Jeder versucht, in dem intensiven Wettbewerb von heute neue Technologien zu entwickeln und zu nutzen. Der Vorgang des automatischen Herunterladens von Daten von Websites auf Ihren Computer oder in Ihre Datenbank wird als Web-Scraping bezeichnet. Web-Scraping wird oft auch als Datenextraktion oder Web-Datenextraktion bezeichnet. Web-Scraping ist eine computergestützte Methode zum Sammeln großer Mengen an Daten von Websites. Die meisten dieser Daten liegen in unstrukturiertem HTML-Format vor und werden in strukturierte Informationen in einer Datenbank oder Tabelle umgewandelt, damit sie für verschiedene Funktionen genutzt werden können. Web-Scraping kann mit einer Reihe von Techniken durchgeführt werden, um Daten von Websites zu sammeln. Dazu gehören die Nutzung spezifischer APIs, Online-Dienste oder sogar das Schreiben Ihres eigenen Codes von Grund auf für Web-Scraping. Sie können auf die strukturierten Daten vieler großer Websites wie Google, Twitter, Facebook, StackOverflow und anderen über deren APIs zugreifen. Obwohl dies die beste Wahl ist, gibt es andere Websites, die entweder nicht über das gleiche technologische Niveau verfügen oder Nutzern keinen Zugriff auf große Mengen strukturierter Daten erlauben. In diesem Fall ist es besser, Web-Scraping einzusetzen, um Daten von der Website zu sammeln.
Die beiden für Web-Scraping benötigten Werkzeuge sind der Scraper und der Crawler. Der Crawler ist ein künstlich intelligentes System, das auf Links klickt, um im Internet nach den benötigten Informationen zu suchen. Im Gegensatz dazu ist ein Scraper ein spezielles Werkzeug, das zum Extrahieren von Daten von der Website entwickelt wurde. Je nach Umfang und Komplexität des Projekts kann die Architektur des Scrapers stark variieren, um die Daten effizient und präzise abzurufen.
Anwendungen von Web-Scraping
Die beliebtesten Anwendungen von Web-Scraping sind folgende:
- Lead-Generierung für Marketing : Für Marketingzwecke können Leads mit einem Web-Scraping-Tool generiert werden. Durch das Scrapen von Informationen von relevanten Websites können E-Mail- und Telefonlisten für Cold Outreach erstellt werden. Beispielsweise können Daten von Websites, die Gelbe-Seiten-Einträge oder Google Maps-Geschäftseinträge anbieten, genutzt werden, um die Telefonnummer und E-Mail-Adresse eines Unternehmens zu extrahieren.
- Preisbewertung und Wettbewerbsbeobachtung : Unternehmen, die Waren oder Dienstleistungen anbieten, müssen detaillierte Informationen über die konkurrierenden Produkte und Dienstleistungen haben, die ständig auf den Markt kommen. Diese Daten können regelmäßig mit einem Web-Scraping-Tool überwacht werden.
- E-Commerce : Mit Hilfe von Web-Scraping können häufig Produktdaten von verschiedenen E-Commerce-Websites wie Amazon, eBay, Google Shopping usw. extrahiert werden. Ein Web-Scraping-Tool macht es einfach, Produktdetails wie Preise, Beschreibungen, Bilder, Bewertungen und Bewertungen abzurufen.
- Immobilien : Ein Web-Scraping-Tool kann verwendet werden, um die auf Immobilien-Websites wie Zillow, Realtor und anderen veröffentlichten Immobilien-Details abzurufen. Neben Immobilien-Daten kann Web-Scraping auch genutzt werden, um Kontaktinformationen von Eigentümern und Maklern zu sammeln.
- Datenanalyse : Der durchschnittliche Nutzer möchte möglicherweise Daten zu einer bestimmten Kategorie von anderen Websites sammeln und analysieren. Diese Kategorie umfasst Dinge wie Immobilien, Autos, Elektronik, Geschäftskontakte sowie Marketing. Die verschiedenen Websites, die unter die gegebene Kategorie fallen, präsentieren Informationen auf unterschiedliche Weise. Selbst bei einer einzelnen Website können Sie möglicherweise nicht alle Informationen auf einmal sehen. Die Informationen können auf mehrere Seiten verteilt sein (ähnlich wie die paginierten Listen in den Google-Suchergebnissen) und in verschiedene Abschnitte unterteilt sein.
