Erfahren Sie, wie Sie Amazon mit User-Agent-Headern scrapen, um die Erkennung zu vermeiden, und BeautifulSoup verwenden, um HTML-Inhalte zu parsen. Dieser umfassende Leitfaden enthält auch ein vollständiges Anwendungsbeispiel, das den Prozess der Extraktion von Produktinformationen wie Titeln, Preisen und Bewertungen mit Python demonstriert.
Überspringen Sie die Wartung: Verwenden Sie die Amazon Scraping API oder die Amazon Product API für strukturierte JSON-Ausgabe.
Einführung in Web Scraping
Was ist Web Scraping?
Web Scraping ist eine Methode, die verwendet wird, um große Mengen an Inhalten von Websites automatisch zu extrahieren. Das Hauptziel des Web Scrapings besteht darin, Informationen aus dem Web zu sammeln und zu strukturieren, die dann für verschiedene Anwendungen genutzt werden können. Dieser Inhalt kann Texte, Bilder, Videos und andere Formen von Medien umfassen, die auf Webseiten verfügbar sind. Durch die Automatisierung des Extraktionsprozesses ermöglicht Web Scraping den Nutzern, Webinhalte schnell zu lesen, zu durchsuchen und zu analysieren, was im Vergleich zur manuellen Datensammlung erhebliche Zeit und Mühe spart.
Tools und Techniken
Mehrere Tools und Techniken werden beim Web Scraping eingesetzt, um eine effiziente Datensammlung zu gewährleisten:
- HTML Parsing: Diese Technik beinhaltet die Analyse der Struktur einer Webseite, um Informationen zu sammeln. Tools wie ein Python-Scraper und Cheerio (JavaScript) werden häufig für diesen Zweck verwendet. Sie ermöglichen das Navigieren durch die Seitenstruktur und das Abrufen relevanter Details basierend auf Tags, Attributen und anderen Elementen.
- DOM Parsing: Document Object Model (DOM) Parsing beinhaltet die Interaktion mit der DOM-Struktur einer Webseite, um Daten zu sammeln. JavaScript-Bibliotheken wie jQuery erleichtern diesen Prozess, indem sie die Manipulation und Abfrage des DOM ermöglichen, um spezifische Informationen abzurufen.
- Proxy-Nutzung: Viele Websites implementieren Maßnahmen, um den Zugriff basierend auf IP-Adressen zu begrenzen. Durch die Nutzung von Proxys kann man diese Beschränkungen umgehen und auf die benötigten URLs zugreifen, ohne blockiert zu werden. Diese Methode ist oft zuverlässiger und effizienter.
- Headless Browser: Tools wie Puppeteer und Selenium simulieren Interaktionen mit Webseiten, indem sie diese in einem Headless Browser rendern. Dieser Ansatz ermöglicht das Navigieren durch komplexe Webseiten, das Verarbeiten von JavaScript und das Sammeln von Daten, als würde man manuell browsen.
- Reguläre Ausdrücke: Reguläre Ausdrücke (Regex) können verwendet werden, um Muster im Webseiteninhalt zu identifizieren und Informationen entsprechend zu sammeln. Diese Technik ist nützlich für spezifische Aufgaben, bei denen der Inhalt einem vorhersehbaren Muster folgt.
Rechtlicher Hinweis und Vorsichtsmaßnahmen
Dieses Tutorial behandelt gängige Web-Scraping-Techniken zu Bildungszwecken. Die Interaktion mit öffentlichen Servern erfordert Sorgfalt und Respekt, und hier ist eine gute Zusammenfassung dessen, was nicht zu tun ist:
- Scrapen Sie nicht in einem Tempo, das die Website beschädigen könnte.
- Scrapen Sie keine Bewertungen oder Texte, die nicht öffentlich zugänglich sind.
- Speichern Sie keine personenbezogenen Daten (PII) von EU-Bürgern, die durch die DSGVO geschützt sind.
- Verwenden Sie keine vollständigen öffentlichen Datensätze erneut, da dies in einigen Ländern illegal sein kann.
Wenn Sie Inhalte durchsuchen oder lesen, stellen Sie sicher, dass Sie ethische Richtlinien und rechtliche Überlegungen befolgen. Für detailliertere Anleitungen sollten Sie einen Anwalt konsultieren.
