Die Open-Source-Community floriert, besonders in diesen Zeiten, in denen KI allgegenwärtig ist und eine immer größere Menge an Daten für ihre Modelle benötigt. Dieser Trend hat zu einem Anstieg der Web-Scraping-Aktivitäten geführt, aber auch zur Entwicklung fortschrittlicherer Anti-Bot-Maßnahmen. Vor diesem Hintergrund möchte ich einige der beeindruckendsten Python-Bibliotheken vorstellen, die KI im Web Scraping nutzen und Anti-Bot-Schutzmechanismen überwinden.
Überspringen Sie den Bibliotheks-Stack: Nutzen Sie Anti-Bot-Umgehung mit 500 Bibliotheks-Endpunkten, die enthalten sind.
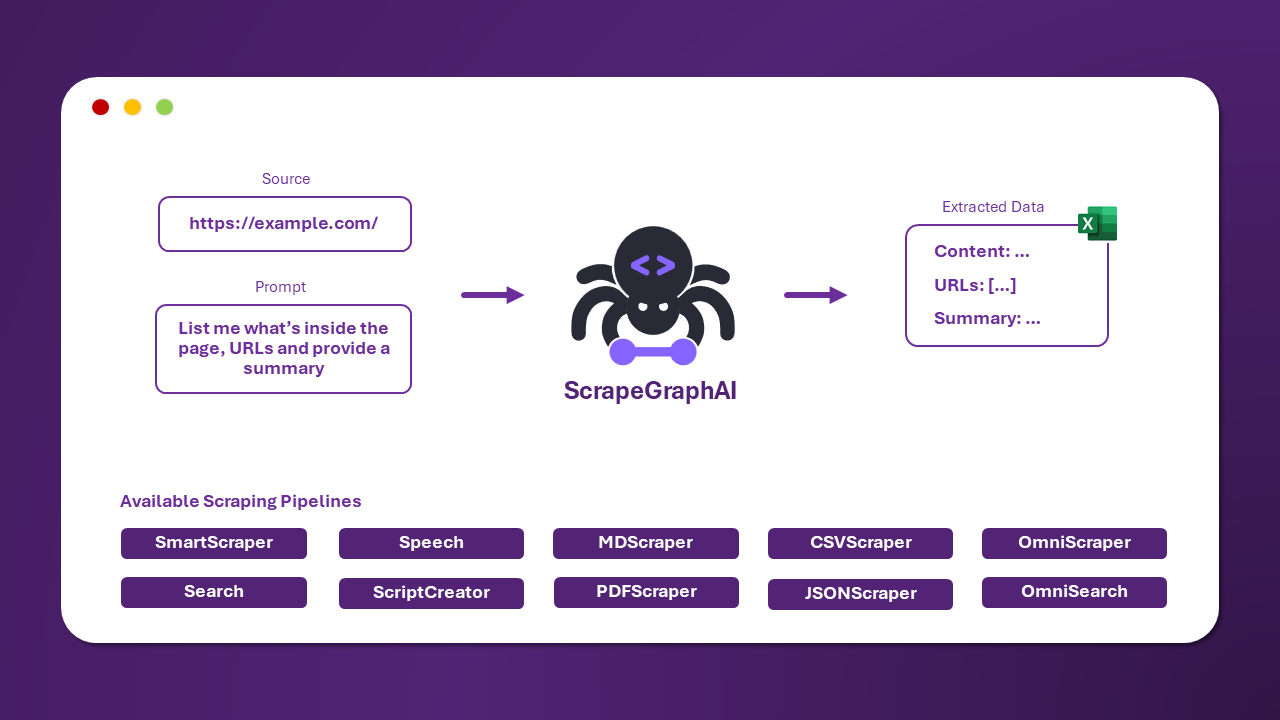
ScrapeGraphAI
Mit ScrapeGraphAI können Sie Ihr bevorzugtes LLM (lokal oder online) verbinden und:
- Daten von einzelnen oder mehreren Seiten extrahieren, indem Sie ein Ziel-Daten-Schema definieren.
- Daten aus Suchmaschinenergebnissen extrahieren.
- Audiodateien aus extrahierten Websitedaten generieren.
