Etwa 20% der Websites, die Sie scrapen müssen, verwenden Cloudflare, ein robustes Anti-Bot-Schutzsystem, das Sie leicht blockieren kann. Indeed gehört zu den Websites, die durch das Cloudflare- Anti-Bot-System geschützt sind und seine bekannte Herausforderung "Verify you are human" oder "Additional Verification Required" aufweisen. In diesem Artikel werden wir mögliche Lösungen erkunden, um deren Anti-Bot-Maßnahmen zu umgehen und erfolgreich die Job-Seiten sowie Unternehmensseiten zu scrapen.
Übersicht über Indeed-Scraping
Indeed ist in mehrere Abschnitte unterteilt:
- Suchergebnisseiten
- Stellenanzeigenseiten
- Unternehmensprofilseiten
Was ist Datenscraping?
Datenscraping oder "Web Scraping" bezieht sich auf die automatisierte Extraktion von Daten von einer Website durch Software oder Skripte. Dieser Prozess ermöglicht es Unternehmen, große Mengen an Informationen schnell zu sammeln, darunter Stellenangebote, Unternehmensdetails und sogar Benutzerprofile. Beispielsweise können von Indeed gescrapte Daten wertvoll für Analysen, Personalbeschaffung und Wettbewerbsforschung sein, müssen jedoch strengen rechtlichen Rahmenbedingungen entsprechen.
Die Bedeutung von Datenscraping auf Indeed verstehen
Datenscraping ermöglicht es Unternehmen und Forschern, wertvolle Informationen von Indeed's Plattform zu sammeln, wie z.B. Jobtrends, Gehälter, Qualifikationsanforderungen und Arbeitgeberdaten. Diese Daten helfen bei fundierten Entscheidungen, Marktforschung und der Entwicklung innovativer Dienstleistungen.
Wie nutzen Unternehmen die gewonnenen Daten?
Unternehmen nutzen gescrapte Daten, um Branchentrends zu verfolgen, Konkurrenten zu analysieren, Rekrutierungsstrategien zu verbessern und Einblicke in den Arbeitsmarkt zu gewinnen. Diese Daten ermöglichen es Organisationen, Einstellungspraktiken zu optimieren, datengetriebene Produkte zu entwickeln und Marktbedürfnisse effektiver zu verstehen. Das Scrapen von Daten von Indeed erfordert einen strategischen Ansatz aufgrund der Struktur der Plattform und der Schutzmaßnahmen wie Cloudflares Anti-Bot-Systeme. Das Verständnis der Organisation von Indeed und wie man diese Sicherheitsprotokolle umgeht, hilft Ihnen, die benötigten Daten effizient zu sammeln.
Methode 1: Den Prozess des Web Scrapings erkunden
Hauptschritte beim Erstellen eines Web Scrapers für Indeed
- Ziele festlegen
Definieren Sie klar, welche Daten Sie von Indeed extrahieren möchten. Dies könnte Jobtitel, Standorte, Gehälter oder Unternehmensnamen umfassen. Konkrete Angaben erleichtern die Entwicklung eines effizienten Web Scrapers und verhindern das Sammeln unnötiger Daten. - Elemente der Jobseite analysieren: Nutzen Sie die Browser-Entwicklertools, um die Struktur der Job- oder Unternehmensseite zu untersuchen. Durch das Identifizieren der relevanten HTML-Elemente können Sie den benötigten Text aus den Suchergebnissen lokalisieren und extrahieren.