- Akademische Auswertung : Jede Forschung, ob akademisch, marketingbezogen oder wissenschaftlich, benötigt Daten. Mit Hilfe eines Web-Scrapers können Sie leicht strukturierte Daten aus zahlreichen Quellen im Internet sammeln.
- Daten für das Training und Testen von Machine-Learning-Projekten : Mit Web-Scraping können Sie Daten für das Testen und Trainieren von Machine-Learning-Modellen sammeln. Die Genauigkeit der Trainingsdaten, die Sie verwenden, bestimmt die Leistung Ihrer Machine-Learning-Modelle. Wenn die Trainingsdaten nicht leicht verfügbar sind, können Sie Web-Scraping nutzen, um sie aus verschiedenen Quellen zu sammeln.
- Analyse von Sportwetten-Quoten : Verschiedene Buchmacher nutzen Web-Scraping, um Wettquoten von Sportwetten-Websites wie OddsPortal, BetExplorer, FlashScore usw. zu sammeln.
- Sentiment-Analyse : Sentiment-Analyse ist entscheidend, wenn Unternehmen verstehen möchten, wie Kunden allgemein über ihre Produkte denken. Web-Scraping ist eine Methode, die Unternehmen nutzen, um Daten von Social-Media-Plattformen wie Facebook und Twitter über die allgemeinen Wahrnehmungen der Menschen zu ihren Produkten zu sammeln. Dadurch können sie ihre Konkurrenten übertreffen und Produkte entwickeln, die die Menschen wollen.
Wie funktionieren Web-Scraper?
Web-Scraper sind in der Lage, alle Informationen von bestimmten Websites oder die spezifischen Informationen, die ein Benutzer anfordert, zu sammeln. Dies ist die ideale Situation, um sicherzustellen, dass nur die benötigten Daten schnell vom Web-Scraper extrahiert werden. Beispielsweise