- Automatisch Python-Code für Ihren Scraper mit Bibliotheken wie BeautifulSoup schreiben.
Während LLMs immer erschwinglicher und genauer werden, sind ihre Antwortzeiten noch nicht ideal für Web-Scraping-Projekte auf Produktionsebene. Die beste Nutzung dieser Technologie im Web Scraping besteht meiner Meinung nach darin, automatisch Scraper-Code zu schreiben und zu korrigieren und die Ausführung den aktuellen Frameworks zu überlassen. Sie arbeiten auch an der Extraktion von Daten aus lokalen Dokumenten, auf deren Fortschritt ich gespannt bin. Sie können deren Fortschritt verfolgen, indem Sie ihrem Discord-Server beitreten.
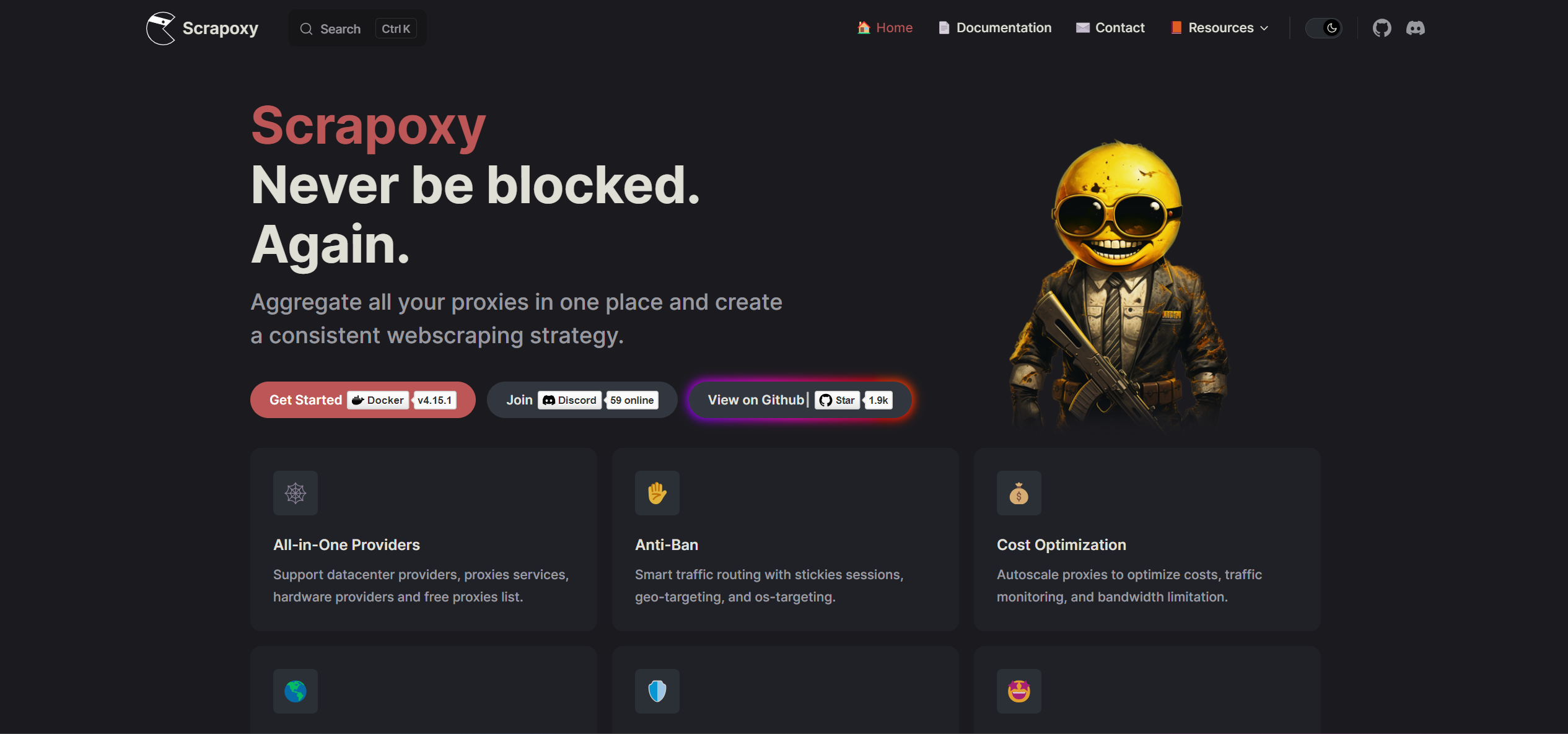
Scrapoxy
Vielleicht kennen Sie Fabien Vauchelles, den Schöpfer von Scrapoxy, von seinen aufschlussreichen Vorträgen über Bots und Anti-Bot-Technologien bei verschiedenen Web-Scraping-Veranstaltungen und Webinaren. Scrapoxy ist ein leistungsstarker Proxy-Aggregator, mit dem Sie Proxys von verschiedenen Anbietern, sowohl kostenlosen als auch kommerziellen, verwalten können.