- Mit Cloudflare-Schutz umgehen: Indeed verwendet Cloudflares Anti-Bot-Schutz, der Scraping-Versuche behindern kann. Um diese Schutzmaßnahmen zu überwinden, können Tools wie
Cloudscraper,FlareSolverr,Cfscrapeoder andere Cloudflare-Löser vorteilhaft sein. Diese Tools emulieren menschliches Surfverhalten und helfen dem Web Scraper, CAPTCHA-Herausforderungen und andere Bot-Erkennungsmechanismen zu umgehen. - Web Scraper entwickeln: Nutzen Sie Python-Bibliotheken wie
Beautiful Soup,ScrapyoderCheerio,lxml, um Ihren Web Scraper zu entwickeln. Diese Bibliotheken helfen beim Navigieren auf Indeed-Webseiten, Parsen des HTML und Extrahieren der gewünschten Daten/Text/Bilder. - Rate-Limits verwalten: Zu schnelles Scrapen von Websites kann Anti-Bot-Schutzmaßnahmen auslösen. Um Blockierungen zu vermeiden, integrieren Sie rotierende Proxys und implementieren Sie Verzögerungen bei Anfragen, um menschliches Surfverhalten nachzuahmen. Dies hilft Ihnen, große Datenmengen zu sammeln, ohne entdeckt zu werden.
- Daten parsen und bereinigen: Nach der Extraktion der Daten bereinigen und strukturieren Sie diese für die weitere Analyse. Entfernen Sie unnötige Zeichen und formatieren Sie die Jobdaten.
- Datenspeicherung: Sobald die Daten bereinigt sind, speichern Sie sie in einem effizienten Format, wie einer Datenbank mit Postgres (Supabase, Airtable...) oder einer CSV-Datei. Dies erleichtert die Analyse, Visualisierung oder weitere Verarbeitung gemäß Ihren Anforderungen. Regelmäßige Wartung: Scraping erfordert kontinuierliche Wartung. Überwachen und aktualisieren Sie Ihren Web Scraper regelmäßig, um sich an Änderungen in der Webseitenstruktur von Indeed, Inhaltsaktualisierungen und sich entwickelnde Sicherheitsprotokolle, einschließlich Cloudflares Abwehrmaßnahmen, anzupassen.
Verständnis des Cloudflare Bot Managements
Cloudflare bietet Content-Delivery- und Web-Sicherheitsdienste, einschließlich seines Web Application Firewall (WAF), das Websites vor Bedrohungen wie Cross-Site-Scripting (XSS), Credential Stuffing und Distributed Denial of Service (DDoS)-Angriffen schützt.
