierte en una opción popular no solo para desarrolladores, sino también para aquellos que trabajan con web scraping en general.
Con su documentación clara y completa, BeautifulSoup ayudará a los scrapers a aprender rápidamente y resolver problemas de manera efectiva. Además, una comunidad en línea activa ofrece diversas soluciones a los desafíos que pueda enfrentar al hacer scraping, convirtiéndolo en una gran herramienta tanto para principiantes como para expertos.
Encontrando el título y precio del producto
Para analizar el contenido HTML y extraer información específica como el título del producto y el valor, puede usar la biblioteca Beautiful Soup.
BeautifulSoup es una biblioteca poderosa y fácil de usar de Python para extraer datos de archivos HTML y XML, permitiendo a los usuarios navegar, buscar y modificar el contenido de la página web de manera eficiente, todo mientras disfrutan de la simplicidad de estas herramientas de análisis de 'sopa'.
Aquí tiene un ejemplo de cómo extraer estos detalles:
Examinemos la estructura de la página de detalles del producto.
Abra una URL de producto, como https://www.amazon.com/dp/B0B72B7GM2, en Chrome o cualquier otro navegador moderno, haga clic derecho en el título del producto y seleccione Inspeccionar.
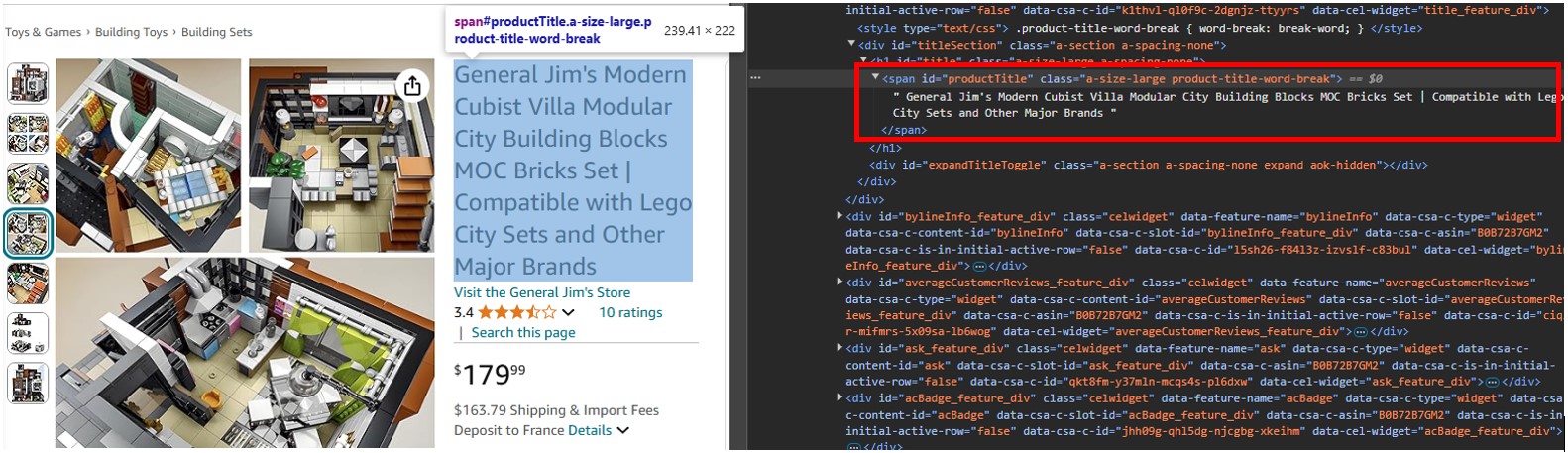
Verá que es una etiqueta span con su atributo id establecido en "productTitle". De manera similar, si hace clic derecho en el elemento y selecciona Inspeccionar, verá el marcado del contenido, que el scraper leerá y le permitirá buscar detalles específicos.