möchten Sie möglicherweise eine Amazon-Website scrapen, um herauszufinden, welche Arten von Entsaftern angeboten werden, benötigen aber möglicherweise nur Informationen über die Modelle der verschiedenen Entsafter und nicht die Kundenbewertungen.
Daher werden zunächst die URLs bereitgestellt, wenn ein Web-Scraper eine Website scrapen muss. Anschließend wird der gesamte HTML-Code der Websites geladen. Ein fortschrittlicherer Scraper könnte auch alle CSS- und JavaScript-Elemente extrahieren. Nach dem Extrahieren der benötigten Daten aus dem HTML-Code gibt der Scraper diese in der vom Benutzer gewählten Form aus. Meistens erfolgt dies in Form einer Excel-Tabelle oder einer CSV-Datei, aber die Informationen können auch in anderen Formaten wie einer JSON-Datei gespeichert werden.
Wie funktioniert manuelles Web-Scraping?
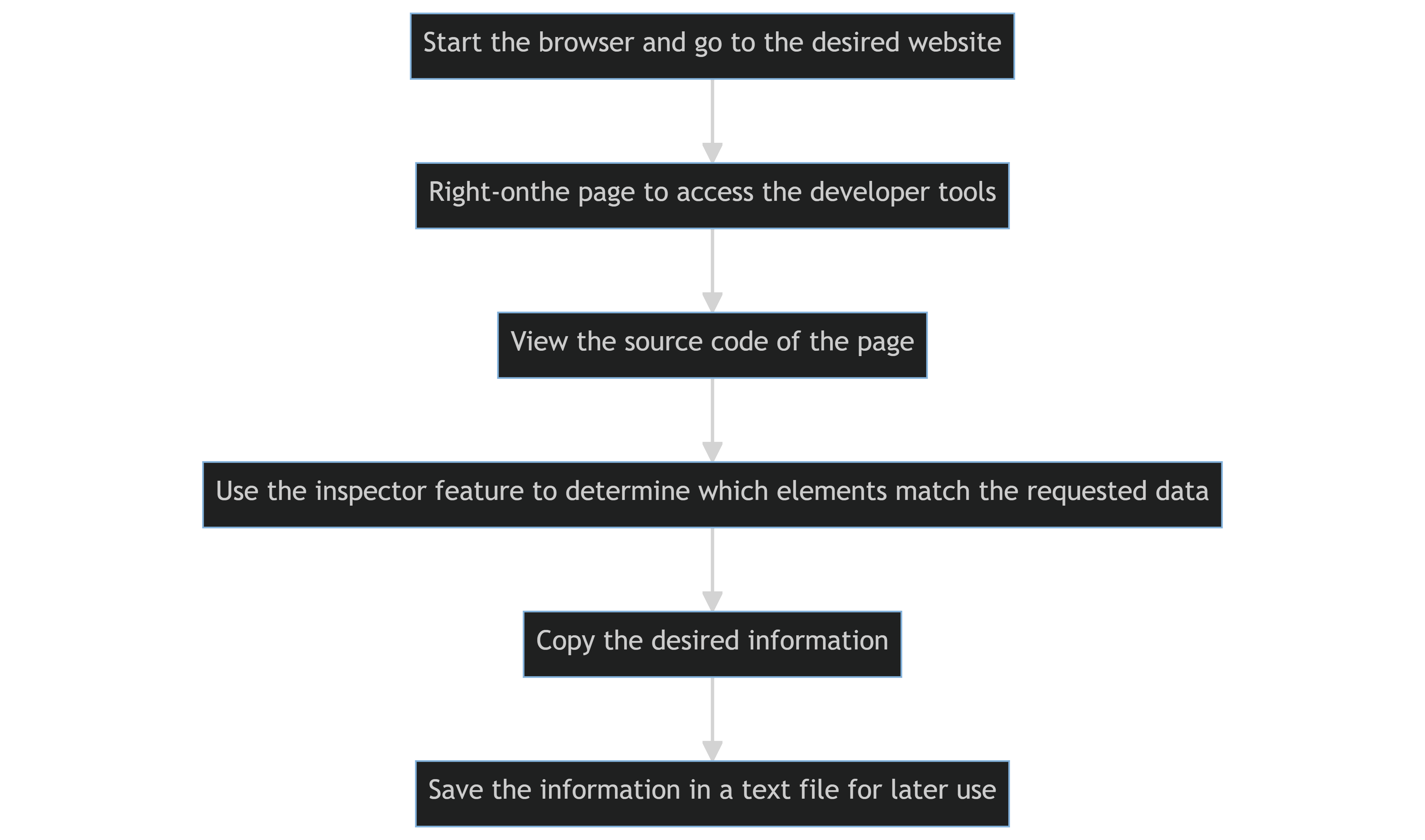
Der Quellcode einer Webseite wird manuell angezeigt und extrahiert, indem die Entwicklertools eines Webbrowsers genutzt werden.
Die grundlegenden Schritte sind wie folgt:
- Starten Sie den Browser und rufen Sie die gewünschte Website auf.
- Klicken Sie mit der rechten Maustaste auf die Seite, um die Entwicklertools im Browser zu öffnen.
- Zeigen Sie den Quellcode der Seite an.
- Nutzen Sie die Inspektor-Funktion Ihres Browsers, um zu bestimmen, welche Elemente auf einer Webseite den angeforderten Daten entsprechen.
- Kopieren Sie die gewünschten Informationen.
- Speichern Sie die kopierten Informationen in einer Textdatei zur späteren Verwendung.
Wie funktioniert automatisiertes Web-Scraping?