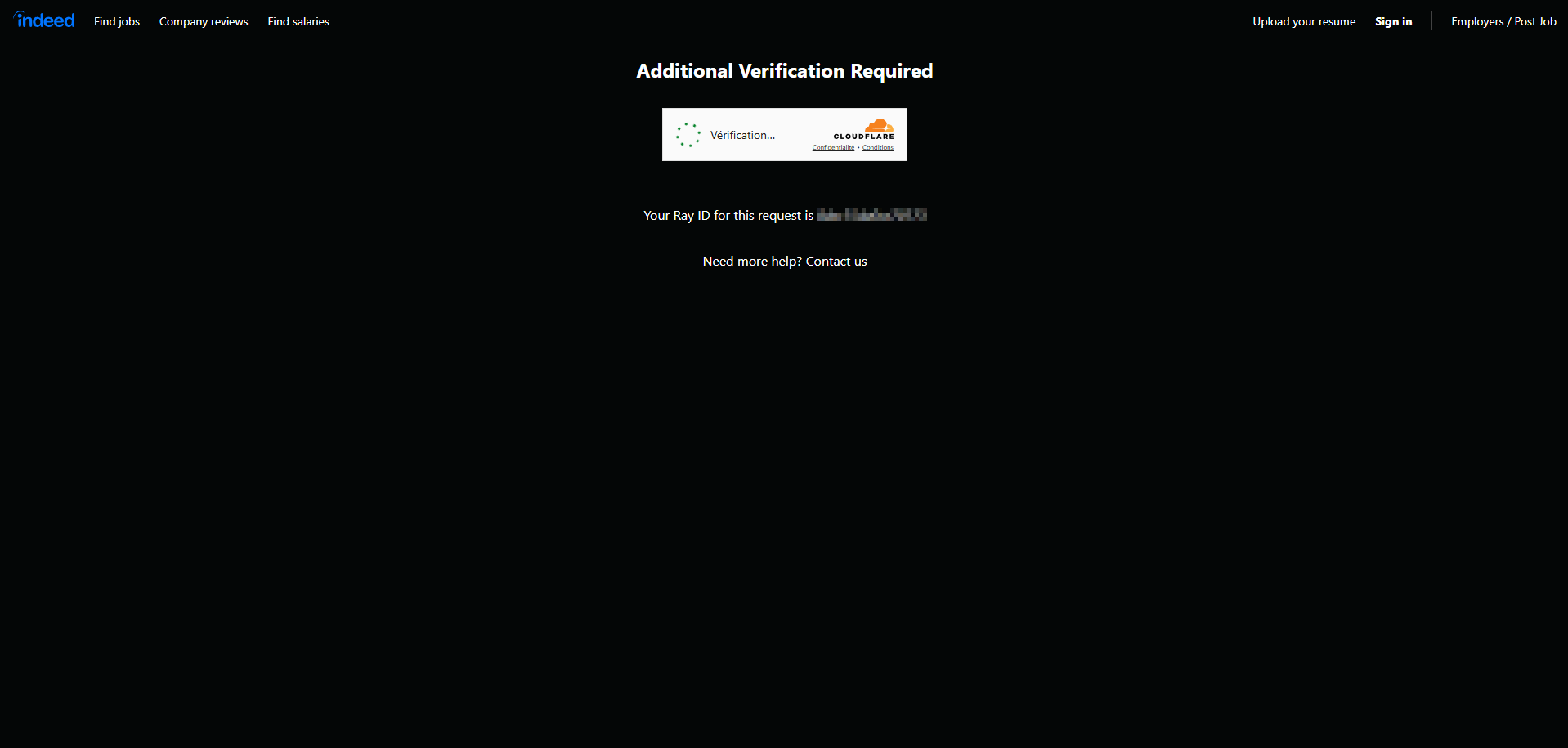
Ein wichtiger Bestandteil von Cloudflare ist der Bot Manager, der Websites vor bösartigem Bot-Verkehr schützen soll. Der Bot Manager identifiziert und mildert Bot-Angriffe, ohne legitime Benutzer zu stören. Allerdings betrachtet Cloudflare jeden unbekannten oder nicht auf der Whitelist stehenden Bot-Verkehr, wie Web Scraper, als bösartig. Daher können auch legitime Scraping-Versuche blockiert werden, was zur Verweigerung des Zugriffs auf Cloudflare-geschützte Websites führt.
Diese Fehler werden oft von einem Cloudflare 403 Forbidden HTTP-Statuscode begleitet, der anzeigt, dass die Anfrage aufgrund verdächtiger Bot-Aktivität blockiert wurde. Um diese Schutzmaßnahmen zu umgehen, können spezifische Cloudflare-Löser oder Techniken wie rotierende Proxys, das Nachahmen menschlichen Verhaltens oder die Verwendung von Headless-Browsern erforderlich sein.
Ein schlechtes Beispiel für einen Python-Scraper-Job
Der folgende Code-Ausschnitt zeigt ein Beispiel für eine HTTP-Anfrage und eine Parsing-Methode, die darauf abzielt, Jobdaten von Indeed mit Python-Bibliotheken wie httpx und re zu extrahieren:
import httpx
import re
import json
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
}
def parse_search_page(html: str):
data = re.findall(r'window.mosaic.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});', html)
if data is not None and data != 'null':
return json.loads(data[0])
response = httpx.get("https://www.indeed.com/viewjob?jk=cbce6eaf017aa47b", headers=headers)
print(parse_search_page(response.text))
Diese Anfrage schlägt fehl, da Indeed's Website Anti-Bot-Schutzmaßnahmen einsetzt, insbesondere durch Cloudflare, das HTTP-Anfragen blockiert, die kein menschliches Verhalten simulieren. Bibliotheken wie httpx oder requests sind gegen diese Schutzmaßnahmen in der Regel unwirksam. Um Cloudflare zu umgehen, benötigen Sie Tools wie Headless-Browser oder dedizierte Web-Scraper-APIs, die menschliche Interaktionen zuverlässiger nachahmen können.