Warum Amazon-Produkte scrapen?
Das Scrapen von Amazon bietet mehrere bedeutende Vorteile für Unternehmen, Forscher und Einzelpersonen:
- Wettbewerbsanalyse: Durch die Nutzung eines Scrapers zur Sammlung von Informationen von Amazon können Unternehmen Wettbewerbsbeschreibungen lesen, Kundenbewertungen einsehen und die Verfügbarkeit von Artikeln verfolgen. Dies hilft bei der Entwicklung wettbewerbsfähiger Strategien und der Anpassung der eigenen Angebote, um im Markt führend zu bleiben.
- Marktforschung: Das Scrapen von Amazon ermöglicht es Unternehmen, nach Verbrauchertrends, Vorlieben und Kaufverhalten zu suchen. Diese Informationen helfen dabei, beliebte Artikel zu identifizieren, Kundenbedürfnisse zu verstehen und fundierte Entscheidungen über Entwicklung und Marketingstrategien zu treffen.
- Preisüberwachung: Händler und Verbraucher können Scraping nutzen, um Preisänderungen im Laufe der Zeit zu verfolgen. Dies ist besonders nützlich für dynamische Preisstrategien, bei denen Unternehmen die Preise basierend auf Wettbewerbsaktivitäten und Marktnachfrage anpassen.
- Datenaggregation: Unternehmen, die auf mehreren Plattformen verkaufen, können einen Scraper nutzen, um ihre Inhalte zu aggregieren und die Konsistenz über alle Kanäle hinweg sicherzustellen. Dies hilft, genaue Angebote zu verwalten, den Bestand zu kontrollieren und Abläufe zu optimieren.
- Analyse der Kundenzufriedenheit: Durch die Analyse von Kundenbewertungen und -bewertungen können Unternehmen Einblicke in die Kundenzufriedenheit und Produktleistung gewinnen. Diese Informationen können genutzt werden, um Angebote zu verbessern, häufige Probleme zu beheben und den Kundenservice zu optimieren.
- Lead-Generierung: Das Scrapen von Amazon kann helfen, potenzielle Leads und Möglichkeiten für Partnerschaften oder Verkäufe zu identifizieren. Zum Beispiel können Unternehmen nach Wiederverkäufern, Lieferanten oder Influencern suchen, die in ihrer Branche aktiv sind.
Insgesamt ist die Fähigkeit, Daten von Amazon zu lesen und zu scrapen, eine wertvolle Ressource, die bei strategischen Entscheidungen hilft und die betriebliche Effizienz verbessert.## Erstellen eines grundlegenden Amazon-Scrapers
Verwendung von requests zum Abrufen von Amazon-URLs
Einrichten des User-Agents
Beim Scrapen von Websites ist es wichtig, einen User-Agent einzurichten, um eine echte Browseranfrage zu imitieren. Dies hilft, Blockierungen zu vermeiden und die korrekte Antwort vom Server zu erhalten. In Python können Sie die requests-Bibliothek verwenden, um einen User-Agent einzurichten. Hier ist ein Beispiel:
import requests
import random
# Liste der User-Agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 10; SM-G960F)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Mobile Safari/537.36'
]
# Einen zufälligen User-Agent auswählen
headers = {
'User-Agent': random.choice(user_agents)
}
url = 'https://www.amazon.com/dp/B0B72B7GM2' # Beispiel-Produkt-URL
# Eine GET-Anfrage an die angegebene URL mit den gewählten Headers senden
response = requests.get(url, headers=headers)
# Den Statuscode der Antwort ausgeben
print(response.status_code)
In diesem Beispiel wird der User-Agent-String so gesetzt, dass er einen gängigen Webbrowser imitiert, wodurch es weniger wahrscheinlich ist, dass die Anfrage von Amazons Servern blockiert wird.