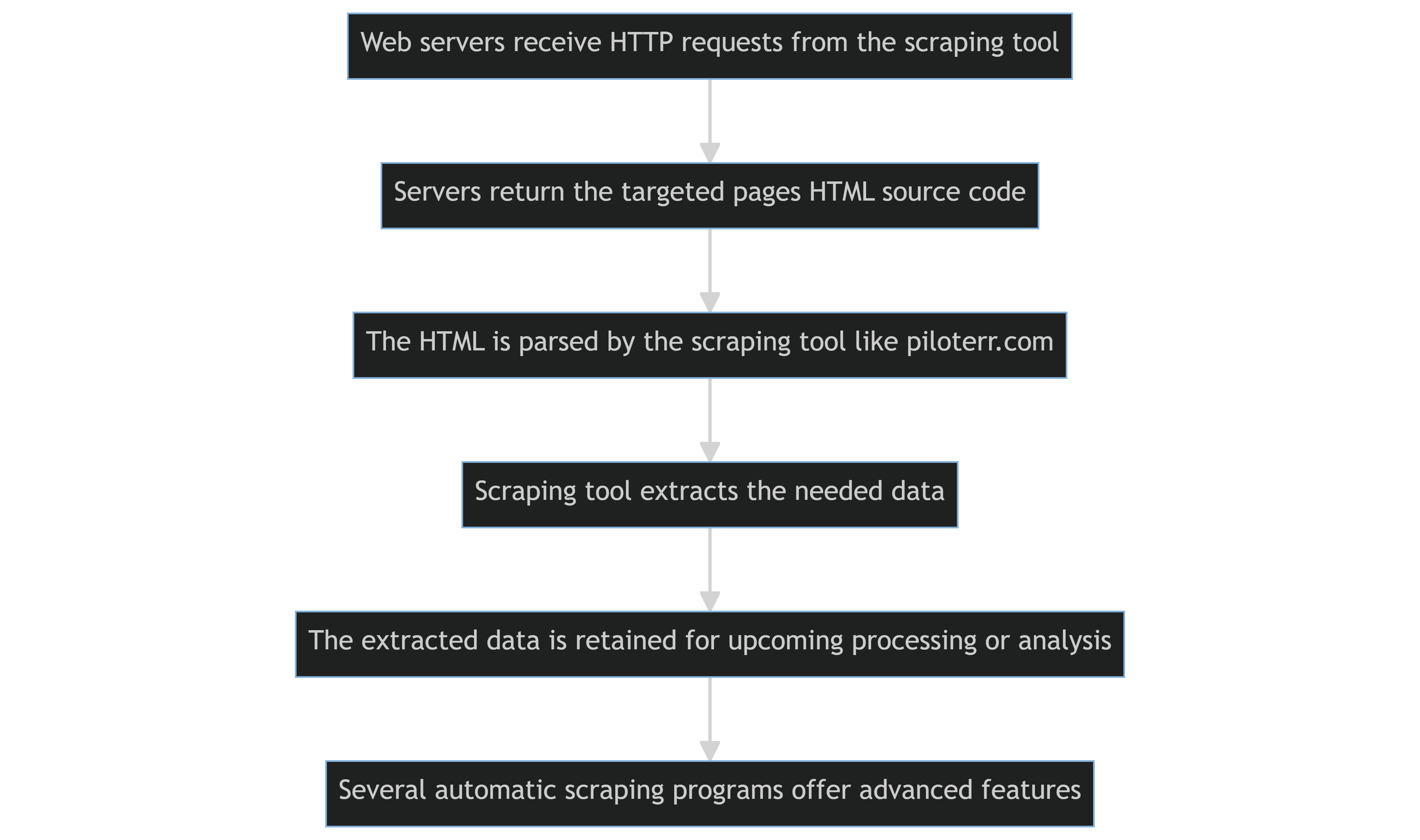
Die Verwendung von Scraping-Tools wie Python-Skripten oder Scrapy-Bibliotheken zur Extraktion von Inhalten von zahlreichen Websites wird als automatisiertes Web-Scraping bezeichnet.
Die grundlegenden Schritte sind wie folgt:
- Die Webserver, die die Zielwebsites hosten, erhalten programmgesteuert HTTP-Anfragen vom Scraping-Tool.
- Die Server geben den HTML-Quellcode der Zielseiten zurück.
- Das Scraping-Tool parst das HTML und extrahiert die benötigten Daten.
- Die extrahierten Daten werden für zukünftige Verarbeitung oder Analyse gespeichert.
- Mehrere automatische Web-Scraping-Programme können erweiterte Funktionen bieten, wie die Fähigkeit, Cookies zu verwalten oder die Nutzungsbedingungen einer Website zu umgehen, die das Scrapen von Inhalten verbieten oder einschränken.
Arten von Web-Scraping
Web-Scraper können in viele verschiedene Typen eingeteilt werden, darunter selbstgebaute oder vorgefertigte, Software oder Browser-Plugins, Cloud- oder lokale Scraper.
Selbstgebaute Web-Scraper : Selbstgebaute Web-Scraper sind möglich, erfordern jedoch ein hohes Maß an Programmierkenntnissen. Darüber hinaus benötigen Sie noch mehr Wissen, wenn Sie möchten, dass Ihr Web-Scraper mehr Funktionen hat. Vorgefertigte Web-Scraper hingegen sind Scraper, die bereits erstellt wurden und einfach heruntergeladen und verwendet werden können. Sie können diese anpassen und auch erweiterte Optionen hinzufügen.