Methode 3: Web-Scraping-API zur Umgehung von Cloudflare
Während die in diesem Artikel erwähnten Techniken hilfreich sein können, können sie aufgrund der häufigen Aktualisierungen der Sicherheitsmaßnahmen von Cloudflare nicht immer Erfolg garantieren. Die zuverlässigste Methode, um mit Cloudflare umzugehen, ist die Verwendung einer Web-Scraping-API wie Piloterr. Diese übernimmt alle Erkennungsmethoden von Cloudflare im Hintergrund, sodass Sie sich auf Ihre Scraping-Logik konzentrieren können, ohne sich um die Umgehung des Bot-Schutzes kümmern zu müssen.
Piloterr funktioniert mit allen Programmiersprachen. Sie benötigen nur einen einzigen API-Aufruf, um Cloudflare zu umgehen und die benötigten Daten abzurufen.
Um zu sehen, wie Piloterr funktioniert, verwenden wir es, um auf Indeed Jobs zuzugreifen, eine Website, die stark durch Cloudflare geschützt ist.
Python-Code:
# Installieren Sie das requests-Modul, falls benötigt
import requests
# Indeed-URL
url = 'https://www.indeed.com/jobs?q=senior+java+developer&l=berlin'
api_key = ''
# Anfrageparameter für die Piloterr-API
params = {
'query': url,
'wait_in_seconds': 10
}
# Senden einer GET-Anfrage an die Piloterr-API
response = requests.get(
'https://piloterr.com/api/v2/website/rendering',
params=params,
headers={'x-api-key': api_key}
)
# Ausgabe des rohen HTML der Indeed-Seite
print(response.text)
Mit dieser Anfrage können Sie alle Jobs abrufen, die das Schlüsselwort „Senior Java Developer“ am Standort „Berlin“ enthalten.
Schauen Sie sich die Dokumentation an, um zu sehen, wie Sie die Scraping-Anfrage konfigurieren. Fügen Sie einfach die Ziel-URL ein, fügen Sie eine wait_in_seconds zwischen 5-20 Sekunden hinzu, und Sie können eine einfache HTTP-Anfrage verwenden, um nach Jobs zu suchen (und den Cloudflare-Anti-Bot zu umgehen), URLs und Text ohne Probleme zu scrapen.
Methode 4: Unternehmens-URLs auf Indeed mit Python scrapen
Wenn Sie daran interessiert sind, Unternehmensdaten auf Indeed zu scrapen, bietet Piloterr eine dedizierte Web-Scraping-API, die den Prozess einfach und effizient macht. Mit dieser API können Sie Cloudflares Schutz nahtlos umgehen und strukturierte JSON-Daten über Unternehmen auf Indeed erhalten.
Anwendungsfall: Unternehmensinformationen mit Python scrapen
Um Unternehmensinformationen für ein bestimmtes Unternehmen auf Indeed abzurufen, folgen Sie diesen Schritten:
- Unternehmen auswählen: Finden Sie die Unternehmens-URL auf Indeed (z.B. https://indeed.com/cmp/Microsoft).
- API-Aufruf: Verwenden Sie eine GET-Anfrage an Piloterrs dedizierten Endpunkt für Indeed-Unternehmensinformationen.
Python-Code:
import requests
# Definieren Sie die API-URL für Unternehmensinformationen
url = 'https://indeed.com/cmp/Microsoft'
api_key = ''
# API-Endpunkt und Parameter festlegen
api_endpoint = 'https://piloterr.com/api/v2/indeed/company/info'
params = {'query': url}
# Senden Sie die GET-Anfrage mit dem API-Schlüssel
response = requests.get(api_endpoint, params=params, headers={'x-api-key': api_key})
# Ausgabe der JSON-Antwort mit den Unternehmensdaten
print(response.json())
Antwort:
{
"founded": 1975,
"revenue": "over-$10B (USD)",
"website": "http://www.microsoft.com/",
"industry": "Information Technology",
"logo_url": "https://d2q79iu7y748jz.cloudfront.net/s/_squarelogo/96x96/88813b3f866a5b58c9685073e3b87e05",
"company_url": "https://indeed.com/cmp/Microsoft",
"description": "There’s work, and then there’s your life’s work...",
"headquarter": "One Microsoft Way Redmond, Washington 98052-6399",
"staff_range": "over-10000",
"company_name": "Microsoft",
"dynamic_sections": {...},
"similar_companies": {...}
}
- JSON verarbeiten: Die Antwort enthält die Unternehmensdaten im JSON-Format, was die Analyse des Textes und die Integration in Ihre Anwendungen erleichtert.