Abrufen des HTML-Inhalts
Sobald die Anfrage gestellt wurde, besteht der nächste Schritt darin, den Inhalt der Webseite abzurufen. Dies kann mit dem von der requests.get-Anfrage erhaltenen Antwortobjekt erfolgen. Hier ist, wie Sie den Inhalt abrufen und ausgeben können:
if response.status_code == 200:
html_content = response.text
print(html_content)
else:
print(f"Fehler beim Abrufen der Webseite. Statuscode: {response.status_code}")
Dieser Code überprüft, ob die Anfrage erfolgreich war (Statuscode 200) und ruft dann den HTML-Inhalt als Textstring ab.
Parsen von HTML mit BeautifulSoup
Was ist BeautifulSoup?
BeautifulSoup ist eine beliebte Python-Bibliothek, die für Web-Scraping und das Parsen von XML-Dokumenten entwickelt wurde. Sie ermöglicht es einem Scraper, die Struktur einer Webseite einfach zu navigieren und zu manipulieren, was die Extraktion von Inhalten vereinfacht. BeautifulSoup nimmt den Quellcode der Seite und erstellt einen Parse-Baum, der dann durchsucht und modifiziert werden kann, um relevante Texte oder Informationen zu extrahieren. Sie ist besonders nützlich für das Scrapen von schlecht formatiertem oder inkonsistentem Markup. Durch die Verwendung von BeautifulSoup in Python können Entwickler effizient Inhalte von Websites scrapen, den Prozess der Sammlung und Organisation von Informationen aus dem Web automatisieren und so ein leistungsstarkes Werkzeug für jeden Scraper darstellen.
Warum BeautifulSoup verwenden?
BeautifulSoup besteht aus verschiedenen Parsing-Tools wie soup, lxml und HTML5lib. Diese Flexibilität ermöglicht es Ihnen, verschiedene Parsing-Methoden auszuprobieren und von ihren Vorteilen je nach Situation zu profitieren. Einer der Hauptgründe für die Verwendung von BeautifulSoup ist seine Benutzerfreundlichkeit. Es sind nur wenige Zeilen in Python erforderlich, um einen Scraper zu erstellen, der effizient Inhalte von Webseiten scrapen kann. Trotz seiner Einfachheit ist es robust und zuverlässig, was es nicht nur bei Entwicklern, sondern auch bei allen, die mit Web-Scraping arbeiten, beliebt macht.
Mit seiner klaren und umfassenden Dokumentation hilft BeautifulSoup Scrapern, schnell zu lernen und Probleme effektiv zu lösen. Zusätzlich bietet eine aktive Online-Community verschiedene Lösungen für Herausforderungen, denen Sie beim Scrapen begegnen können, was es zu einem großartigen Werkzeug für Anfänger und Experten gleichermaßen macht.
Produktname und Preis finden
Um den HTML-Inhalt zu parsen und spezifische Informationen wie den Produktnamen und den Wert zu extrahieren, können Sie die BeautifulSoup-Bibliothek verwenden.
BeautifulSoup ist eine leistungsstarke und einfach zu bedienende Python-Bibliothek zum Extrahieren von Daten aus HTML- und XML-Dateien. Sie ermöglicht es Benutzern, Webseiteninhalte effizient zu navigieren, zu durchsuchen und zu modifizieren, während sie die Einfachheit dieser 'Suppe' von Parsing-Tools genießen.
Hier ist ein Beispiel, wie Sie diese Details extrahieren können:
Lassen Sie uns die Struktur der Produktdetailseite untersuchen.
Öffnen Sie eine Produkt-URL, wie z.B. https://www.amazon.com/dp/B0B72B7GM2, in Chrome oder einem anderen modernen Browser, klicken Sie mit der rechten Maustaste auf den Produktnamen und wählen Sie „Untersuchen“.
