Die Sicherstellung hochwertiger Daten in Web-Scraping-Operationen ist eine vielschichtige Herausforderung, die für zuverlässige Analysen und Entscheidungsfindungen entscheidend ist. Mit der Skalierung von Web-Scraping-Projekten steigt die Komplexität der Validierung der Korrektheit und Vollständigkeit der gescrapten Daten, was potenziell die Datenqualität mindern kann. Dieser Artikel bietet einen umfassenden Überblick über Techniken zur Verbesserung der Integrität von Web-Scraping-Projekten.
Zuverlässige Daten beginnen mit zuverlässiger Extraktion: Entdecken Sie Scraper APIs und unser Datenqualitäts-Glossar.
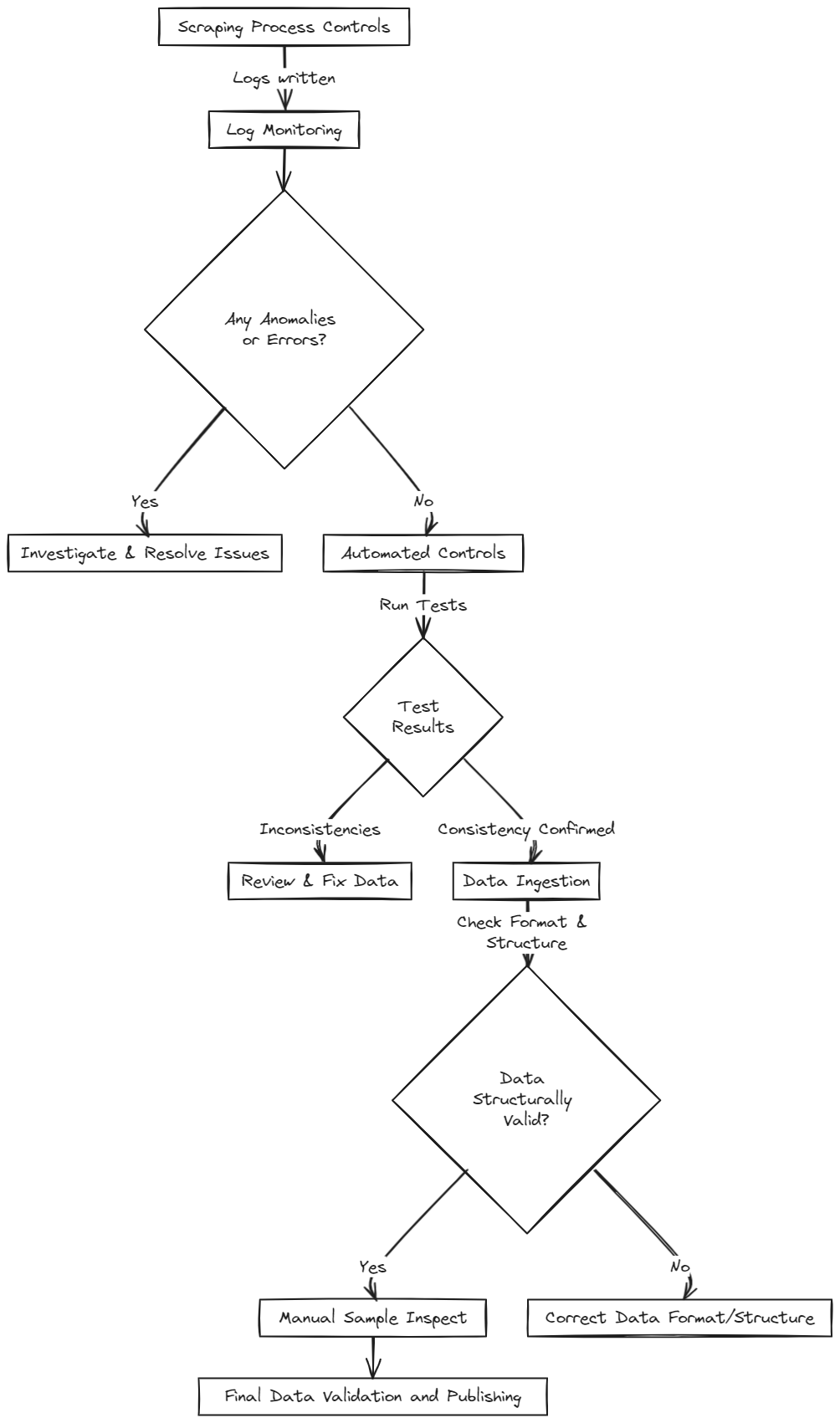
Überwachung des Scraping-Prozesses
Ein effektives Datenqualitätsmanagement beginnt mit gut gestalteten Scrapern, die ihre Aktivitäten protokollieren und potenzielle Probleme durch HTTP-Rückgabecodes hervorheben. Ein 404-Fehler zeigt beispielsweise eine fehlende Seite an, möglicherweise aufgrund eines defekten Links oder einer Anti-Bot-Maßnahme, was zu teilweisen oder unvollständigen Daten führt. Das Sammeln dieser Protokolle, wie bei Scrapy, ist essenziell für die Fehlerbehebung.
Datenaufnahme
Änderungen in der Struktur von Webseiten können dazu führen, dass Selektoren brechen und Daten in unerwarteten Formaten erfasst werden. Die Implementierung von Prüfungen während des Ladens in die Datenbank bietet einen zentralen Kontrollpunkt, um die Datenkonsistenz über mehrere Scraping-Quellen hinweg aufrechtzuerhalten.
Automatische Datenqualitätskontrollen
Abhängig von der Art der Daten können verschiedene automatische Prüfungen eingerichtet werden. Numerische Felder, wie Produktpreise, können automatisch auf Kohärenz überprüft werden, während qualitative Daten, wie Textfelder, unterschiedliche Strategien erfordern können.
Datenvollständigkeit und Kohärenz
Datenvollständigkeit ist eine grundlegende Metrik, wobei Alarme bei Abweichungen von den erwarteten Artikelzahlen eingerichtet werden. Beispielsweise verwendet Retailed.io eine Ground-Truth-Methode, bei der Entwickler die erwarteten Artikelzahlen bereitstellen, die von Kollegen überprüft und aktualisiert werden. Signifikante Abweichungen lösen Alarme aus und stoppen die Datenveröffentlichung, bis sie verifiziert sind.
Qualitative Datenqualität
Automatisierte Kontrollen haben Grenzen bei qualitativen Feldern. Während einige Prüfungen auf bekannte Domänenwerte oder Formatvalidierungen (z. B. E-Mail, URLs) möglich sind, kann die tatsächliche Gültigkeit von Inhalten wie Produktbeschreibungen eine manuelle Inspektion erfordern.
Nur Daten, die alle vorherigen Qualitätsprüfungen erfolgreich bestanden haben, sollten veröffentlicht werden.