Durch die Nutzung dieses Endpunkts sparen Sie Zeit, da die Antwort bereits in JSON strukturiert ist, was eine reibungslose Integration in Ihre Scraping-Logik ermöglicht, ohne rohes HTML parsen zu müssen.
Hinweis: Es enthält keine URLs und Jobs, dieser API-Endpunkt konzentriert sich auf Unternehmensinformationen. Einige Felder in der JSON-Antwort können null sein, wenn die Informationen nicht verfügbar sind oder wenn Indeed den Zugriff auf bestimmte Daten eingeschränkt hat. Stellen Sie sicher, dass Ihr Python-Code diese Fälle behandelt, um mögliche Fehler bei der Datenverarbeitung zu vermeiden.
Die Nutzung dieses Endpunkts spart Zeit, da die Antwort bereits in JSON strukturiert ist, was eine reibungslose Integration in Ihre Scraping-Logik ermöglicht, ohne rohen HTML-Text parsen zu müssen. Weitere Informationen finden Sie in der Dokumentation von Piloterr, um zusätzliche Optionen zur Optimierung Ihrer Anfragen zu entdecken, wie z.B. das Festlegen der Wartezeit in Sekunden, Suchparameter oder das Anpassen der User-Agent-Header, um die Antwortqualität zu verbessern.
Mit Piloterr können Sie auch direkt Stellenangebote von Unternehmensprofilen auf Indeed scrapen, wie z.B. diese URL: indeed.com/cmp/Google/jobs. Der Indeed Job Scraper ermöglicht es Ihnen, wertvolle Jobdaten zu extrahieren, einschließlich Jobtitel, Beschreibungstext, Unternehmensname, Standort, Gehalt, Bewertungen, Anstellungsart und mehr.
Indeed-Unternehmensdaten scrapen
Hier sind einige wertvolle Anwendungsfälle:
1. Gehaltsanalyse & Benchmarking / Mit den Gehaltsdaten aus Stellenangeboten können Sie:
- Vergütungen über verschiedene Rollen und Standorte vergleichen
- Gehaltstrends für bestimmte Positionen verfolgen
- Arbeitssuchenden helfen, bessere Angebote auszuhandeln
Zum Beispiel können wir aus den Daten ersehen, dass die Gehälter für Software-Ingenieure bei Microsoft je nach Standort und Erfahrung stark variieren.
2. Arbeitsmarkt-Intelligenz / Die Daten liefern Einblicke in:
- Gefragte Jobtitel und deren Nachfrage (z.B. Microsoft hat 339 Stellen für Softwareentwicklung)
- Geografische Verteilung von Möglichkeiten (z.B. Redmond, WA hat 438 offene Stellen)
- Einstellungstrends und Schwerpunkte von Unternehmen
3. Karrierewegplanung / Die strukturierten Jobtiteldaten können genutzt werden, um:
- Karriereentwicklungswege zu kartieren
- Erforderliche Fähigkeiten für den Aufstieg zu identifizieren
- Rollen über Unternehmen hinweg zu vergleichen (z.B. Senior Program Manager vs. Projektmanager-Positionen)
4. Analyse der Unternehmenskultur / Mit den Bewertungs- und Ratingdaten:
- Arbeitszufriedenheit analysieren (Microsofts Gesamtbewertung von 4,2)
- Work-Life-Balance über Unternehmen hinweg vergleichen
- Unternehmenswerte und Mitarbeitererfahrungen bewerten
5. Vorbereitung auf Vorstellungsgespräche / Die Interviewdaten liefern:
- Einblicke in die Dauer des Prozesses ("etwa zwei Wochen")
- Schwierigkeitsgrade (als "MITTEL" eingestuft)
- Häufige Interviewfragen und -erfahrungen für einen Job
- Standortbezogenes Interview-Feedback
6. Wettbewerbsintelligenz / Unternehmen können:
- Einstellungsmuster von Konkurrenten überwachen
- Leistungen und Vergütungen für einen Job vergleichen
- Expansion in neue Märkte oder Technologien verfolgen
- Ähnliche Unternehmen in ihrem Sektor analysieren
Diese Daten können besonders wertvoll für HR-Profis, Arbeitssuchende und Business-Analysten sein, die datengetriebene Entscheidungen über Beschäftigung und Arbeitsmarkttrends treffen möchten.