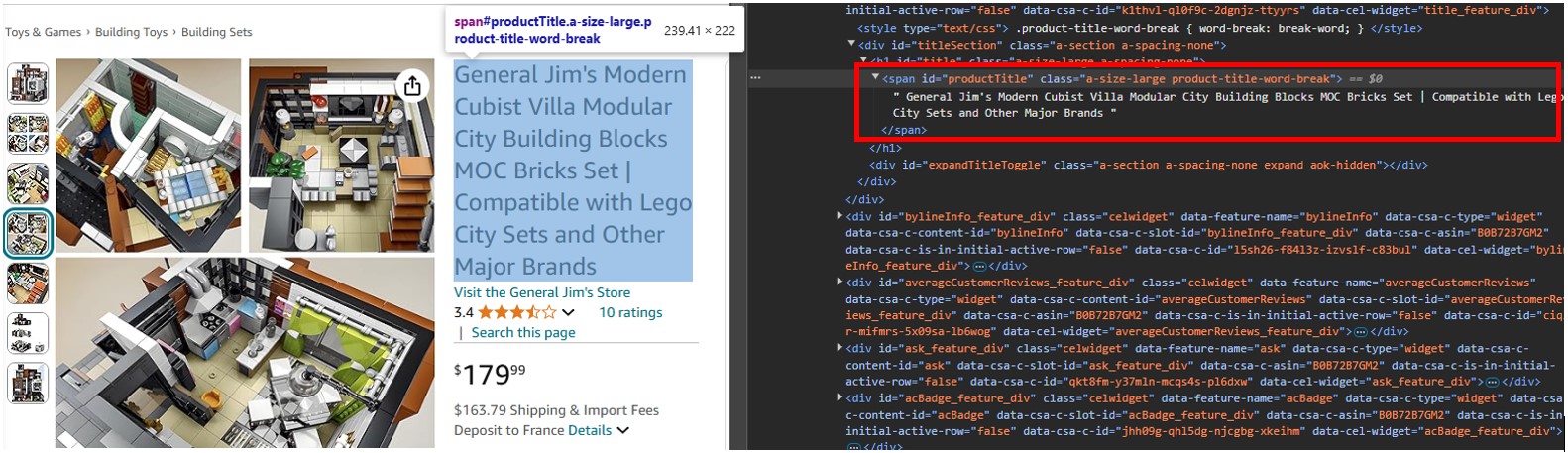
Sie werden sehen, dass es sich um ein span-Tag mit dem id-Attribut „productTitle“ handelt. Wenn Sie mit der rechten Maustaste auf das Element klicken und „Untersuchen“ wählen, sehen Sie das Markup des Inhalts, das der Scraper lesen wird und das es Ihnen ermöglicht, nach spezifischen Details zu suchen.
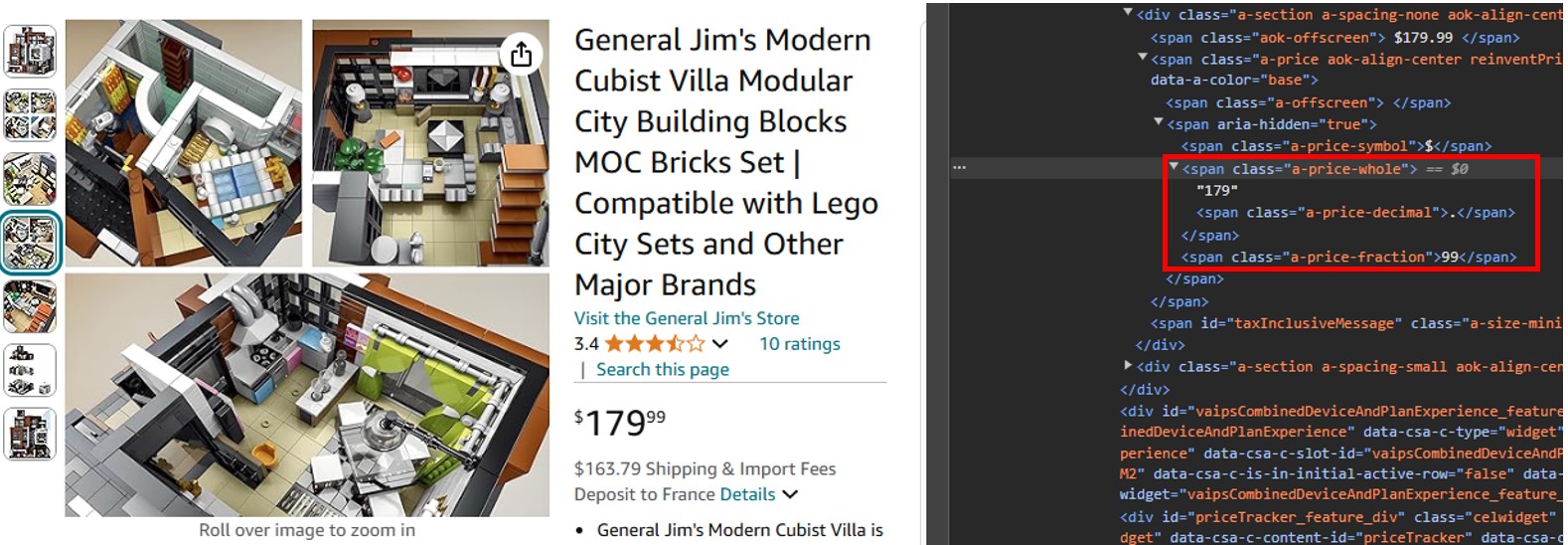
Sie können sehen, dass der Dollar-Anteil des Preises in einem span-Tag mit der Klasse „a-price-whole“ steht und der Cent-Anteil in einem anderen span-Tag mit der Klasse „a-price-fraction“.