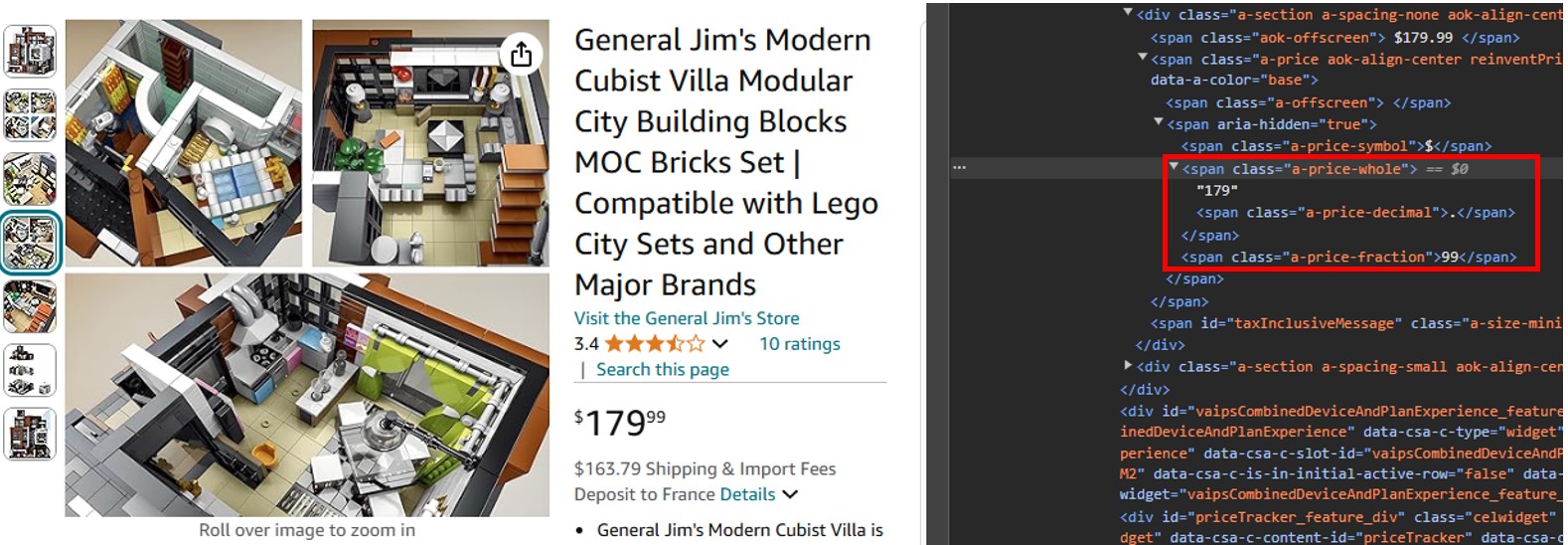
Puede ver que el componente en dólares del precio está en una etiqueta span con la clase "a-price-whole", y el componente en centavos está en otra etiqueta span con la clase establecida en "a-price-fraction".
De manera similar, puede localizar la calificación, la imagen y la descripción.
Una vez que tenga esta información, podemos configurar nuestro código con beautiful soup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Encontrando el título
title_tag = soup.find('span', {'id': 'productTitle'})
product_title = title_tag.get_text(strip=True) if title_tag else 'Título no encontrado'
price_tag = soup.find('span', {'class': 'a-offscreen'})
product_price = price_tag.get_text(strip=True) if price_tag else 'Precio no encontrado'
print(f"Título: {product_title}")
print(f"Precio: {product_price}")
En este ejemplo, BeautifulSoup se utiliza para analizar el contenido HTML y encontrar las etiquetas que contienen el título y el precio del producto. El método get_text(strip=True) se utiliza para extraer el contenido de texto y eliminar cualquier espacio en blanco inicial o final.