Methode 5: Nutzung von Google-Cache-Alternativen
Während Google keinen Zugriff mehr auf zwischengespeicherte Seiten bietet, können Sie dennoch archivierte Versionen vieler Websites über Dienste wie WebCite und das Internet Archive einsehen. Diese Seiten bieten Schnappschüsse von Webseiten, sodass Sie auf Inhalte von geschützten Websites zugreifen können, ohne deren Domain direkt zu besuchen oder Cloudflares CDN zu durchlaufen.
Um Archive zu nutzen, wenn andere Methoden scheitern, folgen Sie diesen Schritten:
- Verfügbarkeit und Aktualität der Daten prüfen: Stellen Sie sicher, dass archivierte Daten vorhanden und aktuell genug sind, um Ihren Anforderungen zu entsprechen. Die Relevanzbewertung ist entscheidend.
- Sicherheitsniveau bewerten: Überlegen Sie, ob die Sicherheit des Archivs geringer ist als die der Originalseite. Dies könnte die Sicherheit und Integrität der extrahierten Daten beeinflussen.
Wenn diese Bedingungen erfüllt sind, durchsuchen Sie das Archiv der Zielseite, um zu sehen, ob eine zwischengespeicherte Version zugänglich ist.
Methode 6: Jobtitel für Entwicklerpositionen mit Python scrapen
Wenn Sie den Prozess der Abfrage von Jobtitel-Vorschlägen im Zusammenhang mit "Entwickler" automatisieren möchten, können Sie ein einfaches Skript verwenden, um mit dem Indeed-Endpunkt für Autovervollständigungsvorschläge zu interagieren. Dies kann Ihnen helfen, eine Liste relevanter Titel zu sammeln, die häufig mit Entwicklerrollen in Verbindung gebracht werden, und Einblicke in ähnliche oder verwandte Positionen zu geben.
Sie können das folgende Python-Skript verwenden, um den Text zu scrapen und zu parsen, wobei nur die relevanten Jobtitel-Vorschläge extrahiert werden:
import httpx
def get_job_title_suggestions(query="cto"):
url = "https://autocomplete.indeed.com/api/v0/suggestions/cmp-what-with-top-companies"
params = {
"country": "US",
"language": "en",
"count": 10,
"counts": 10,
"formatted": 1,
"query": query
}
response = httpx.get(url, params=params)
if response.status_code == 200:
suggestions = [item['suggestion'] for item in response.json() if item['suggestion'] != 'null']
return suggestions
else:
return []
# Abrufen von CTO-bezogenen Jobtiteln
cto_suggestions = get_job_title_suggestions("cto")
print(cto_suggestions)
Dieses Skript sendet eine HTTP-Anfrage an die Indeed-API und gibt eine Liste von vorgeschlagenen Jobtiteln aus, die sich auf "Entwickler" beziehen. Dieser Indeed-Endpunkt ist derzeit nicht durch Cloudflare geschützt, könnte es aber in Zukunft werden.
Hinweis: Es ist auch möglich, denselben Ansatz zu verwenden, um Standortvorschläge von Indeed abzurufen und so eine Liste relevanter Städte zu erhalten. Dies kann besonders nützlich sein, wenn Sie eine Webanwendung entwickeln, um zu verhindern, dass der Client keine Ergebnisse erhält, indem Suchfelder mit gültigen Optionen gefüllt werden.
Erlaubt Indeed das Scrapen von Jobs?