Ebenso können Sie Bewertung, Bild und Beschreibung lokalisieren.
Sobald Sie diese Informationen haben, können wir unseren Code mit BeautifulSoup einrichten:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Den Titel finden
title_tag = soup.find('span', {'id': 'productTitle'})
product_title = title_tag.get_text(strip=True) if title_tag else 'Titel nicht gefunden'
price_tag = soup.find('span', {'class': 'a-offscreen'})
product_price = price_tag.get_text(strip=True) if price_tag else 'Preis nicht gefunden'
print(f"Titel: {product_title}")
print(f"Preis: {product_price}")
In diesem Beispiel wird BeautifulSoup verwendet, um den HTML-Inhalt zu parsen und die Tags zu finden, die den Produktnamen und den Preis enthalten. Die Methode get_text(strip=True) wird verwendet, um den Textinhalt zu extrahieren und führende oder nachfolgende Leerzeichen zu entfernen.
Extrahieren von Kundenbewertungen und -bewertungen
Um Kundenbewertungen und -bewertungen zu extrahieren, müssen Sie die relevanten HTML-Tags und -Klassen finden. Hier ist ein Beispiel:
# Kundenbewertungen finden
reviews = []
review_tags = soup.find_all('span', {'data-hook': 'review-body'})
for tag in review_tags:
review_text = tag.get_text(strip=True)
reviews.append(review_text)
# Kundenbewertungen finden
ratings = []
rating_tags = soup.find_all('i', {'data-hook': 'review-star-rating'})
for tag in rating_tags:
rating_text = tag.get_text(strip=True)
ratings.append(rating_text)
print(f"Kundenbewertungen: {reviews}")
print(f"Kundenbewertungen: {ratings}")
In diesem Code wird find_all verwendet, um alle Instanzen von Bewertungstexten und -bewertungen zu lokalisieren. Der Textinhalt jeder Bewertung und Bewertung wird extrahiert und in Listen gespeichert.
Durch die Kombination dieser Schritte können Sie einen grundlegenden Amazon-Scraper erstellen, der Produktdetails, Kundenbewertungen und -bewertungen abruft. Denken Sie daran, Fehler zu behandeln und die Nutzungsbedingungen von Amazon zu respektieren, um mögliche rechtliche Probleme zu vermeiden.