Extrayendo reseñas y calificaciones de clientes
Para extraer reseñas y calificaciones de clientes, debe encontrar las etiquetas y clases HTML relevantes. Aquí tiene un ejemplo:
# Encontrando reseñas de clientes
reviews = []
review_tags = soup.find_all('span', {'data-hook': 'review-body'})
for tag in review_tags:
review_text = tag.get_text(strip=True)
reviews.append(review_text)
# Encontrando calificaciones de clientes
ratings = []
rating_tags = soup.find_all('i', {'data-hook': 'review-star-rating'})
for tag in rating_tags:
rating_text = tag.get_text(strip=True)
ratings.append(rating_text)
print(f"Reseñas de clientes: {reviews}")
print(f"Calificaciones de clientes: {ratings}")
En este código, find_all se utiliza para localizar todas las instancias de los cuerpos de reseñas y calificaciones. El contenido de texto de cada reseña y calificación se extrae y almacena en listas.
Al combinar estos pasos, puede construir un scraper básico de Amazon que obtenga detalles del producto, reseñas y calificaciones de clientes. Recuerde manejar los errores y respetar los términos de servicio de Amazon para evitar posibles problemas legales.
Revisión del script final
Para hacer scraping de páginas de productos de Amazon, utilizaremos la biblioteca requests de Python para obtener URLs y BeautifulSoup para analizar el contenido HTML. Aquí está el script consolidado final que demuestra estos procesos:
import requests
import random
from bs4 import BeautifulSoup
# Lista de user-agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 10; SM-G960F)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Mobile Safari/537.36'
]
# Elegir un user-agent aleatorio
headers = {
'User-Agent': random.choice(user_agents)
}
# URL de producto de ejemplo
url = 'https://www.amazon.com/dp/B0B72B7GM2'
# Hacer una solicitud GET a la URL especificada con los encabezados elegidos
response = requests.get(url, headers=headers)
# Verificar si la solicitud fue exitosa
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
# Encontrando el título
title_tag = soup.find('span', {'id': 'productTitle'})
product_title = title_tag.get_text(strip=True) if title_tag else 'Título no encontrado'
# Encontrando el precio
price_tag = soup.find('span', {'class': 'a-offscreen'})
product_price = price_tag.get_text(strip=True) if price_tag else 'Precio no encontrado'
# Encontrando reseñas de clientes
reviews = []
review_tags = soup.find_all('span', {'data-hook': 'review-body'})
for tag in review_tags:
review_text = tag.get_text(strip=True)
reviews.append(review_text)
# Encontrando calificaciones de clientes
ratings = []
rating_tags = soup.find_all('i', {'data-hook': 'review-star-rating'})
for tag in rating_tags:
rating_text = tag.get_text(strip=True)
ratings.append(rating_text)
print(f"Título: {product_title}")
print(f"Precio: {product_price}")
print(f"Reseñas de clientes: {reviews}")
print(f"Calificaciones de clientes: {ratings}")
else:
print(f"No se pudo recuperar la página web. Código de estado: {response.status_code}")

Técnicas avanzadas en el scraping de Amazon
En este capítulo, exploraremos técnicas avanzadas para hacer scraping en Amazon. Estas herramientas poderosas, que utilizan Python, se especializan en la recuperación de datos de URLs, ahorrando tiempo y dinero mientras hacen que el web scraping sea accesible para todos.
¿Por qué usar un software de web scraping?
La capacidad de hacer scraping, recopilar y analizar contenido de Internet utilizando un scraper se ha convertido en una habilidad crucial para empresas e investigadores por igual. Aquí es donde el software de web scraping, particularmente con Python, marcará una diferencia significativa en su capacidad para buscar y recuperar información relevante.
Riesgo reducido de detección y bloqueo
Uno de los desafíos al construir un scraper personalizado es el riesgo de ser detectado y bloqueado por los sitios web. Los sitios web a menudo tienen medidas de seguridad en su lugar, como la limitación de tasas o el bloqueo de IP, para prevenir el scraping. Sin embargo, el uso de software de web scraping experto con Python reduce significativamente el riesgo de detección. Estas herramientas están diseñadas para manejar mecanismos sofisticados anti-scraping, como la rotación de IP, imitando comportamientos similares a los humanos y gestionando intervalos de solicitud para evitar activar los sistemas de seguridad.