Die Legalität des Datenscrapings wird durch Urheberrecht und Datenschutzgesetze geregelt. Der Code de la propriété intellectuelle regelt die Datenextraktion in Bezug auf Nutzung, Menge und Absicht. Hier ist eine Zusammenfassung dessen, was im Allgemeinen erlaubt ist:
- Nicht-substantielle Datenextraktion: Das Extrahieren eines kleinen, nicht-substantiellen Teils öffentlich zugänglicher Daten für den privaten Gebrauch ist in der Regel erlaubt. Dieser Ansatz stellt sicher, dass Nutzer nur minimale Daten sammeln, die den Wert der Datenbank nicht beeinträchtigen.
- Privater, nicht-kommerzieller Gebrauch: Das Extrahieren von Daten in größerem Umfang könnte akzeptabel sein, wenn es für persönliche, nicht-kommerzielle Zwecke erfolgt. Allerdings müssen alle Urheberrechte und Datenschutzrechte respektiert werden.
- Akademische und Forschungsnutzung: Für Bildungs- oder Forschungszwecke darf eine größere Menge an Daten extrahiert werden. Diese Nutzung ist in der Regel nicht-kommerziell und richtet sich an ein begrenztes Publikum, wie Studenten oder Forscher, was das Risiko einer Verletzung der Plattformbedingungen minimiert.
Einhaltung der Nutzungsbedingungen von Indeed
Indeed's Nutzungsbedingungen verbieten ausdrücklich Scraping-Aktivitäten für kommerzielle Zwecke ohne Genehmigung. Sie beschränken die Nutzung von „Bots, Skripten oder APIs“, um Daten von ihrer Website zu scrapen, insbesondere wenn die Daten für Wettbewerbszwecke, Profiling oder Massen-Datensammlung verwendet werden.
Beispielklausel: "Sie erklären sich damit einverstanden, keine Roboter, Spider, Scraper oder andere automatisierte Mittel zu verwenden, um auf die Indeed-Website für irgendeinen Zweck ohne die ausdrückliche schriftliche Genehmigung von Indeed zuzugreifen."
Verstöße gegen diese Bedingungen können rechtliche Schritte und hohe Geldstrafen nach sich ziehen. Indeed behält sich das Recht vor, Schadensersatz für durch unautorisiertes Scraping verursachte Schäden zu verlangen, was zu erheblichen finanziellen und reputativen Verlusten für das betreffende Unternehmen führen kann.
Kann ich die Indeed-API nutzen, um Stellenangebote zu scrapen?
Seit Juni 2023 bietet Indeed eine Reihe von APIs für Entwickler kostenlos an. Diese APIs sind jedoch hauptsächlich für die Einstellungsseite der Plattform gedacht. Sie sind nützlich für die Integration von Indeed in Bewerber-Tracking-Systeme, das Verfolgen von Bewerberkonversionen oder das Planen von Interviews, aber sie sind nicht für die Stellensuche konzipiert.
Früher war die Publisher Jobs API (einschließlich der Funktionen Get Job und Job Search) speziell für die Stellensuche verfügbar und ermöglichte es Nutzern, Daten wie Jobtitel, Unternehmensnamen, Beschreibungstexte, Standorte und Veröffentlichungszeiten zu sammeln. Da diese APIs eingestellt wurden, haben sich Nutzer Alternativen wie einem Indeed-Scraper zugewandt, um ähnliche Stellensuchdaten zu erhalten.
Fazit
Zusammenfassend ermöglicht das Datenscraping auf Indeed den Zugriff auf eine Fülle wertvoller Informationen, darunter Jobs, Unternehmen, Standorte und andere nützliche Details. Durch die beschriebenen Methoden, einschließlich der Nutzung von Scraping-APIs wie Piloterr, ist es möglich, Text-Daten von einer einfachen URL zu extrahieren und dabei Schutzmaßnahmen wie Cloudflare zu umgehen. Dieser Ansatz bietet Unternehmen entscheidende Einblicke zur Verbesserung von Rekrutierungsstrategien, Wettbewerbsanalysen und Markttrendstudien. Es ist jedoch entscheidend, die Nutzungsbedingungen von Indeed einzuhalten, um eine rechtmäßige Nutzung dieser Daten zu gewährleisten.