Browser-Erweiterungs-Web-Scraper : Es gibt Erweiterungen für Ihren Browser, darunter Web-Scraper. Da sie in Ihren Browser integriert sind, sind sie einfach zu bedienen, aber dies bedeutet auch, dass sie einige Einschränkungen haben. Web-Scraper, die als Browser-Erweiterungen laufen, können keine komplexen Funktionen nutzen, die über die Fähigkeiten Ihres Browsers hinausgehen. Software-Web-Scraper hingegen können auf Ihren Computer heruntergeladen und installiert werden und sind daher nicht in dieser Weise eingeschränkt. Obwohl diese fortschrittlicher als Browser-Web-Scraper sind, enthalten sie auch innovative Funktionen, die nicht durch die Fähigkeiten Ihres Browsers begrenzt sind.
Cloud-Web-Scraper : Cloud-Web-Scraper laufen auf der Cloud, die normalerweise vom Anbieter des Scrapers bereitgestellt wird. Da sie keine Daten von Websites scrapen, kann sich Ihr Computer auf andere Aufgaben konzentrieren. Lokale Web-Scraper hingegen nutzen die lokalen Ressourcen Ihres Computers. Wenn die Web-Scraper also mehr CPU oder RAM benötigen, kann Ihr Computer langsamer werden und andere Aufgaben nicht mehr bewältigen.
Ist Web-Scraping legal?
Web-Scraping ist im Allgemeinen akzeptabel, solange es für vernünftige Zwecke durchgeführt wird und nicht gegen Urheberrechtsbestimmungen, Lizenzvereinbarungen oder die Nutzungsbedingungen einer Website verstößt.
Die Moral von Web-Scraping hängt hauptsächlich von der beabsichtigten Nutzung, den abgerufenen Daten, den Nutzungsbedingungen der Website und den Datenschutzgesetzen des Landes ab, in dem es durchgeführt wird.
Web-Scraping ist nicht unbedingt schwierig
Einige allgemeine Web-Scraping-Programme haben den Nachteil, dass sie sehr schwer zu erlernen und zu bedienen sind. Es gibt eine steile Lernkurve. Um dieses Problem zu lösen, wurde WebHarvy entwickelt. Die extrem einfache Point-and-Click-Oberfläche von WebHarvy ermöglicht es Ihnen, innerhalb weniger Minuten mit dem Scrapen von Daten von jeder Website zu beginnen.
Welche Arten von Tools können für Web Scraping genutzt werden?
Programmierkenntnisse sind für Web Scraping notwendig, wobei Python die am häufigsten verwendete Sprache für diese Aufgabe ist. Glücklicherweise bietet Python eine Vielzahl von Open-Source-Modulen, die Web Scraping erheblich vereinfachen. Einige davon sind wie folgt:
Ein weiteres Python-Paket, das häufig zur Extraktion von Daten aus XML- und HTML-Texten verwendet wird, heißt BeautifulSoup. Große Datenmengen lassen sich dank BeautifulSoup, das diese verarbeiteten Inhalte in benutzerfreundlichere Bäume organisiert, deutlich einfacher durchsuchen und navigieren. Es ist oft das bevorzugte Tool von Datenanalysten.
Ein auf Python basierendes Anwendungsframework namens Scrapy durchsucht das Web und extrahiert strukturierte Daten daraus. Es wird häufig für die Informationsverarbeitung, Datengewinnung und die Bewahrung historischer Inhalte eingesetzt. Es kann als allgemeiner Web-Crawler oder zur Datenextraktion über APIs verwendet werden, zusätzlich zum Web Scraping, für das es speziell entwickelt wurde.
Pandas
Eine weitere vielseitige Python-Bibliothek für Datenmanipulation und -indizierung heißt Pandas. Sie kann in Verbindung mit BeautifulSoup für das Web Scraping genutzt werden. Der Hauptvorteil der Verwendung von Pandas besteht darin, dass Analysten nicht zu anderen Sprachen wie R wechseln müssen, um den Datenanalyseprozess abzuschließen.
Andere Tools sind leicht verfügbar, von solchen für allgemeines Scraping bis hin zu solchen, die für komplexere, spezialisierte Aufgaben entwickelt wurden. Die beste Vorgehensweise ist, zu untersuchen, welche Technologien am besten zu Ihren Interessen und Ihrem Kenntnisstand passen, bevor Sie sie in Ihren Datenanalyse-Toolkasten integrieren.