Acceso a grandes volúmenes de datos
Internet es un tesoro de información, pero hacer scraping manual de sitios web puede ser lento e impráctico. Un scraper que utiliza Python automatiza este proceso, permitiendo a los usuarios hacer scraping de grandes volúmenes de contenido de manera rápida y eficiente. Ya sea para investigación de mercado, análisis competitivo o estudios académicos, el web scraping recopilará información que de otra manera tomaría días o semanas compilar manualmente.
Escalabilidad
A medida que las empresas crecen, también lo hace su necesidad de hacer scraping de más información. Un scraper que utiliza Python es altamente escalable, capaz de manejar cantidades crecientes de contenido sin pérdida de rendimiento. Esta escalabilidad hace que el web scraping sea una solución ideal para empresas de todos los tamaños, desde startups hasta grandes empresas.
¿Por qué usar la API de Piloterr para el scraping de Amazon?
El scraper de Piloterr destaca como una herramienta poderosa para hacer scraping de datos de productos de Amazon. Aquí hay varias razones por las que debería considerar usar la solución de Piloterr para sus necesidades de scraping de Amazon:
- Proxy Privado: Piloterr utiliza sus propios proxies privados, asegurando que sus solicitudes se distribuyan a través de múltiples direcciones IP (rotación de IP). Esto reducirá significativamente la probabilidad de ser bloqueado por Amazon y le permitirá hacer scraping de datos de manera eficiente y efectiva. Nuestra infraestructura robusta está construida con Python y diseñada para manejar altos volúmenes de solicitudes mientras mantiene una alta tasa de éxito.
- Acceso Integral a la Biblioteca con una Sola Suscripción: Una de las razones más convincentes para elegir Piloterr es el valor ofrecido por nuestro modelo de suscripción. Con una sola suscripción, obtendrá acceso a nuestros endpoints de API library y recursos de scraping. Esto incluye no solo el scraper de Amazon, sino también otras soluciones de scraping para varios sitios web y fuentes de datos. Este acceso integral asegura que tenga las herramientas que necesita para cualquier proyecto de scraping, todo en un solo lugar.
Con Piloterr, puede buscar, leer y recuperar fácilmente la información necesaria de Amazon y otras plataformas, dándole una poderosa ventaja en sus esfuerzos de recopilación de datos.
Cree su cuenta
- Regístrese en piloterr.com
- Cree su suscripción (50 créditos gratuitos al registrarse)
- Cree y copie su clave API
Estudio de caso: hacer scraping de Amazon
Aquí tiene un ejemplo práctico de cómo usar Python para hacer scraping del título y otros detalles relevantes de un artículo de Amazon desde su URL. Se utilizará un scraper para recuperar la información necesaria de manera eficiente.
Código básico en Python
No olvide reemplazar PILOTERR_API_KEY con su clave API real. El script asume que las respuestas de la API de Piloterr están en un formato específico de nuestra API, por lo que puede necesitar ajustes dependiendo del proveedor que elija.
- Copie el código
- Cree un nuevo archivo
get_amazon_product.py - Reemplace el token de API con el suyo
- Reemplace las variables
JOB_TITLEyLOCATIONsegún sus necesidades - Ejecute el script con
python get_amazon_product.py
import requests
PILOTERR_API_KEY = 'YOUR-API-KEY-HERE'
LIST_ASIN_AMAZON_PRODUCT = [
"B0CN78FNTY",
"B09JGLMDLZ",
"B09VZ3ZQWQ",
"B0B72B7GM2"
]
def get_amazon_product_info(url: str):
amazon_api_url = "https://piloterr.com/api/v2/amazon/product"
headers = {
"x-api-key": PILOTERR_API_KEY
}
data = {
"query": url,
"domain": "com"
}
response = requests.get(
url=amazon_api_url,
headers=headers,
params=data # Usando params en lugar de json para solicitud GET
)
if response.status_code == 200:
return response.json()
else:
print(f"Error: No se pudo realizar la búsqueda. Código de estado: {response.status_code}")
return None
def extract_product_data(json_data):
product_data = {
"url": json_data.get("url"),
"asin": json_data.get("asin"),
"price": json_data.get("price"),
"stock": json_data.get("stock"),
"title": json_data.get("title")
}
return product_data
def process_amazon_products(url_list):
all_product_data = []
for url in url_list:
product_info = get_amazon_product_info(url)
if product_info:
extracted_data = extract_product_data(product_info)
all_product_data.append(extracted_data)
return all_product_data
# Uso
if __name__ == "__main__":
products_data = process_amazon_products(LIST_ASIN_AMAZON_PRODUCT)
print(products_data)
Explicación en Python
- Imports: El código importa la biblioteca
requestspara hacer solicitudes HTTP. - Clave API y Lista de Productos: Define una constante
PILOTERR_API_KEYpara la autenticación de la API y una listaLIST_ASIN_AMAZON_PRODUCTque contiene ASINs (Números de Identificación Estándar de Amazon) de productos a consultar. - Función
get_amazon_product_info(url: str):- Construye una solicitud a la API de Piloterr para recuperar información del producto.