Überarbeitung des finalen Skripts
Um Amazon-Produktseiten zu scrapen, verwenden wir die requests-Bibliothek von Python, um URLs abzurufen, und BeautifulSoup, um HTML-Inhalte zu parsen. Hier ist das endgültige konsolidierte Skript, das diese Prozesse demonstriert:
import requests
import random
from bs4 import BeautifulSoup
# Liste der User-Agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 10; SM-G960F)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Mobile Safari/537.36'
]
# Einen zufälligen User-Agent auswählen
headers = {
'User-Agent': random.choice(user_agents)
}
# Beispiel-Produkt-URL
url = 'https://www.amazon.com/dp/B0B72B7GM2'
# Eine GET-Anfrage an die angegebene URL mit den gewählten Headers senden
response = requests.get(url, headers=headers)
# Überprüfen, ob die Anfrage erfolgreich war
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
# Den Titel finden
title_tag = soup.find('span', {'id': 'productTitle'})
product_title = title_tag.get_text(strip=True) if title_tag else 'Titel nicht gefunden'
# Den Preis finden
price_tag = soup.find('span', {'class': 'a-offscreen'})
product_price = price_tag.get_text(strip=True) if price_tag else 'Preis nicht gefunden'
# Kundenbewertungen finden
reviews = []
review_tags = soup.find_all('span', {'data-hook': 'review-body'})
for tag in review_tags:
review_text = tag.get_text(strip=True)
reviews.append(review_text)
# Kundenbewertungen finden
ratings = []
rating_tags = soup.find_all('i', {'data-hook': 'review-star-rating'})
for tag in rating_tags:
rating_text = tag.get_text(strip=True)
ratings.append(rating_text)
print(f"Titel: {product_title}")
print(f"Preis: {product_price}")
print(f"Kundenbewertungen: {reviews}")
print(f"Kundenbewertungen: {ratings}")
else:
print(f"Fehler beim Abrufen der Webseite. Statuscode: {response.status_code}")

In diesem Kapitel werden wir fortgeschrittene Techniken zum Scrapen von Amazon erkunden. Diese leistungsstarken Werkzeuge, die Python nutzen, spezialisieren sich auf die Datenabfrage von URLs und sparen Zeit und Geld, während sie Web-Scraping für jeden zugänglich machen.
Warum eine Web-Scraping-Software verwenden?
Die Fähigkeit, Inhalte aus dem Internet zu scrapen, zu sammeln und zu analysieren, ist mit einem Scraper zu einer entscheidenden Fähigkeit für Unternehmen und Forscher gleichermaßen geworden. Hier macht Web-Scraping-Software, insbesondere mit Python, einen erheblichen Unterschied in Ihrer Fähigkeit, relevante Informationen zu suchen und abzurufen.
Reduziertes Risiko der Erkennung und Blockierung
Eine der Herausforderungen beim Erstellen eines benutzerdefinierten Scrapers ist das Risiko, von Websites erkannt und blockiert zu werden. Websites haben oft Sicherheitsmaßnahmen wie Ratenbegrenzung oder IP-Blockierung, um Scraping zu verhindern. Die Verwendung von Experten-Web-Scraping-Software mit Python reduziert jedoch das Risiko der Erkennung erheblich. Diese Tools sind darauf ausgelegt, ausgeklügelte Anti-Scraping-Mechanismen zu handhaben, wie z.B. das Rotieren von IP-Adressen, das Nachahmen von menschlichem Verhalten und das Verwalten von Anfrageintervallen, um das Auslösen von Sicherheitssystemen zu vermeiden.
Zugang zu großen Datenmengen
Das Internet ist eine Schatztruhe an Informationen, aber das manuelle Scrapen von Websites kann zeitaufwendig und unpraktisch sein. Ein Scraper, der Python verwendet, automatisiert diesen Prozess und ermöglicht es Benutzern, große Datenmengen schnell und effizient zu scrapen. Ob für Marktforschung, Wettbewerbsanalyse oder akademische Studien – Web-Scraping kann Informationen sammeln, die sonst Tage oder Wochen in Anspruch nehmen würden.
Skalierbarkeit
Mit dem Wachstum von Unternehmen steigt auch ihr Bedarf, mehr Informationen zu scrapen. Ein Scraper, der Python verwendet, ist hoch skalierbar und in der Lage, zunehmende Datenmengen ohne Leistungsverlust zu verarbeiten. Diese Skalierbarkeit macht Web-Scraping zu einer idealen Lösung für Unternehmen jeder Größe, von Startups bis zu großen Unternehmen.
Warum die Piloterr API für Amazon-Scraping verwenden?