Welche Schritte kann ich unternehmen, um zu verhindern, dass Inhalte meiner Website gescrapt werden?
Die Tatsache, dass das Scrapen von Website-Inhalten so häufig für legitime Zwecke wie die Suchmaschinenoptimierung (SEO) genutzt wird, macht es zu einer schwierigen Aufgabe, dies zu verhindern. Publisher können die folgenden Techniken anwenden, um die Wahrscheinlichkeit zu verringern, dass ihre Inhalte illegal oder unautorisiert gescrapt werden:
- Robots.txt Dateien: Web-Crawler und Scraper können Robots.txt-Dateien lesen, um herauszufinden, welche Websites für den Zugriff und das Scraping geeignet sind.
- CAPTCHAs: Durch das Einrichten von Tests, die für Menschen einfach zu lösen, aber für Computerprogramme schwierig sind, können CAPTCHAs unerwünschte Scraper-Tools abwehren.
- Anfragenlimits: Verwenden Sie Regeln namens "Anfragenlimits", um zu begrenzen, wie häufig eine Website HTTP-Anfragen von Scrapern erhalten kann.
- Code-Verschleierung: Verwenden Sie Techniken wie Minifizierung (Der Begriff "Minifizierung" bezieht sich auf den Prozess der Änderung von Code, um überflüssige Zeichen und Teile zu entfernen.), Umbenennung von Variablen und Funktionen oder Kodierung, um JavaScript in schwer lesbaren und verständlichen Code umzuwandeln.
- IP-Sperrung: Überwachen Sie Serverprotokolle auf Scraper-Aktivitäten und sperren Sie die IP-Adressen verdächtiger Scraper.
- Rechtliche Schritte: Ergreifen Sie rechtliche Maßnahmen, um unautorisiertes Scraping zu stoppen, indem Sie sich beim Hosting-Anbieter beschweren oder eine gerichtliche Verfügung beantragen.
Methoden zum Extrahieren von Daten von Websites
Ziel-URLs festlegen: Erstellen Sie eine Liste der Ziel-URLs (d. h. der Webseiten, von denen Sie Daten extrahieren möchten), sobald Sie festgelegt haben, von welcher Website Sie Daten scrapen möchten. Denken Sie daran, die Webseiten zu überprüfen, um die genauen Daten zu finden, die Sie scrapen möchten.
Auf die Website zugreifen, indem eine HTTP-Anfrage gesendet wird: Sie können Anfragen und Antworten über das Internet mit dem Anwendungsprotokoll HTTP organisieren. Daten müssen über den Netzwerkmechanismus von Server zu Client mit dem HTTP-Server-Client-Mechanismus übertragen werden. Ihr Computer oder Smartphone kann als Client fungieren, während der Webhost der Server ist, der bereit ist, die Daten nach einer erfolgreichen Anfrage bereitzustellen. Wenn der Client Daten vom Server anfordert, benötigt der Server eine GET-Antwort. Beachten Sie, dass die Methoden, die verschiedene Programme und Computersprachen zum Senden von HTTP-Anfragen verwenden, variieren. Der Server stellt die Daten als Antwort auf die HTTP-Anfrage bereit, sodass Sie die HTML- oder XML-Seite anzeigen können.
Seiteninhalt von Ziel-URLs herunterladen (Daten-Download): Sie können eine Webseite herunterladen und deren Inhalte auf Ihrem Bildschirm anzeigen, indem Sie Daten abrufen.
Informationen von der Seite extrahieren (Daten-Parsing): Nachdem Sie Daten von den Ziel-URLs extrahiert haben, müssen Sie diese parsen, um sie verständlicher und für die Datenanalyse geeignet zu machen. Da reine HTML-Daten schwer verständlich sind, ist Daten-Parsing erforderlich. Die Daten müssen zunächst in einem verständlichen Format für den Datenanalysten dargestellt werden. Dies könnte das Erstellen von Berichten aus HTML-Zeichenfolgen oder das Erstellen von Datentabellen, die relevante Daten anzeigen, beinhalten.
Die extrahierten Daten formatieren: Die geparsten Daten können dann in eine Excel-, Google Sheets- oder CSV-Tabelle exportiert werden. Sie können APIs nutzen, da viele automatisierte Web-Scraping-Lösungen Formate wie JSON akzeptieren.