- Establece los encabezados de la solicitud con la clave API y parámetros para la búsqueda del producto.
- Si el código de estado de la respuesta es 200 (OK), devuelve los datos JSON; de lo contrario, imprime un mensaje de error.
- Función
extract_product_data(json_data):- Extrae campos específicos (
url,asin,price,stockytitle) de los datos JSON devueltos por la API y los devuelve en un diccionario.
- Extrae campos específicos (
- Función
process_amazon_products(url_list):- Itera sobre una lista de URLs de productos (ASINs), recupera la información del producto utilizando
get_amazon_product_infoy extrae los datos relevantes utilizandoextract_product_data. - Compila todos los datos de productos extraídos en una lista y la devuelve.
- Itera sobre una lista de URLs de productos (ASINs), recupera la información del producto utilizando
Otros casos de uso
- Recuperar Artículos Más Vendidos: Use la API para recopilar datos sobre los productos más vendidos en una categoría específica o en general. Esto podría ayudar a identificar artículos en tendencia basados en el rendimiento de ventas.
- Analizar Estrellas: Haga scraping de información del producto, incluyendo calificaciones por estrellas. Esto permite a los usuarios filtrar productos basados en la satisfacción del cliente y encontrar artículos altamente calificados.
- Extraer Imágenes de Productos: Recupere imágenes de alta calidad de los artículos para usarlas en sitios web de comercio electrónico o plataformas de comparación. Esto mejora el atractivo visual de los listados y ayuda a los clientes a tomar decisiones informadas.
- Construir un Agregador de Reseñas: Compile reseñas y calificaciones de clientes para los mejores artículos en un nicho específico. Esto puede ayudar a los consumidores a tomar decisiones basadas en comentarios exhaustivos de otros compradores.
Precauciones para el scraping en Amazon
Al hacer scraping en Amazon, es crucial recordar que los selectores CSS (elem.css()) pueden cambiar con el tiempo ya que los desarrolladores de Amazon actualizan frecuentemente el CSS del sitio web. Estas actualizaciones pueden alterar la estructura, haciendo que sus selectores CSS existentes fallen. Para reducir el mantenimiento, elija cuidadosamente los selectores para su elemento (elem), priorizando elementos <div> con atributos estables, como id. Al apuntar a elementos con atributos id específicos, mejora la resiliencia de su script de scraping frente a cambios en el CSS.
Conclusión
Piloterr es una de las mejores formas de hacer scraping de artículos de Amazon de manera simple y eficiente utilizando nuestro scraper de Python. Al integrar esta solución en su flujo de trabajo, optimizará su proceso, eliminando la necesidad de gestionar agentes o direcciones IP, ya que todo pasa a través de nuestros proxies. Ya sea que esté haciendo scraping de datos de URLs para análisis de mercado, investigación de competidores u otros propósitos, Piloterr le permitirá buscar, leer y recuperar fácilmente la información que necesita. Es una herramienta valiosa para agregar a su caja de herramientas de web scraping.