Ensuring high-quality data in web scraping operations is a multifaceted challenge, crucial for reliable analytics and decision-making. As web scraping projects scale, the complexity of validating the correctness and completeness of the scraped data increases, potentially diminishing data quality. This article presents a comprehensive overview of techniques to enhance the integrity of web scraping projects.
Reliable data starts with reliable extraction: explore Scraper APIs and our data quality glossary.
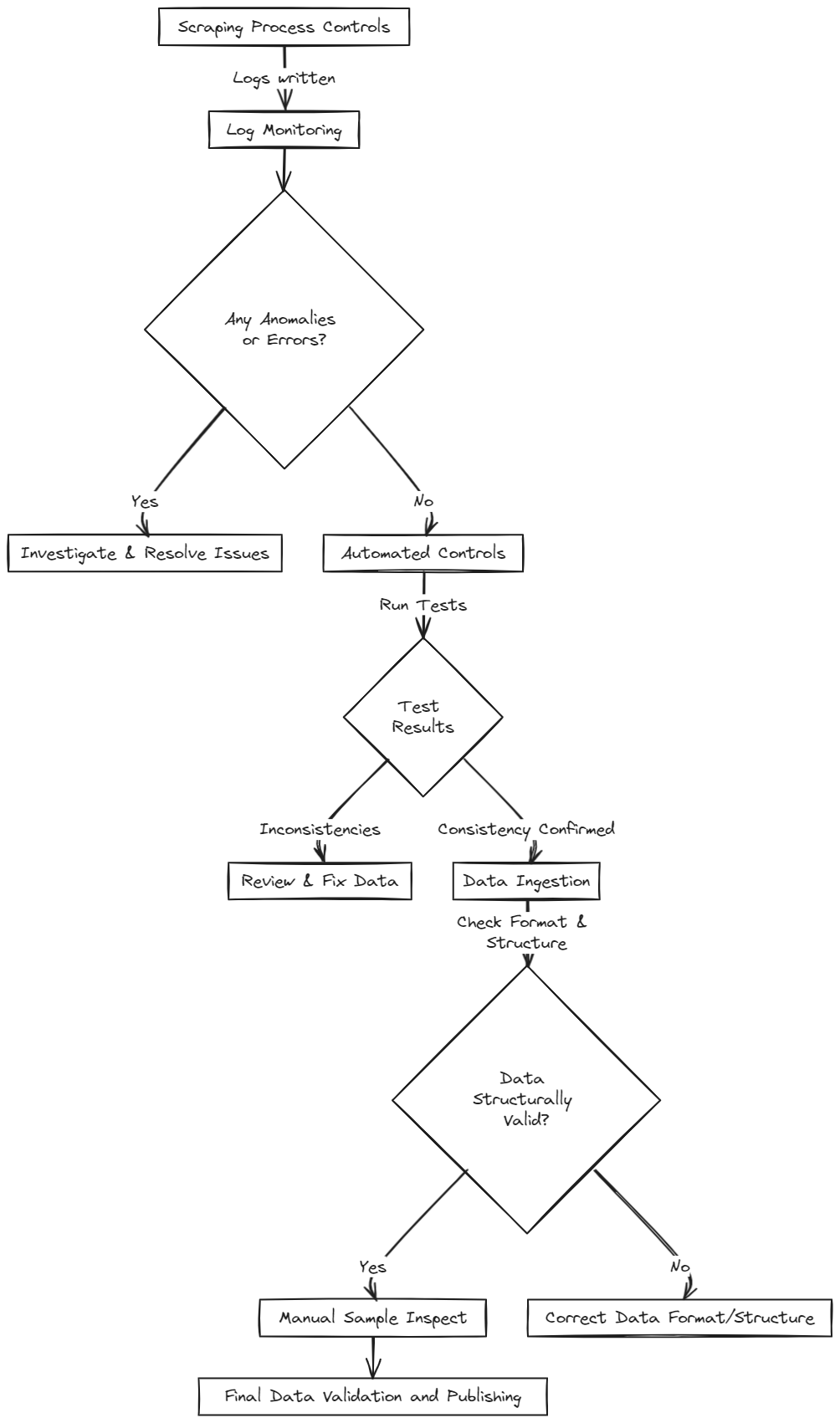
Monitoring the Scraping Process
**Effective data quality management begins with well-designed scrapers that log their activity, highlighting potential issues through HTTP return codes. For example, a 404 error indicates a missing page, possibly due to a broken link or an anti-bot measure, leading to partial or incomplete data. Collecting these logs, like Scrapy, is essential for troubleshooting.
Data Ingestion
**Changes in web page structures can lead to selectors breaking, capturing data in unexpected formats. Implementing checks during database loading offers a centralized point of control to maintain data consistency across multiple scraping sources.
Automatic Data Quality Controls
**Depending on the type of data, various automatic checks can be instituted. Numeric fields, such as product prices, can be automatically validated for coherence, while qualitative data, such as text fields, may require different strategies.
Data Completeness and Coherence
**Data completeness is a fundamental metric, with alerts set up for discrepancies in expected item counts. For example, Retailed.io uses a Ground Truth method, where develpers provide expected item counts, which are peer-reviewed and updated. Significant deviations trigger alerts, pausing data publication until verified.
Qualitative Data Quality
Automated controls have limitations with qualitative fields. While some checks for known domain values or format validations (e.g., email, URLs) are possible, the true validity of content like product descriptions may require manual inspection.
Data Publishing
**Only data that has successfully passed all previous quality checks should be published.