Verhinderung von Web-Crawling
Einige standardmäßige Sicherheitsvorkehrungen sind aufgrund der Intelligenz bösartiger Scraper-Bots nicht mehr wirksam. Beispielsweise können Headless-Browser-Bots Menschen imitieren, um der Erkennung durch die meisten Abwehrmaßnahmen zu entgehen. Imperva setzt detaillierte Verkehrsanalysen ein, um die Fortschritte bösartiger Bot-Betreiber zu vereiteln. Es stellt sicher, dass sowohl menschlicher als auch automatisierter Traffic zu Ihrer Website vollständig legitim ist.
Während des Prozesses werden mehrere Kriterien überprüft, darunter:
- TLS-Fingerabdruck: Eine gründliche Untersuchung der HTML-Header dient als erster Schritt im Filterprozess. Diese können Hinweise darauf geben, ob ein Besucher bösartig oder sicher, ein Mensch oder ein Bot ist. Eine Datenbank mit über 10 Millionen bekannten Varianten, die regelmäßig aktualisiert wird, dient zum Vergleich der Header-Signaturen.
- IP-Reputation: Sammeln Sie IP-Informationen von allen Angriffen auf unsere Kunden. Besuche von IP-Adressen, die in der Vergangenheit für Angriffe genutzt wurden, werden misstrauisch betrachtet und unterliegen mit höherer Wahrscheinlichkeit einer weiteren Überprüfung.
- Verhaltensanalyse: Die Überwachung der Interaktionen von Nutzern mit einer Website kann ungewöhnliche Verhaltensmuster aufdecken, wie z. B. verdächtig hohe Anfragenraten und unlogische Browsing-Gewohnheiten. Dies erleichtert das Erkennen von Besuchern, die tatsächlich Bots sind.
- Progressive Herausforderungen: Progressive Herausforderungen werden eingesetzt, um Bots auszusieben und falsch-positive Ergebnisse zu reduzieren. Diese Herausforderungen umfassen Cookie-Unterstützung und JavaScript-Ausführung. Eine CAPTCHA-Herausforderung kann als letzte Maßnahme Bots eliminieren, die versuchen, Menschen zu imitieren.
Beispiele für Web Scraping
Wenn Daten ohne Zustimmung der Website-Besitzer von Websites entnommen werden, spricht man von schädlichem Web Scraping. Preis-Scraping und Inhaltsdiebstahl sind die beiden häufigsten Anwendungsszenarien.
Preis-Scraping: Um die Datensätze von Konkurrenzunternehmen zu durchsuchen, startet ein Täter von Preis-Scraping in der Regel Scraper-Bots von einem Botnetz. Das Ziel ist es, Zugang zu Preisdaten zu erhalten, Konkurrenten zu unterbieten und den Umsatz zu steigern. Angriffe treten meist in Branchen auf, in denen Produkte leicht vergleichbar sind und die Preise die Kaufentscheidungen stark beeinflussen. Reiseanbieter, Ticketverkäufer und Online-Elektronikhändler können alle Opfer von Preis-Scraping werden.
Inhalts-Scraping: Unter Inhalts-Scraping versteht man den großflächigen Diebstahl von Inhalten von einer bestimmten Website. Häufige Ziele sind Online-Produktverzeichnisse und Websites, die auf digitale Inhalte angewiesen sind, um Traffic zu generieren. Ein Inhalts-Scraping-Angriff könnte für diese Unternehmen tödlich sein.
Warum ist Python eine so geschätzte Programmiersprache für Web Scraping?
Heutzutage scheint Python im Trend zu liegen! Da es die meisten Aufgaben problemlos bewältigen kann, ist es die am häufigsten verwendete Sprache für Web Scraping. Darüber hinaus bietet es eine Reihe von Bibliotheken, die speziell für Web Scraping entwickelt wurden. Scrapy, ein auf Python basierendes, recht bekanntes Open-Source-Web-Crawling-Framework, ist perfekt für sowohl API-basierte Datenextraktion als auch Web Scraping. Ein weiteres hervorragendes Python-Modul für Web Scraping heißt Beautiful Soup. Es erstellt einen Parse-Baum, um Daten aus HTML auf einer Website zu extrahieren. Diese Parse-Bäume können mit verschiedenen Funktionen in Beautiful Soup durchsucht, navigiert und modifiziert werden.