Der Piloterr-Scraper hebt sich als leistungsstarkes Werkzeug für das Scrapen von Amazon-Produktdaten hervor. Hier sind mehrere Gründe, warum Sie die Piloterr-Lösung für Ihre Amazon-Scraping-Bedürfnisse in Betracht ziehen sollten:
- Privater Proxy: Piloterr verwendet eigene private Proxies, um sicherzustellen, dass Ihre Anfragen über mehrere IP-Adressen verteilt werden (IP-Rotation). Dies reduziert die Wahrscheinlichkeit, von Amazon blockiert zu werden, erheblich und ermöglicht es Ihnen, Daten effizient und effektiv zu scrapen. Unsere robuste Infrastruktur ist mit Python aufgebaut und darauf ausgelegt, große Anfragevolumina zu bewältigen, während eine hohe Erfolgsrate aufrechterhalten wird.
- Umfassender Bibliothekszugang mit einem einzigen Abonnement: Einer der überzeugendsten Gründe, Piloterr zu wählen, ist das durch unser Abonnementmodell gebotene Preis-Leistungs-Verhältnis. Mit einem einzigen Abonnement erhalten Sie Zugang zu unseren API-Endpunkten Bibliothek und Scraping-Ressourcen. Dies umfasst nicht nur den Amazon-Scraper, sondern auch andere Scraping-Lösungen für verschiedene Websites und Datenquellen. Dieser umfassende Zugang stellt sicher, dass Sie die Werkzeuge haben, die Sie für jedes Scraping-Projekt benötigen, alles an einem Ort.
Mit Piloterr können Sie einfach nach den notwendigen Informationen auf Amazon und anderen Plattformen suchen, lesen und diese abrufen, was Ihnen einen leistungsstarken Vorteil bei Ihren Datensammlungsbemühungen verschafft.
Erstellen Sie Ihr Konto
- Registrieren Sie sich auf piloterr.com
- Erstellen Sie Ihr Abonnement (50 kostenlose Credits bei der Registrierung)
- Erstellen und kopieren Sie Ihren API-Schlüssel
Fallstudie: Amazon scrapen
Hier ist ein praktisches Beispiel, wie man mit Python den Titel und andere relevante Details eines Amazon-Artikels von seiner URL scrapen kann. Ein Scraper wird verwendet, um die notwendigen Informationen effizient abzurufen.
Grundlegender Python-Code
Vergessen Sie nicht, PILOTERR_API_KEY durch Ihren echten API-Schlüssel zu ersetzen. Das Skript geht davon aus, dass die Piloterr-API-Antworten in einem für unsere API spezifischen Format vorliegen, daher muss es möglicherweise angepasst werden, abhängig vom Anbieter Ihrer Wahl.
- Kopieren Sie den Code
- Erstellen Sie eine neue Datei
get_amazon_product.py - Ersetzen Sie den API-Token durch Ihren eigenen
- Ersetzen Sie die Variablen
JOB_TITLE&LOCATIONdurch Ihre Anforderungen - Führen Sie das Skript mit
python get_amazon_product.pyaus
import requests
PILOTERR_API_KEY = 'YOUR-API-KEY-HERE'
LIST_ASIN_AMAZON_PRODUCT = [
"B0CN78FNTY",
"B09JGLMDLZ",
"B09VZ3ZQWQ",
"B0B72B7GM2"
]
def get_amazon_product_info(url: str):
amazon_api_url = "https://piloterr.com/api/v2/amazon/product"
headers = {
"x-api-key": PILOTERR_API_KEY
}
data = {
"query": url,
"domain": "com"
}
response = requests.get(
url=amazon_api_url,
headers=headers,
params=data # Verwendung von params statt json für GET-Anfrage
)
if response.status_code == 200:
return response.json()
else:
print(f"Fehler: Suche konnte nicht durchgeführt werden. Statuscode: {response.status_code}")
return None
def extract_product_data(json_data):
product_data = {
"url": json_data.get("url"),
"asin": json_data.get("asin"),
"price": json_data.get("price"),
"stock": json_data.get("stock"),
"title": json_data.get("title")
}
return product_data
def process_amazon_products(url_list):
all_product_data = []
for url in url_list:
product_info = get_amazon_product_info(url)
if product_info:
extracted_data = extract_product_data(product_info)
all_product_data.append(extracted_data)
return all_product_data
# Verwendung
if __name__ == "__main__":
products_data = process_amazon_products(LIST_ASIN_AMAZON_PRODUCT)
print(products_data)
Python-Erklärung
- Importe: Der Code importiert die
requests-Bibliothek, um HTTP-Anfragen zu stellen. - API-Schlüssel und Produktliste: Er definiert eine Konstante
PILOTERR_API_KEYfür die API-Authentifizierung und eine ListeLIST_ASIN_AMAZON_PRODUCT, die ASINs (Amazon Standard Identification Numbers) der abzufragenden Produkte enthält. - Funktion
get_amazon_product_info(url: str):- Erstellt eine Anfrage an die Piloterr-API, um Produktinformationen abzurufen.