Was Scrapoxy auszeichnet, ist sein innovatives Management von Rechenzentrums-Proxys. Durch das Erstellen und Rotieren von virtuellen Maschinen über verschiedene Cloud-Anbieter hinweg ermöglicht Scrapoxy den Aufbau eines nahezu unendlichen Pools von IP-Adressen mit unbegrenzter Bandbreite. Darüber hinaus ist es nicht nur auf diese Funktionalität beschränkt; durch die Verwendung eines einzigen Endpunkts in Ihren Scrapern können Sie verschiedene Proxy-Anbieter und -Typen mischen, was Ihre Scraping-Fähigkeiten weiter verbessert.
Botasaurus
Botasaurus ist ein weiteres robustes Framework, das es wert ist, erkundet zu werden. Es unterstützt die Erstellung von sowohl Headless- als auch Headful-Scrapern. Bei meinen ersten Tests vor einigen Monaten zeigte Botasaurus seine Fähigkeit, die Erkennung durch Cloudflare und andere Anti-Bot-Systeme zu umgehen, obwohl es einige Einschränkungen hat.
Beim Ausführen eines Headful-Scrapers von einem Rechenzentrum fehlen Botasaurus derzeit erweiterte Optionen zur Maskierung Ihres Browser-Fingerabdrucks, was zu Blockierungen führen kann. Trotzdem ist es ein Tool, das man im Auge behalten sollte.
Nodriver
Nodriver ist der Nachfolger von Undetected-Chromedriver und macht die Verwendung von Selenium und Webdrivers überflüssig. Es ist vollständig asynchron und bietet ein schnelles Tool zum Scrapen, das nativ darauf optimiert ist, von den meisten Anti-Bot-Lösungen unentdeckt zu bleiben – und das mit nur wenigen Codezeilen. Sie können auch verschiedene Profile verwalten und haben alles, was Sie für Ihre Scraper benötigen. Darüber hinaus umfasst es Hilfsmittel für intelligente Elementsuche, Sitzungsmanagement und nahtlose Integration mit bestehenden undetected_chromedriver-Instanzen, was es zu einem vielseitigen und leistungsstarken Werkzeug für automatisierte Webaufgaben macht.
Undetected Playwright
Undetected Playwright ist ein Patch, den Sie auf Ihre Playwright-Scraper anwenden können, um deren Unerkennbarkeit gegenüber Anti-Bot-Systemen zu verbessern. Wir haben diesen Patch in einem Artikel über CDP-Erkennungstechniken in Aktion gesehen, wo er die Leistung unserer Scraper beim Umgehen dieser zunehmend verbreiteten Anti-Bot-Methoden deutlich verbessert hat.
Camoufox
Camoufox ist ein Browser, der sich derzeit in der Entwicklung befindet und kürzlich von seinem Autor in unserem Discord-Server vorgestellt wurde. Er sieht sehr vielversprechend aus. Basierend auf Firefox hat der Autor unnötige Funktionen entfernt und TLS-Maskierung, Browserforge zur Veränderung des Browser-Fingerabdrucks sowie mehrere andere Funktionen hinzugefügt. Tests auf bekannten Websites wie Browserscan sehen vielversprechend aus, und ich bin gespannt, ihn auszuprobieren.