- Setzt die Anfrage-Header mit dem API-Schlüssel und Parametern für die Produktsuche.
- Wenn der Antwortstatus 200 (OK) ist, gibt sie die JSON-Daten zurück; andernfalls wird eine Fehlermeldung ausgegeben.
- Funktion
extract_product_data(json_data):- Extrahiert spezifische Felder (
url,asin,price,stockundtitle) aus den von der API zurückgegebenen JSON-Daten und gibt sie in einem Dictionary zurück.
- Extrahiert spezifische Felder (
- Funktion
process_amazon_products(url_list):- Durchläuft eine Liste von Produkt-URLs (ASINs), ruft Produktinformationen mit
get_amazon_product_infoab und extrahiert relevante Daten mitextract_product_data. - Sie kompiliert alle extrahierten Produktdaten in eine Liste und gibt sie zurück.
- Durchläuft eine Liste von Produkt-URLs (ASINs), ruft Produktinformationen mit
Weitere Anwendungsfälle
- Bestseller-Artikel abrufen: Verwenden Sie die API, um Daten zu den meistverkauften Produkten in einer bestimmten Kategorie oder insgesamt zu sammeln. Dies könnte helfen, trendige Artikel basierend auf der Verkaufsleistung zu identifizieren.
- Sterne analysieren: Scrapen Sie Produktinformationen, einschließlich Sternebewertungen. Dies ermöglicht es Benutzern, Produkte basierend auf der Kundenzufriedenheit zu filtern und hoch bewertete Artikel zu finden.
- Produktbilder extrahieren: Rufen Sie hochwertige Bilder von Artikeln für die Verwendung auf E-Commerce-Websites oder Vergleichsplattformen ab. Dies verbessert die visuelle Attraktivität von Angeboten und hilft Kunden, fundierte Entscheidungen zu treffen.
- Bewertungsaggregator erstellen: Kompilieren Sie Kundenbewertungen und -bewertungen für die besten Artikel in einer bestimmten Nische. Dies kann Verbrauchern helfen, Entscheidungen auf der Grundlage umfassender Rückmeldungen anderer Käufer zu treffen.
Vorsichtsmaßnahmen beim Scrapen auf Amazon
Beim Scrapen von Amazon ist es entscheidend zu bedenken, dass CSS-Selektoren (elem.css()) sich im Laufe der Zeit ändern können, da Amazons Entwickler häufig das CSS der Website aktualisieren. Diese Aktualisierungen können die Struktur verändern und dazu führen, dass Ihre bestehenden CSS-Selektoren fehlschlagen. Um den Wartungsaufwand zu reduzieren, wählen Sie Selektoren für Ihr Element (elem) sorgfältig aus und priorisieren Sie <div>-Elemente mit stabilen Attributen wie id. Durch das Anvisieren von Elementen mit spezifischen id-Attributen verbessern Sie die Widerstandsfähigkeit Ihres Scraping-Skripts gegen CSS-Änderungen.
Fazit
Piloterr ist eine der besten Methoden, um Amazon-Artikel einfach und effizient mit unserem Python-Scraper zu scrapen. Durch die Integration dieser Lösung in Ihren Workflow können Sie Ihren Prozess optimieren und müssen sich nicht mehr um die Verwaltung von Agents oder IP-Adressen kümmern, da alles über unsere Proxies läuft. Egal, ob Sie Daten von URLs für Marktanalysen, Wettbewerbsforschung oder andere Zwecke scrapen, Piloterr ermöglicht es Ihnen, die benötigten Informationen einfach zu suchen, zu lesen und abzurufen. Es ist ein wertvolles Werkzeug, das Sie Ihrem Web-Scraping-Toolkit hinzufügen sollten.